[Python] 糗事百科文本数据的抓取
[Python] 糗事百科文本数据的抓取
源码
https://github.com/YouXianMing/QiuShiBaiKeText
import sqlite3
import time
import requests
from regexp_string import * class QiuShiBaiKeText35: db_name = 'qiu_shi_bai_ke_text35.db'
conn = None def prepare(self):
"""
开始准备数据库相关准备工作
:return: PiuShiBaiKeText35对象本身
""" # 连接数据库,不存在则创建
self.conn = sqlite3.connect(self.db_name) # 不存在表则创建表
sql_str = """CREATE TABLE IF NOT EXISTS qiu_shi_bai_ke_text (articleId INT8 PRIMARY KEY NOT NULL,
content TEXT, date TIMESTAMP); """
self.conn.execute(sql_str) # 关闭数据库
self.conn.close()
self.conn = None return self def start(self, max_page=99999):
"""
开始爬数据
:param max_page: 最大页码,不设置则为99999
:return: PiuShiBaiKeText35对象本身
""" self.conn = sqlite3.connect(self.db_name)
self.__qiu_shi_text(max_page)
self.conn.close()
self.conn = None return self def __qiu_shi_text(self, max_page=99999):
"""
开始扫描
:param max_page: 最大页码,不设置则为99999
:return: None
""" for i in range(1, max_page): url = "http://www.qiushibaike.com/text/page/%s/" % i
print(url)
time.sleep(0.5) request = requests.get(url) if i != 1:
request = requests.get(url)
if request.url != url:
break self.__convert_from_web_string(request.text) def __convert_from_web_string(self, web_string):
"""
获取网页字符串,并用正则表达式进行解析
:param web_string: 网页字符串
:return: None
""" # 获取列表
pattern = r"""\d+" target="_blank" class='contentHerf' >.+?</span>"""
item_list = RegExpString(web_string).get_item_list_with_pattern(pattern) # 如果存在列表,则遍历列表
if item_list: for item in item_list: # 内容id
article_id = RegExpString(item).search_with_pattern(r'^\d+').search_result # 内容
article_content = RegExpString(item).search_with_pattern(
r'(?<=<span>).+(?=</span>)').search_result
article_content = RegExpString(article_content).replace_with_pattern(r'<br/>',
"\n").replace_result # 打印内容
print("http://www.qiushibaike.com/article/%s\n%s\n\n" % (article_id, article_content)) # 先查找有没有这个id的数据
cursor = self.conn.execute("""SELECT COUNT(*) FROM qiu_shi_bai_ke_text WHERE articleId = '%s';""" % article_id) for row in cursor: # 如果查不到数据,则插入数据
if row[0] == 0:
# 插入语句
sql_str = """INSERT INTO qiu_shi_bai_ke_text (articleId, content, date) VALUES ('%s', '%s', '%s');""" % (
article_id, article_content, time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()))
self.conn.execute(sql_str) self.conn.commit()
细节
1. 抓取 http://www.qiushibaike.com/text/ 所有35个页面的文本数据
2. 抓取的数据写进数据库,数据库用的是sqlite3
3. 基于Python3.60版本,其他版本未测试
4. 网络库使用过的 requests (https://github.com/kennethreitz/requests) ,如果没有安装,请使用 pip install requests 安装
效果
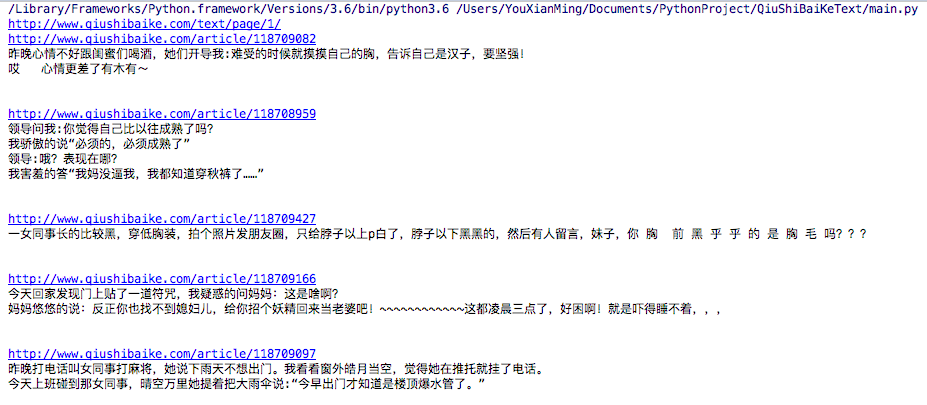
[Python] 糗事百科文本数据的抓取的更多相关文章
- python 糗事百科实例
爬取糗事百科段子,假设页面的URL是 http://www.qiushibaike.com/8hr/page/1 要求: 使用requests获取页面信息,用XPath / re 做数据提取 获取每个 ...
