ML: 聚类算法R包-K中心点聚类
K-medodis与K-means比较相似,但是K-medoids和K-means是有区别的,不一样的地方在于中心点的选取,在K-means中,我们将中心点取为当前cluster中所有数据点的平均值,在 K-medoids算法中,我们将从当前cluster 中选取这样一个点——它到其他所有(当前cluster中的)点的距离之和最小——作为中心点。K-medodis算法不容易受到那些由于误差之类的原因产生的脏数据的影响,但计算量显然要比K-means要大,一般只适合小数据量。 K-medoids 主要运用到了R语言中cluster包中的pam函数
K中心点聚类
- cluster::pam
- fpc::pamk
cluster::pam
Usage: pam(x, k, diss = inherits(x, "dist"), metric = "euclidean", medoids = NULL, stand = FALSE, cluster.only = FALSE, do.swap = TRUE, keep.diss = !diss && !cluster.only && n < 100, keep.data = !diss && !cluster.only, pamonce = FALSE, trace.lev = 0)
- x:聚类对象
- k: 是聚类个数 ( positive integer specifying the number of clusters, less than the number of observations)
示例代码
> newiris <- iris[,-5]
> library(cluster)
> kc <- pam(x=newiris,k=3)
> #kc$clustering
> #kc[1:length(kc)]
>
> table(iris$Species, kc$clustering) 1 2 3
setosa 50 0 0
versicolor 0 48 2
virginica 0 14 36
小结:
针对K-均值算法易受极值影响这一缺点的改进算法.在原理上的差异在于选择个类别中心点时不取样本均值点,而在类别内选取到其余样本距离之和最小的样本为中心。
fpc::pamk
相比于pam函数,可以给出参考的聚类个数, 参考 kmenas 与 kmeansrun
Usage: pamk(data,krange=2:10,criterion="asw", usepam=TRUE, scaling=FALSE, alpha=0.001, diss=inherits(data, "dist"), critout=FALSE, ns=10, seed=NULL, ...)
示例代码
newiris <- iris
newiris$Species <- NULL
library(fpc)
kc2 <- pamk(newiris,krang=1:5)
plot(pam(newiris, kc2$nc))
图例
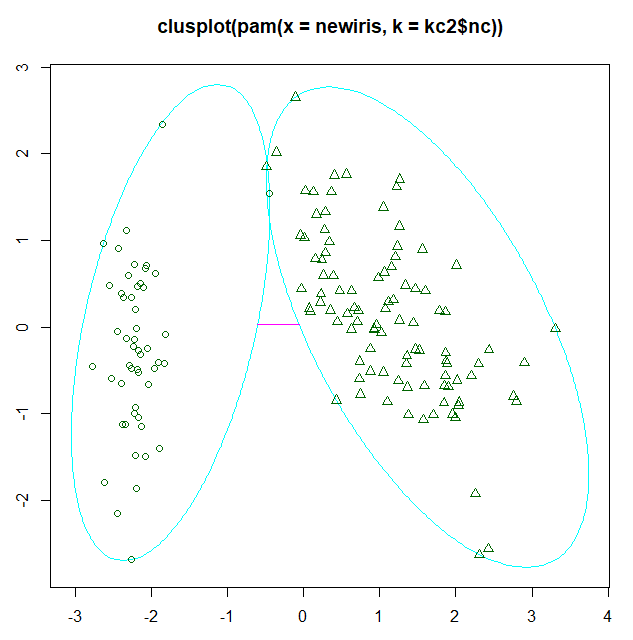
fpc包还提供了另一个展示聚类分析的函数plotcluster(),值得一提的是,数据将被投影到不同的簇中
plotcluster(newiris,kc2$cluster)
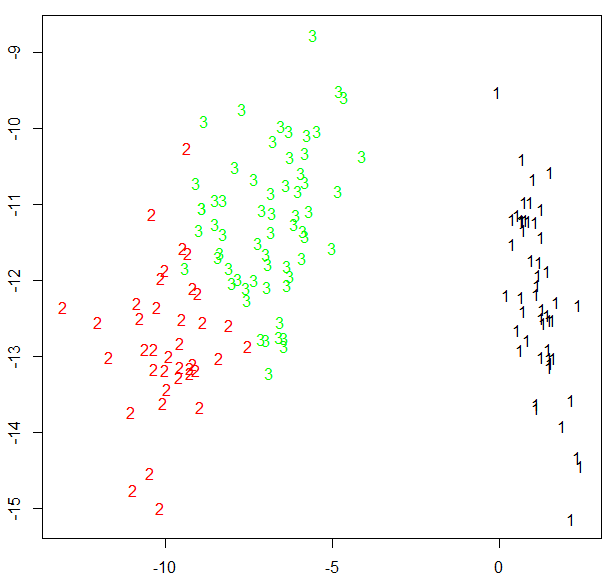
待验证:
为什么仅出现两个聚类?
