ElasticSearch搜索
1、搜索---最基本的工具
我们可以将一个 JSON 文档扔到 Elasticsearch 里,然后根据 ID 检索。但 Elasticsearch 真正强大之处在于可以从无规律的数据中找出有意义的信息——从“大数据”到“大信息”。
Elasticsearch 不只会存储(stores) 文档,为了能被搜索到也会为文档添加索引(indexes) ,这也是为什么我们使用结构化的 JSON 文档,而不是无结构的二进制数据。
文档中的每个字段都将被索引并且可以被查询 。不仅如此,在简单查询时,Elasticsearch 可以使用 所有(all) 这些索引字段,以惊人的速度返回结果。这是你永远不会考虑用传统数据库去做的一些事情。
搜索(search) 可以做到:
gender 或者 age 这样的字段 上使用结构化查询,join_date 这样的字段上使用排序,就像SQL的结构化查询一样。 很多搜索都是开箱即用的,为了充分挖掘 Elasticsearch 的潜力,你需要理解以下三个概念:
映射(Mapping)
描述数据在每个字段内如何存储
分析(Analysis)
全文是如何处理使之可以被搜索的
领域特定查询语言(Query DSL)
Elasticsearch 中强大灵活的查询语言
测试数据:http://www.cnblogs.com/shaosks/p/7515184.html
2、空搜索
搜索API的最基础的形式是没有指定任何查询的空搜索 ,它简单地返回集群中所有索引下的所有文档:
GET /_search
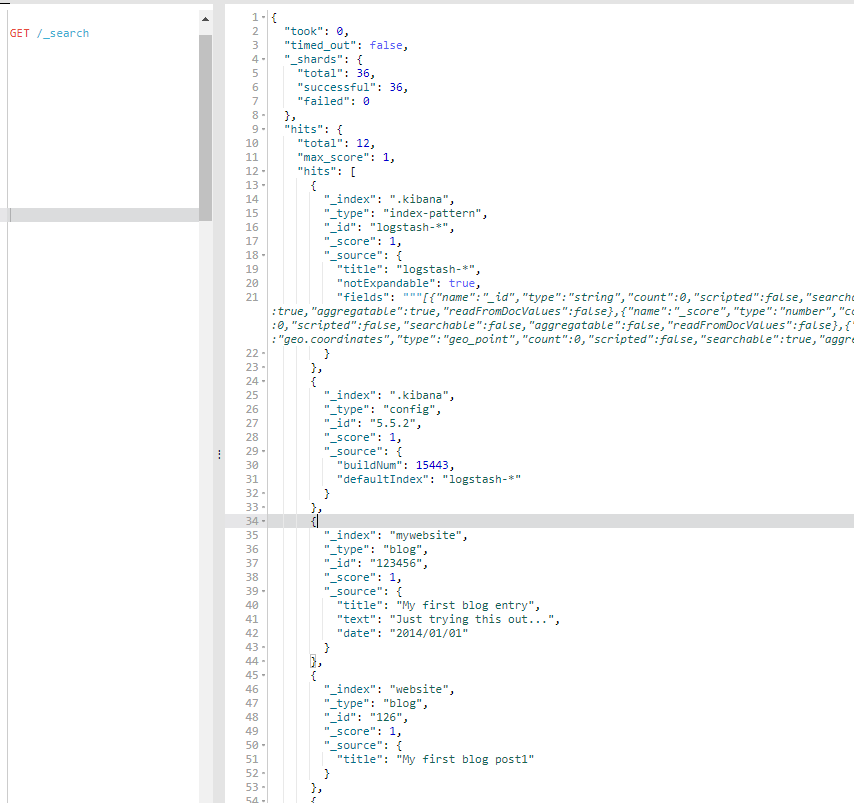
1、hits
返回结果中最重要的部分是 hits ,它 包含 total 字段来表示匹配到的文档总数,并且一个 hits 数组包含所查询结果的前十个文档。
在 hits 数组中每个结果包含文档的 _index 、 _type 、 _id ,加上 _source 字段。这意味着我们可以直接从返回的搜索结果中使用整个文档。这不像其他的搜索引擎,
仅仅返回文档的ID,需要你单独去获取文档。
每个结果还有一个 _score ,它衡量了文档与查询的匹配程度。默认情况下,首先返回最相关的文档结果,就是说,返回的文档是按照 _score 降序排列的。
在这个例子中,我们没有指定任何查询,故所有的文档具有相同的相关性,因此对所有的结果而言 1 是中性的 _score 。
max_score 值是与查询所匹配文档的 _score 的最大值。
2、took
took 值告诉我们执行整个搜索请求耗费了多少毫秒。
3、_shards
