Python 网页解析器
Python 有几种网页解析器?
1、 正则表达式
2、html.parser (Python自动)
3、BeautifulSoup(第三方)(功能比较强大) 是一个HTML/XML的解析器
4、lxml (第三方)
BeautifulSoup 栗子:
地址:https://www.crummy.com/software/BeautifulSoup/bs4/download/
PyCharm安装方法
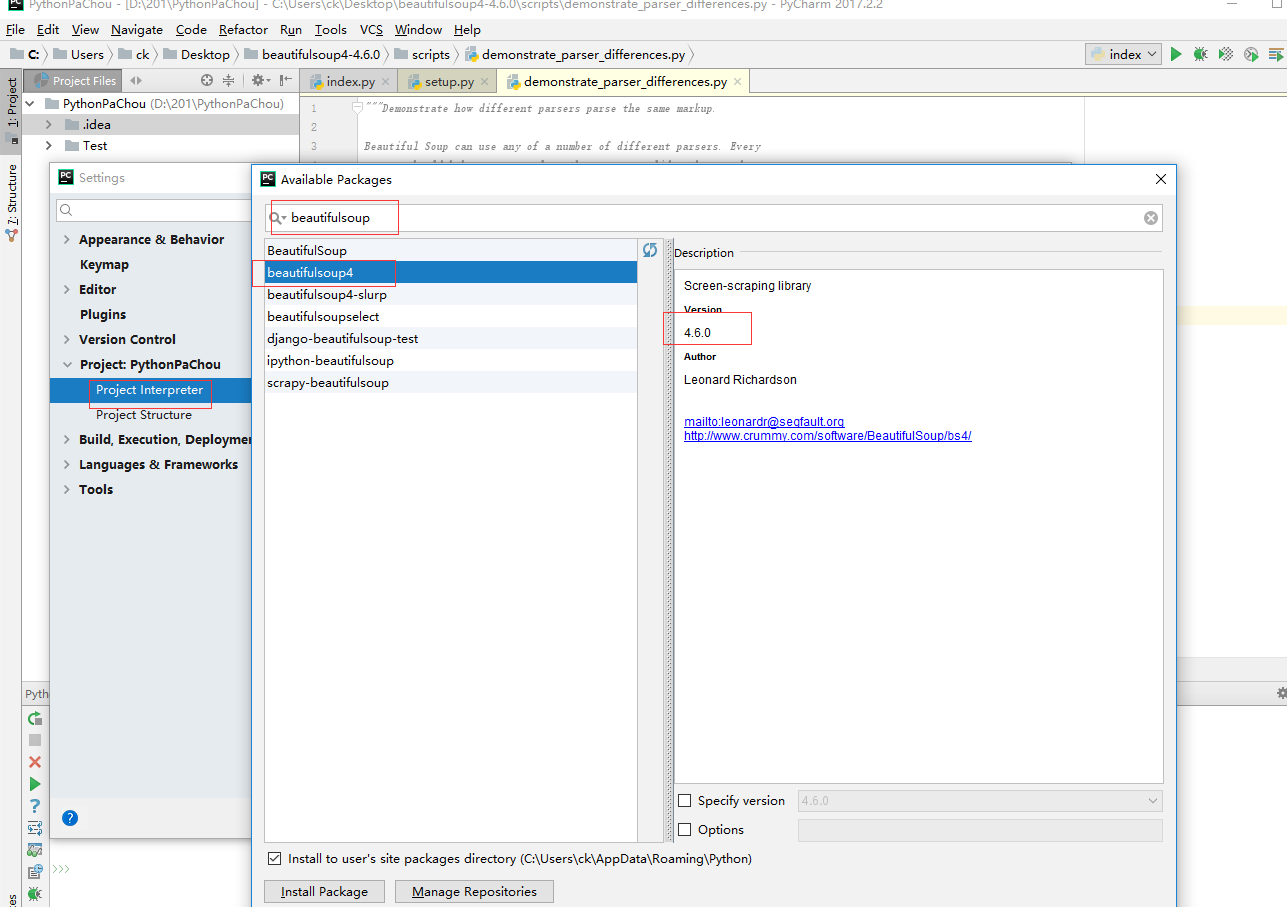
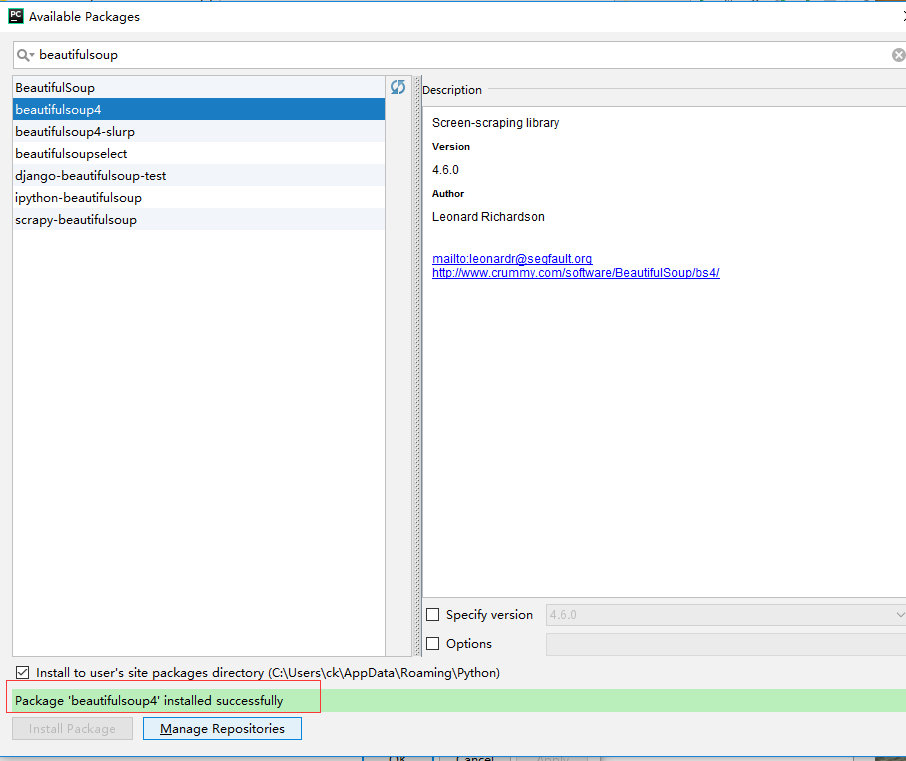
file → Settings → Project Interpreter(这一步需要你自己找一下),点击右边 "+" 加号,输入 beautifulsoup 选择对应的版本就ok了,上图:
来一个栗子:
from bs4 import BeautifulSoup
import re html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p> <p class="story">...</p>
""" soup = BeautifulSoup(html_doc,'html.parser',from_encoding='utf-8') print('获取所有的连接')
links = soup.find_all('a') for link in links:
print(link.name,link['href'],link.get_text()) print('获取lacie的连接')
link_node = soup.find('a',href='http://example.com/lacie')
print(link.name, link['href'], link.get_text()) #模糊匹配
print('正则匹配')
link_node = soup.find('a',href=re.compile(r'lll'))
print(link.name, link['href'], link.get_text()) print('获取P段落文字')
param = input('请输入要检索的样式名称:')
p_node = soup.find('p',class_='story')
print(p_node.name, p_node.get_text())
Python 网页解析器的更多相关文章
- python 之网页解析器
一.什么是网页解析器 1.网页解析器名词解释 首先让我们来了解下,什么是网页解析器,简单的说就是用来解析html网页的工具,准确的说:它是一个HTML网页信息提取工具,就是从html网页中解析提取出“ ...
- Python 文本解析器
Python 文本解析器 一.课程介绍 本课程讲解一个使用 Python 来解析纯文本生成一个 HTML 页面的小程序. 二.相关技术 Python:一种面向对象.解释型计算机程序设计语言,用它可以做 ...