- Python爬虫--抓取糗事百科段子
今天使用python爬虫实现了自动抓取糗事百科的段子,因为糗事百科不需要登录,抓取比较简单.程序每按一次回车输出一条段子,代码参考了 http://cuiqingcai.com/990.html 但该 ...
- python爬虫之爬取糗事百科并将爬取内容保存至Excel中
本篇博文为使用python爬虫爬取糗事百科content并将爬取内容存入excel中保存·. 实验环境:Windows10 代码编辑工具:pycharm 使用selenium(自动化测试工具)+p ...
- 糗事百科python爬虫
# -*- coding: utf-8 -*- #coding=utf-8 import urllib import urllib2 import re import thread import ti ...
- 5 使用ip代理池爬取糗事百科
从09年读本科开始学计算机以来,一直在迷茫中度过,很想学些东西,做些事情,却往往陷进一些技术细节而蹉跎时光.直到最近几个月,才明白程序员的意义并不是要搞清楚所有代码细节,而是要有更宏高的方向,要有更专 ...
- 初识python 之 爬虫:使用正则表达式爬取“糗事百科 - 文字版”网页数据
初识python 之 爬虫:使用正则表达式爬取"古诗文"网页数据 的兄弟篇. 详细代码如下: #!/user/bin env python # author:Simple-Sir ...
- python 抓取糗事百科糗图
1 首先看下要抓取的页面 这是糗事百科里面的糗图页面,每一页里面有很多的图片,我们要做的就是把这些图片抓取下来. 2 分析网页源代码 发现源代码里面的每张图是这样储存的,所以决定使用正则匹配出图片的u ...
- Python抓取糗事百科成人版图片
最近开始学习爬虫,一开始看的是静觅的爬虫系列文章,今天看到糗事百科成人版,心里就邪恶了一下,把图片都爬下来吧,哈哈~ 虽然后来实现了,但还是存在一些问题,暂且不提,先切入正题吧,没什么好说的,直接上代 ...
- Python爬虫(十八)_多线程糗事百科案例
多线程糗事百科案例 案例要求参考上一个糗事百科单进程案例:http://www.cnblogs.com/miqi1992/p/8081929.html Queue(队列对象) Queue是python ...
随机推荐
- python之抽象基类
抽象基类特点 1.不能够实例化 2.在这个基础的类中设定一些抽象的方法,所有继承这个抽象基类的类必须覆盖这个抽象基类里面的方法 思考 既然python中有鸭子类型,为什么还要使用抽象基类? 一是我们在 ...
- python 全栈开发,Day63(子查询,MySQl创建用户和授权,可视化工具Navicat的使用,pymysql模块的使用)
昨日内容回顾 外键的变种三种关系: 多对一: 左表的多 对右表一 成立 左边的一 对右表多 不成立 foreign key(从表的id) refreences 主表的(id) 多对多 建立第三张表(f ...
- ORACLE 锁表处理,解锁释放session
后台数据库操作某一个表时发现一直出于假死状态,可能是该表被某一用户锁定,或者后台数据库操作某一个表时发现一直出于"假死"状态,可能是该表被某一用户锁定,导致其他用户无法继续操作 - ...
- WebService:CXF-SPRING 读书笔记
WEBSERVICE是给第三方提供一个接口,可以方便的与不同平台的系统进行通信,当然咯,这个只是我们通常运用到的最主要的作用,还有其他作用,见BAIDU知道.一个WEBSERVICE简单实例分为以下几 ...
- ORACLE分页查询SQL语法——高效的分页
--1:无ORDER BY排序的写法.(效率最高)--(经过测试,此方法成本最低,只嵌套一层,速度最快!即使查询的数据量再大,也几乎不受影响,速度依然!) SELECT * FROM (SELECT ...
- openstack学习-创建一台云主机(七)
一.创建基础环境 1.检查网络是否正常 [root@linux-node1 ~]# openstack network agent list +---------------------------- ...
- python全栈开发day23-面向对象高级:反射(getattr、hasattr、setattr、delattr)、__call__、__len__、__str__、__repr__、__hash__、__eq__、isinstance、issubclass
一.今日内容总结 1.反射 使用字符串数据类型的变量名来操作一个变量的值. #使用反射获取某个命名空间中的值, #需要 #有一个变量指向这个命名空间 #字符串数据类型的名字 #再使用getattr获取 ...
- jquery返回页面顶部
1.此博文图片样式引用腾讯网站,效果如下: 2.样式设置: #toTop { /*选中的背景图片的大小*/ width: 54px; height: 54px; display: none;/*刚开始 ...
- 7-6 Bandwidth UVA140
没有清空向量导致debug了好久 这题难以下手 不知道怎么dfs 原来是用排序函数. letter[n]=i; id[i]=n++; 用来储存与设置标记十分巧妙 for(;;) { while(s[ ...
- 017 在SecureCRT中安装rz小工具
1.安装yum 2.上传本地的文件进虚拟机 3.注意点 只是属于SecureCRT的命令,同时,在上传的位置是现在所在的位置 4.测试