_shards 部分 告诉我们在查询中参与分片的总数,以及这些分片成功了多少个失败了多少个。正常情况下我们不希望分片失败,但是分片失败是可能发生的。如果我们遭遇到一种灾难级别的故障,
在这个故障中丢失了相同分片的原始数据和副本,那么对这个分片将没有可用副本来对搜索请求作出响应。假若这样,Elasticsearch 将报告这个分片是失败的,但是会继续返回剩余分片的结果。
4、timed_out
timed_out 值告诉我们查询是否超时。默认情况下,搜索请求不会超时。 如果低响应时间比完成结果更重要,你可以指定 timeout 为 10 或者 10ms(10毫秒),或者 1s(1秒):
GET /_search?timeout=10ms
在请求超时之前,Elasticsearch 将会返回已经成功从每个分片获取的结果。
3、所索引、多类型
注意到上面的空搜索 的结果,不同类型的文档 — blog和 test-type 来自不同的索引— website和 my-index ?
如果不对某一特殊的索引或者类型做限制,就会搜索集群中的所有文档。Elasticsearch 转发搜索请求到每一个主分片或者副本分片,汇集查询出的前10个结果,并且返回给我们。
然而,经常的情况下,你 想在一个或多个特殊的索引并且在一个或者多个特殊的类型中进行搜索。我们可以通过在URL中指定特殊的索引和类型达到这种效果,如下所示:
GET /_search : 在所有的索引中搜索所有的类型
GET /my-index/_search: 在 my-index 索引中搜索所有的类型
GET /mywebsite,my-index/_search: 在 website和 my-index 索引中搜索所有的文档
GET /m*,w*/_search: 在任何以 m 或者 u 开头的索引中搜索所有的类型
GET /my-index/test-type/_search: 在 my-index 索引中搜索 test-type 类型
GET /website,my-index/test-type,blog/_search: 在 website和 my-index 索引中搜索 test-type和 blog类型
GET /_all/test-type,blog/_search: 在所有的索引中搜索 test-type和 blog类型
当在单一的索引下进行搜索的时候,Elasticsearch 转发请求到索引的每个分片中,可以是主分片也可以是副本分片,然后从每个分片中收集结果。
多索引搜索恰好也是用相同的方式工作的--只是会涉及到更多的分片。
4、分页
在上面的空搜索中说明了集群中有 36个文档匹配了(empty)query 。 但是在 hits 数组中只有 10 个文档。如何才能看到其他的文档?