- 第6章 网页解析器和BeautifulSoup第三方插件
第一节 网页解析器简介作用:从网页中提取有价值数据的工具python有哪几种网页解析器?其实就是解析HTML页面正则表达式:模糊匹配结构化解析-DOM树:html.parserBeautiful So ...
- python3 爬虫五大模块之四:网页解析器
Python的爬虫框架主要可以分为以下五个部分: 爬虫调度器:用于各个模块之间的通信,可以理解为爬虫的入口与核心(main函数),爬虫的执行策略在此模块进行定义: URL管理器:负责URL的管理,包括 ...
- Python网页解析库:用requests-html爬取网页
Python网页解析库:用requests-html爬取网页 1. 开始 Python 中可以进行网页解析的库有很多,常见的有 BeautifulSoup 和 lxml 等.在网上玩爬虫的文章通常都是 ...
- Python HTML解析器BeautifulSoup(爬虫解析器)
BeautifulSoup简介 我们知道,Python拥有出色的内置HTML解析器模块——HTMLParser,然而还有一个功能更为强大的HTML或XML解析工具——BeautifulSoup(美味的 ...
- Python网页解析
续上篇文章,网页抓取到手之后就是解析网页了. 在Python中解析网页的库不少,我最开始使用的是BeautifulSoup,貌似这个也是Python中最知名的HTML解析库.它主要的特点就是容错性很好 ...
- 转:Python网页解析:BeautifulSoup vs lxml.html
转自:http://www.cnblogs.com/rzhang/archive/2011/12/29/python-html-parsing.html Python里常用的网页解析库有Beautif ...
- python——BS解析器
随机推荐
- 转:Http下载文件类 支技断点续传功能
using System; using System.Collections.Generic; using System.Text; using System.IO; using System.Net ...
- mysql 2
mysql索引原理 初识索引 为什么要索引? 加速查询 读写比10:1左右 什么是索引? 索引在MySQL中也叫是一种“键”,是存储引擎用于快速找到记录的一种数据结构. 索引是应 ...
- 大数据学习路线:Hadoop集群同步技术分享
今天给大家带来的技术分享是——Hadoop集群同步. 一.同步方式 选择一个机器,作为时间服务器(这里选择hadoop01),所有的机器与这台集群时间进行定时的同步,比如,每隔十分钟,同步一次时间. ...
- linux系统电视盒子到底是什么
经常看到各种大神说今天刷了什么linux系统可以干嘛干嘛了,刷了乌班图可以干嘛干嘛了,但是身为一个小白,对这种名词都是一知半解.所以这边给大家科普一下,什么是linux系统?电视盒子刷了这个可以干啥? ...
- 前端框架VUE----表单输入绑定
vue的核心:声明式的指令和数据的双向绑定. 那么声明式的指令,已经给大家介绍完了.接下来我们来研究一下什么是数据的双向绑定? 另外,大家一定要知道vue的设计模式:MVVM M是Model的简写,V ...
- oj练习---dp专题
1.POJ 3744 Scout YYF I 经典的dp模型,但是要用到快速矩阵幂加速,分段的思想 # include <stdio.h> # include <algorithm& ...
- 图片转化成base64字符串
package demo; import sun.misc.BASE64Decoder; import sun.misc.BASE64Encoder; import java.io.*; public ...
- QT开发基础教程
http://www.qter.org/portal.php?mod=view&aid=11
- 【react懒加载组件】--react-lazyload
组件安装: npm install react-lazyload --save-dev 组件使用: //引入 import LazyLoad from 'react-lazyload'; //rend ...
- 【开源】EasyFlash 新年发布 V4.0 beta 版,完全重写(转)
[开源]EasyFlash 新年发布 V4.0 beta 版,完全重写 EasyFlash V4.0 beta [开源]嵌入式闪存库 EasyFlash for STM32,支持Env和IAP