参考资料:
ML: 聚类算法R包-K中心点聚类的更多相关文章
- ML: 聚类算法R包-层次聚类
层次聚类 stats::hclust stats::dist R使用dist()函数来计算距离,Usage: dist(x, method = "euclidean", di ...
- ML: 聚类算法R包 - 模型聚类
模型聚类 mclust::Mclust RWeka::Cobweb mclust::Mclust EM算法也称为期望最大化算法,在是使用该算法聚类时,将数据集看作一个有隐形变量的概率模型,并实现模型最 ...
- ML: 聚类算法R包-模糊聚类
1965年美国加州大学柏克莱分校的扎德教授第一次提出了'集合'的概念.经过十多年的发展,模糊集合理论渐渐被应用到各个实际应用方面.为克服非此即彼的分类缺点,出现了以模糊集合论为数学基础的聚类分析.用模 ...
- ML: 聚类算法R包-对比
测试验证环境 数据: 7w+ 条,数据结构如下图: > head(car.train) DV DC RV RC SOC HV LV HT LT Type TypeName 1 379 85.09 ...
- ML: 聚类算法R包-网格聚类
网格聚类算法 optpart::clique optpart::clique CLIQUE(Clustering In QUEst)是一种简单的基于网格的聚类方法,用于发现子空间中基于密度的簇.CLI ...
- ML: 聚类算法R包 - 密度聚类
密度聚类 fpc::dbscan fpc::dbscan DBSCAN核心思想:如果一个点,在距它Eps的范围内有不少于MinPts个点,则该点就是核心点.核心和它Eps范围内的邻居形成一个簇.在一个 ...
- Python聚类算法之基本K均值实例详解
Python聚类算法之基本K均值实例详解 本文实例讲述了Python聚类算法之基本K均值运算技巧.分享给大家供大家参考,具体如下: 基本K均值 :选择 K 个初始质心,其中 K 是用户指定的参数,即所 ...
- 机器学习算法总结(五)——聚类算法(K-means,密度聚类,层次聚类)
本文介绍无监督学习算法,无监督学习是在样本的标签未知的情况下,根据样本的内在规律对样本进行分类,常见的无监督学习就是聚类算法. 在监督学习中我们常根据模型的误差来衡量模型的好坏,通过优化损失函数来改善 ...
- 模式识别之聚类算法k-均值---k-均值聚类算法c实现
//写个简单的先练习一下,测试通过 //k-均值聚类算法C语言版 #include <stdlib.h> #include <stdio.h> #inc ...
随机推荐
- angular5 自定义指令 输入输出 @Input @Output(右键点击事件传递)
指令写法,angular5官网文档给的很详细. 首先要创建一个文件,需注意命名规范(后缀名为xxx.directive.ts): 今天要记录的是在多个li中,右键点击之后显示出对应的菜单,直接上图吧! ...
- matlab handle plot
https://cn.mathworks.com/help/matlab/ref/plotyy.html
- 【opencv基础】imwrite函数与图像存储质量
前言 std::vector<int> compression_params; compression_params.push_back(CV_IMWRITE_JPEG_QUALITY); ...
- NOI-1.1-06-空格分隔输出-体验多个输入输出
06:空格分隔输出 总时间限制: 1000ms 内存限制: 65536kB 描述 读入一个字符,一个整数,一个单精度浮点数,一个双精度浮点数,然后按顺序输出它们,并且要求在他们之间用一个空格分隔. ...
- urllib模块通过post请求获取数据
功能: 输入你要查找的单词,会返回相对应的结果 import urllib.request import urllib.parse import json class youdaoSpider: de ...
- TLS编程
最近测试广州电信的电话会议平台,该平台接入采用HTTPS协议,于是有了本文.09年培训时写过一个简单的TLS C/S结构交互,采用openssl的ssl相关接口,但与生产相去胜远.本文采用openss ...
- angular的点击添加
首先是在js里面我们可以用clone来点击添加一些东西比如列表或者其他的div之类的,但是在angular里面怎么实现点击添加呢? 类似这种: 这样就尴尬了,最少我这样的菜鸟是不知道怎么去写的,网上好 ...
- HPU1460: 杨八方的表面兄弟
题目描述 如果你之前关注过HPUOJ的话,那么你一定听说过杨八方的名字.在去年,很多同学共同见证了杨八方同学的填报志愿.来到学校.军训--或许你曾陪同杨八方一起思考过许多问题,又或者你是刚听说这个名字 ...
- Thread_run()方法
cas 1: package threadTest; public class ThreadTest { public static void main(String[] args) { Thread ...
- manjaro初体验
manjaro Linux是https://distrowatch.com/网站上排名第一的Linux分支. https://manjaro.org/ 选择,下载,打开主页下载页:https://ma ...