和 SQL 使用 LIMIT 关键字返回单个 page 结果的方法相同,Elasticsearch 接受 from 和 size 参数:
size- 显示应该返回的结果数量,默认是
10 from- 显示应该跳过的初始结果数量,默认是
0
如果每页展示 5 条结果,可以用下面方式请求得到 1 到 3 页的结果:
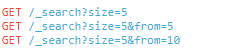
5、轻量搜索
有两种形式的 搜索 API:
一种是 “轻量的” 查询字符串 版本,要求在查询字符串中传递所有的 参数,
另一种是更完整的 请求体 版本,要求使用 JSON 格式和更丰富的查询表达式作为搜索语言。
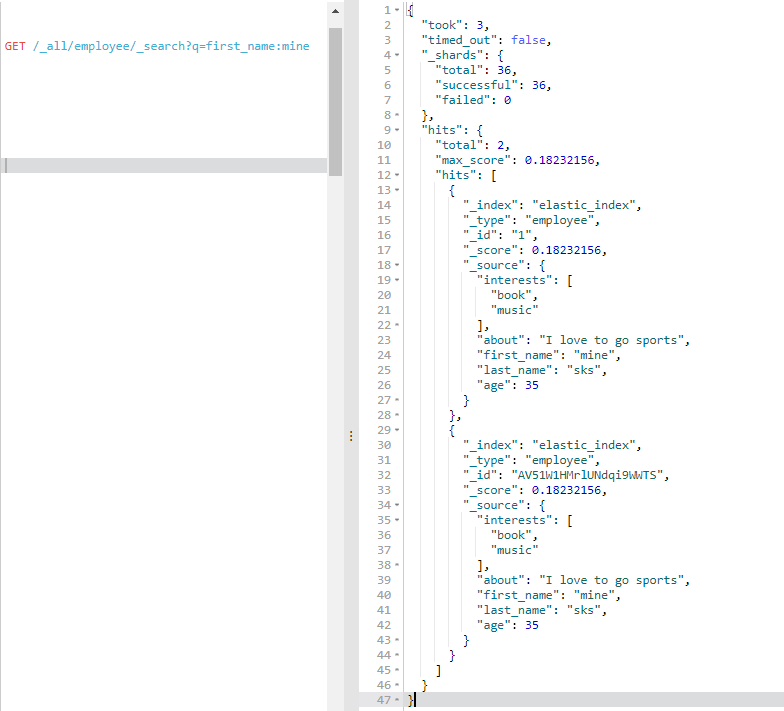
查询字符串搜索非常适用于通过命令行做即席查询。例如,查询在 employee 类型中 first_name字段包含 mine 单词的所有文档:
GET /_all/employee/_search?q=first_name:mine
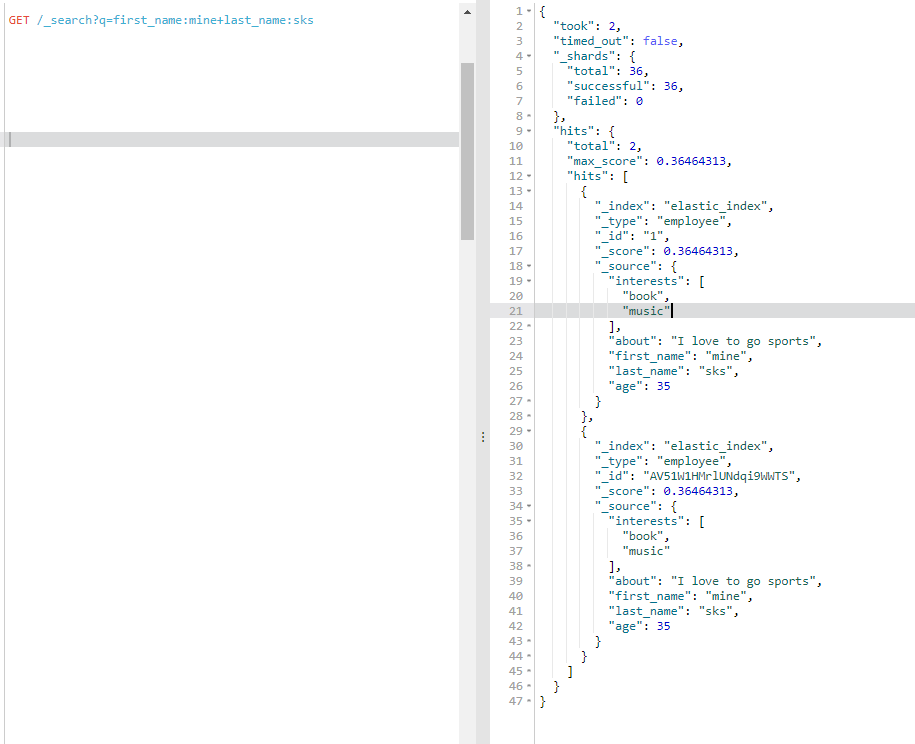
下一个查询在 first_name字段中包含 mine并且在 last_name字段中包含 sks的文档。实际的查询就是这样
+first_name:mine +last_name:sks
GET /_search?q=first_name:mine+last_name:sks
-
-
+前缀表示必须与查询条件匹配。类似地,-前缀表示一定不与查询条件匹配。没有+或者-的所有其他条件都是可选的——匹配的越多,文档就越相关。
