python学习笔记:"爬虫+有道词典"实现一个简单的英译汉程序
1.有道的翻译

Fig1

Fig2
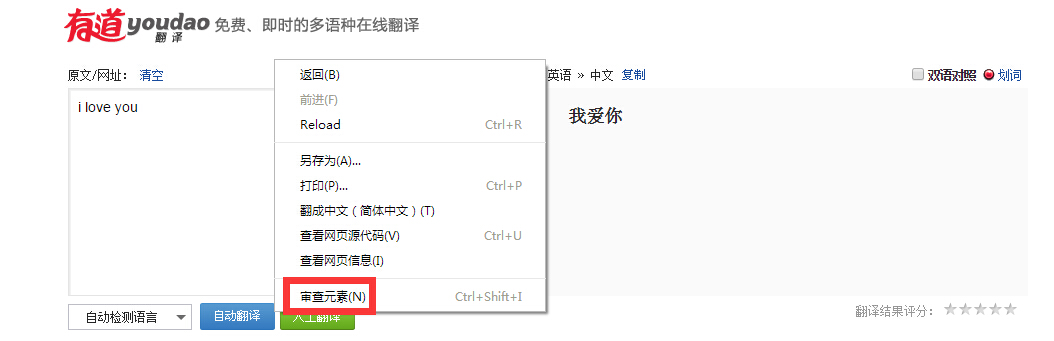
Fig3

Fig4
再次点击"自动翻译"->选中'Network'->选中'第一项',如下:

Fig5
然后显示出如下内容,红框画出的部分是等会编写代码需要的地方:

Fig6
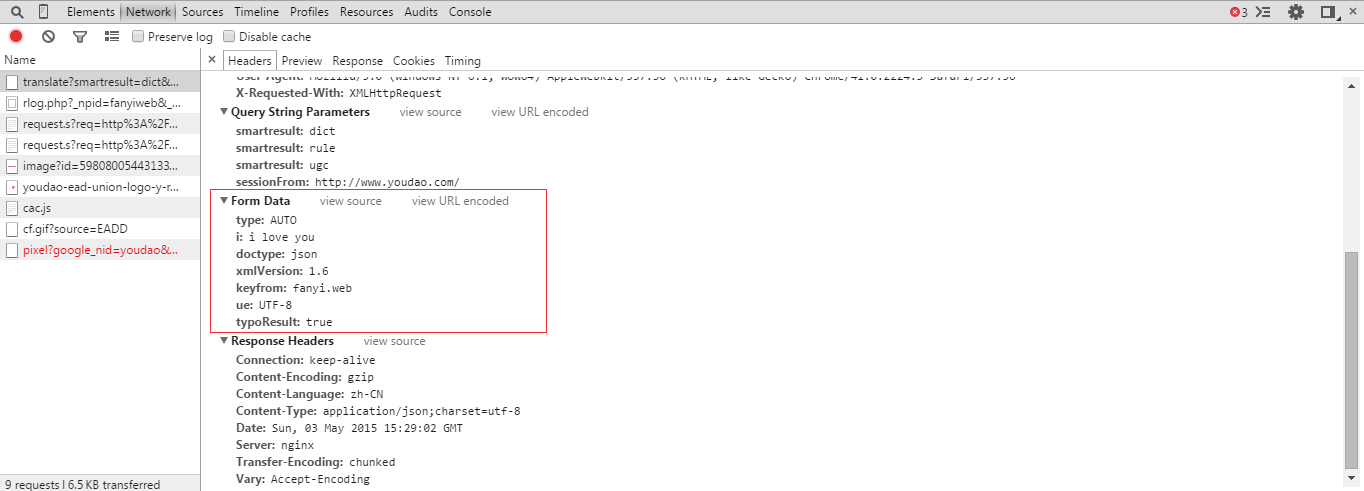
Fig7
再看看翻译的结果:

Fig8
2.python实现英译汉:
原理:把需要翻译的内容输入给有道词典,然后通过程序把翻译的结果爬下来。
# -*- coding:utf-8 -*-
"""
Created on Sun May 03 09:36:12 2015 @author: 90Zeng
""" import urllib
import json # 注意这里用unicode编码,否则会显示乱码
content = input(u"请输入要翻译的内容:")
# 网址是Fig6中的 Response URL
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=http://www.youdao.com/'
# 爬下来的数据 data格式是Fig7中的 Form Data
data = {}
data['type'] = 'AUTO'
data['i'] = content
data['doctype'] = 'json'
data['xmlVersion'] = '1.6'
data['keyfrom'] = 'fanyi.web'
data['ue'] = 'UTF-8'
data['typoResult'] = 'true' # 数据编码
data = urllib.urlencode(data) # 按照data的格式从url爬内容
response = urllib.urlopen(url, data)
# 将爬到的内容读出到变量字符串html,
html = response.read()
# 将字符串转换成Fig8所示的字典形式
target = json.loads(html)
# 根据Fig8的格式,取出最终的翻译结果
result = target["translateResult"][0][0]['tgt'] # 这里用unicode显示中文,避免乱码
print(u"翻译结果:%s" % (target["translateResult"][0][0]['tgt']))
运行:


学习资料来源:小甲鱼的视频‘零基础入门python’
python学习笔记:"爬虫+有道词典"实现一个简单的英译汉程序的更多相关文章
- python "爬虫+有道词典"实现一个简单翻译程序
抓包软件使用的是Fiddler4 新版的查询接口 比较负责,引入了salt和sign http://fanyi.youdao.com/translate?smartresult=dict&sm ...
- ZooKeeper学习笔记三:使用ZooKeeper实现一个简单的配置中心
作者:Grey 原文地址:ZooKeeper学习笔记三:使用ZooKeeper实现一个简单的配置中心 前置知识 完成ZooKeeper集群搭建以及熟悉ZooKeeperAPI基本使用 需求 很多程序往 ...
- ZooKeeper学习笔记四:使用ZooKeeper实现一个简单的分布式锁
作者:Grey 原文地址: ZooKeeper学习笔记四:使用ZooKeeper实现一个简单的分布式锁 前置知识 完成ZooKeeper集群搭建以及熟悉ZooKeeperAPI基本使用 需求 当多个进 ...
- python学习笔记——爬虫学习中的重要库urllib
1 urllib概述 1.1 urllib库中的模块类型 urllib是python内置的http请求库 其提供了如下功能: (1)error 异常处理模块 (2)parse url解析模块 (3)r ...
- Python学习笔记(二)网络编程的简单示例
Python中的网络编程比C语言中要简洁很多,毕竟封装了大量的细节. 所以这里不再介绍网络编程的基本知识.而且我认为,从Python学习网络编程不是一个明智的选择. 简单的TCP连接 服务器代码如 ...
- python学习笔记——爬虫中提取网页中的信息
1 数据类型 网页中的数据类型可分为结构化数据.半结构化数据.非结构化数据三种 1.1 结构化数据 常见的是MySQL,表现为二维形式的数据 1.2 半结构化数据 是结构化数据的一种形式,并不符合关系 ...
- python学习笔记——爬虫的抓取策略
1 深度优先算法 2 广度/宽度优先策略 3 完全二叉树遍历结果 深度优先遍历的结果:[1, 3, 5, 7, 9, 4, 12, 11, 2, 6, 14, 13, 8, 10] 广度优先遍历的结果 ...
- [Python学习笔记]爬虫
要使用Python 抓取网页,首先我们要学习下面四个模块: 包 作用 webbrowser 打开浏览器获取指定页面: requests 从因特网下载文件和网页: Beautiful Soup 解析HT ...
- Python学习笔记4-如何快速的学会一个Python的模块、方法、关键字
想要快速的学会一个Python的模块和方法,两个函数必须要知道,那就是dir()和help() dir():能够快速的以集合的型式列出该模块下的所有内容(类.常量.方法)例: #--encoding: ...
随机推荐
- hdu 6406 Taotao Picks Apples (2018 Multi-University Training Contest 8 1010)(二分,前缀和)
链接:http://acm.hdu.edu.cn/showproblem.php?pid=6406 思路: 暴力,预处理三个前缀和:[1,n]桃子会被摘掉,1到当前点的最大值,1到当前点被摘掉的桃子的 ...
- 自学Linux Shell8.2-linux逻辑卷LVM管理
点击返回 自学Linux命令行与Shell脚本之路 8.2-linux逻辑卷LVM管理 Linux逻辑卷管理器软件包用来通过将另外一个硬盘上的分区加入已有文件系统,动态地添加存储空间. 1. 逻辑卷L ...
- List does not exist. The page you selected contains a list that does not exist. It may have been deleted by another user
当我在subsite里点击"Add a document",报这个错,后来一看event log: 在AAM里加上一条: 问题搞定:
- luogu4185 [USACO18JAN]MooTube (并查集)
类似于NOI2018d1t1的离线做法,把询问存下来,排个序,然后倒着给并查集加边,每次询问并查集联通块大小 #include<bits/stdc++.h> #define ll long ...
- POJ 1459 Power Network / HIT 1228 Power Network / UVAlive 2760 Power Network / ZOJ 1734 Power Network / FZU 1161 (网络流,最大流)
POJ 1459 Power Network / HIT 1228 Power Network / UVAlive 2760 Power Network / ZOJ 1734 Power Networ ...
- EXGCD 扩展欧几里得
推荐:https://www.zybuluo.com/samzhang/note/541890 扩展欧几里得,就是求出来ax+by=gcd(x,y)的x,y 为什么有解? 根据裴蜀定理,存在u,v使得 ...
- win7(旗舰版)下,OleLoadPicture 加载内存中的图片(MagickGetImageBlob),返回值 < 0
昨天去三哥家,想把拍好的照片缩小一下,我用很久前写的一个软件进行缩小,然后进行一次效果预览,这个时候弹出: Call OleLoadPicture Fail - loadPictureFromMW 奇 ...
- 多线程Java Socket编程
采用Java 5的ExecutorService来进行线程池的方式实现多线程,模拟客户端多用户向同一服务器端发送请求. 1.服务端 package localSocket; import java.i ...
- Elasticsearch日志分析系统
Elasticsearch日志分析系统 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.什么是Elasticsearch 一个采用Restful API标准的高扩展性的和高可用性 ...
- Telnet的三种登录方式
Telnet的三种登录方式 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.华为创建telnet的三种验证方式 首先,我们可以简单的看一个拓扑图,让我们可以在亦庄的路由器上对双桥 ...