_all 字段
这个简单搜索返回包含 Smith 的所有文档:GET /_search?q=Smith
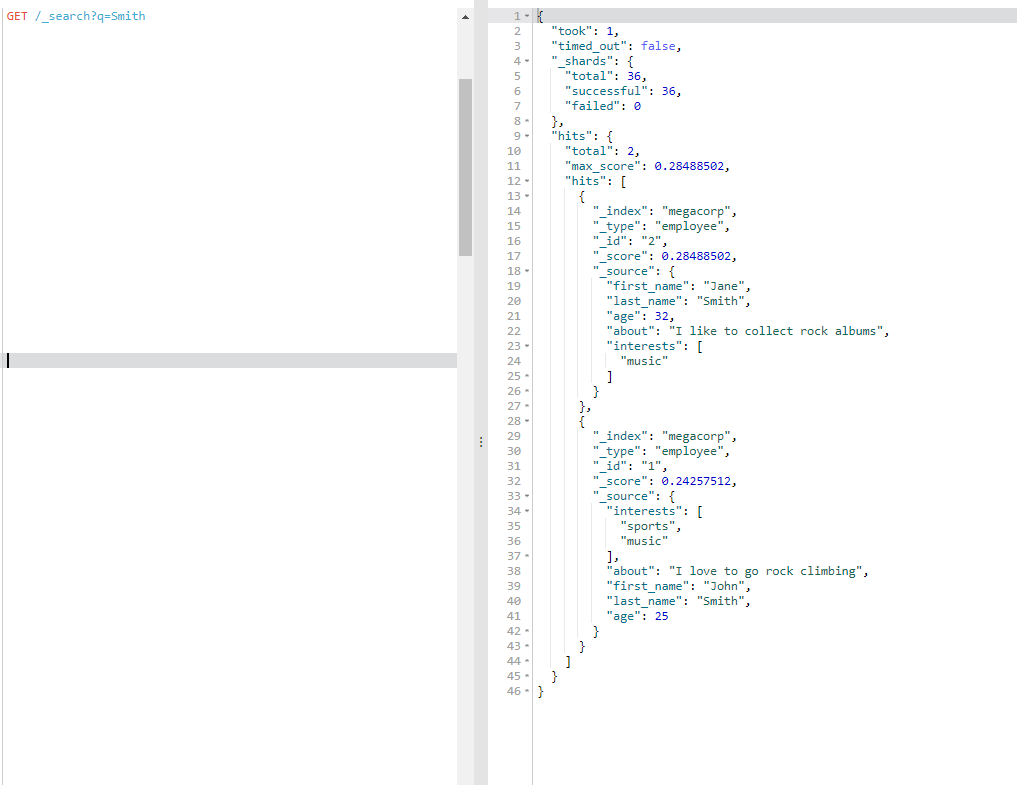
当索引一个文档的时候,Elasticsearch 取出所有字段的值拼接成一个大的字符串,作为 _all 字段进行索引。例如,当索引这个文档时:
{
"tweet": "However did I manage before Elasticsearch?",
"date": "2014-09-14",
"name": "Mary Jones",
"user_id": 1
}
这就好似增加了一个名叫 _all 的额外字段:
"However did I manage before Elasticsearch? 2014-09-14 Mary Jones 1"
除非设置特定字段,否则查询字符串就使用 _all 字段进行搜索。
ElasticSearch搜索的更多相关文章
- 一次 ElasticSearch 搜索优化
一次 ElasticSearch 搜索优化 1. 环境 ES6.3.2,索引名称 user_v1,5个主分片,每个分片一个副本.分片基本都在11GB左右,GET _cat/shards/user 一共 ...
- ElasticSearch搜索介绍四
ElasticSearch搜索 最基础的搜索: curl -XGET http://localhost:9200/_search 返回的结果为: { "took": 2, &quo ...
- Elasticsearch搜索结果返回不一致问题
一.背景 这周在使用Elasticsearch搜索的时候遇到一个,对于同一个搜索请求,会出现top50返回结果和排序不一致的问题.那么为什么会出现这样的问题? 后来通过百度和google,发现这是因为 ...
- ElasticStack学习(六):ElasticSearch搜索初探
一.ElasticSearch搜索介绍 1.ElasticSearch搜索方式主要分为以下两种: 1).URI Search:此种查询主要是使用Http的Get方法,在URL中使用查询参数进行查询: ...
- Elasticsearch搜索调优权威指南 (2/3)
本文首发于 vivo互联网技术 微信公众号 https://mp.weixin.qq.com/s/AAkVdzmkgdBisuQZldsnvg 英文原文:https://qbox.io/blog/el ...
- Elasticsearch搜索调优权威指南 (1/3)
本文首发于 vivo互联网技术 微信公众号 https://mp.weixin.qq.com/s/qwkZKLb_ghmlwrqMkqlb7Q英文原文:https://qbox.io/blog/ela ...
- kotlin + springboot启用elasticsearch搜索
参考自: http://how2j.cn/k/search-engine/search-engine-springboot/1791.html?p=78908 工具版本: elasticsearch ...
- Elasticsearch 搜索API
章节 Elasticsearch 基本概念 Elasticsearch 安装 Elasticsearch 使用集群 Elasticsearch 健康检查 Elasticsearch 列出索引 Elas ...
- Elasticsearch 搜索数据
章节 Elasticsearch 基本概念 Elasticsearch 安装 Elasticsearch 使用集群 Elasticsearch 健康检查 Elasticsearch 列出索引 Elas ...
- Elasticsearch搜索资料汇总
Elasticsearch 简介 Elasticsearch(ES)是一个基于Lucene 构建的开源分布式搜索分析引擎,可以近实时的索引.检索数据.具备高可靠.易使用.社区活跃等特点,在全文检索.日 ...
随机推荐
- json数据格式的简单案例
json数据是一种文本字符串,它是javascript的原生数据格式,在数据需要多次重复使用时,json数据是ajax请求的首先.(注:ajax返回的数据格式支持三种分别为:文本格式,json.和xm ...
- jquerydom对象和字符串之间的转换
字符串转jquery对象:var tmp = $('<div>dd</div>').attr('id','bbq'); //用$符包裹起来即可 jquery对象转字符串: tm ...
- 51nod1086 背包问题 V2——二进制优化
有N种物品,每种物品的数量为C1,C2......Cn.从中任选若干件放在容量为W的背包里,每种物品的体积为W1,W2......Wn(Wi为整数),与之相对应的价值为P1,P2......Pn(Pi ...
- 经典js框架
http://requirejs.org/ http://durandaljs.com/ http://knockoutjs.com/index.html http://www.jeasyui.com ...
- C#操作windows事件日志项
/// <summary> /// 指定事件日志项的事件类型 /// </summary> public enum EventLogLevel { /// <summar ...
- Codeforces #105 DIV2 ABCDE
开始按照顺序刷刷以前的CF. #include <map> #include <set> #include <list> #include <cmath> ...
- Charles安装
Charles 是一个网络抓包工具,在做 APP 抓包的时候会用到,相比 Fiddler 来说,Charles 的功能更为强大,而且跨平台支持更好,所以在这里我们选用 Charles 来作为主要的移动 ...
- 将log4j2的配置文件log4j2.xml拆分成多个xml文件
在日常的项目开发中,我们可能会使用log4j2分离系统日志与业务日志 ,这样一来,log4j2.xml 这个配置文件可能就会变得非常臃肿.庞大,那么我们可以将这个文件拆分成多个配置文件吗? 答案是肯定 ...
- jQuery笔记:checkbox
用jQuery操作checkbox时的一点小问题. 勾选checkbox的时候,$("#id").attr("checked")变为"checked& ...
- Gmail进程信息转储分析工具pdgmail
Gmail进程信息转储分析工具pdgmail 进程信息转储(Process Memory Dump)是数字取证的重要方式.通过分析对应进程的信息转储,可以获取大量的信息.Kali Linux提供一 ...