Python 网页解析器
Python 有几种网页解析器?
1、 正则表达式
2、html.parser (Python自动)
3、BeautifulSoup(第三方)(功能比较强大) 是一个HTML/XML的解析器
4、lxml (第三方)
BeautifulSoup 栗子:
地址:https://www.crummy.com/software/BeautifulSoup/bs4/download/
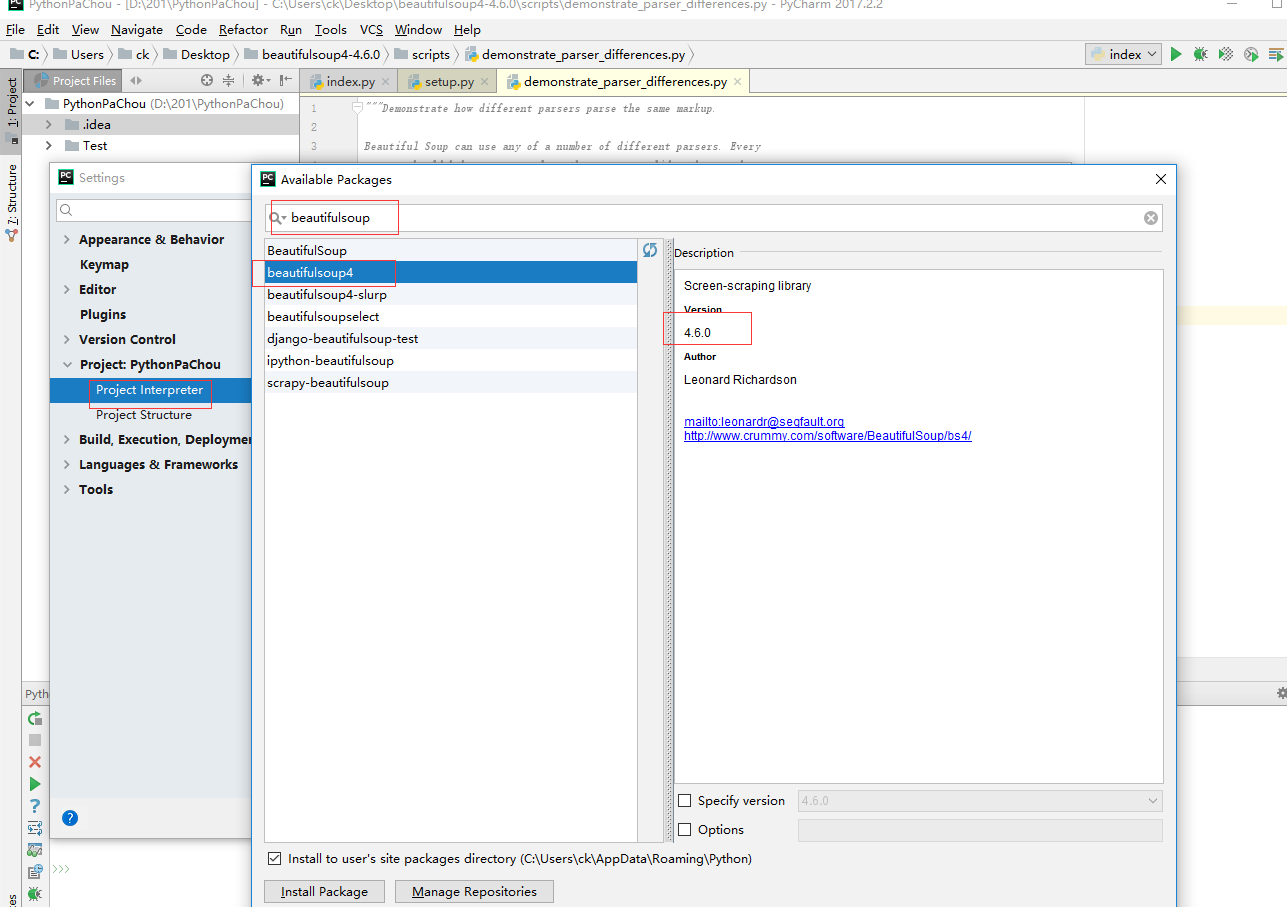
PyCharm安装方法
file → Settings → Project Interpreter(这一步需要你自己找一下),点击右边 "+" 加号,输入 beautifulsoup 选择对应的版本就ok了,上图:
来一个栗子:
from bs4 import BeautifulSoup
import re html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p> <p class="story">...</p>
""" soup = BeautifulSoup(html_doc,'html.parser',from_encoding='utf-8') print('获取所有的连接')
links = soup.find_all('a') for link in links:
print(link.name,link['href'],link.get_text()) print('获取lacie的连接')
link_node = soup.find('a',href='http://example.com/lacie')
print(link.name, link['href'], link.get_text()) #模糊匹配
print('正则匹配')
link_node = soup.find('a',href=re.compile(r'lll'))
print(link.name, link['href'], link.get_text()) print('获取P段落文字')
param = input('请输入要检索的样式名称:')
p_node = soup.find('p',class_='story')
print(p_node.name, p_node.get_text())
Python 网页解析器的更多相关文章
- python 之网页解析器
一.什么是网页解析器 1.网页解析器名词解释 首先让我们来了解下,什么是网页解析器,简单的说就是用来解析html网页的工具,准确的说:它是一个HTML网页信息提取工具,就是从html网页中解析提取出“ ...
- Python 文本解析器
Python 文本解析器 一.课程介绍 本课程讲解一个使用 Python 来解析纯文本生成一个 HTML 页面的小程序. 二.相关技术 Python:一种面向对象.解释型计算机程序设计语言,用它可以做 ...
- 第6章 网页解析器和BeautifulSoup第三方插件
第一节 网页解析器简介作用:从网页中提取有价值数据的工具python有哪几种网页解析器?其实就是解析HTML页面正则表达式:模糊匹配结构化解析-DOM树:html.parserBeautiful So ...
- python3 爬虫五大模块之四:网页解析器
Python的爬虫框架主要可以分为以下五个部分: 爬虫调度器:用于各个模块之间的通信,可以理解为爬虫的入口与核心(main函数),爬虫的执行策略在此模块进行定义: URL管理器:负责URL的管理,包括 ...
- Python网页解析库:用requests-html爬取网页
Python网页解析库:用requests-html爬取网页 1. 开始 Python 中可以进行网页解析的库有很多,常见的有 BeautifulSoup 和 lxml 等.在网上玩爬虫的文章通常都是 ...
- Python HTML解析器BeautifulSoup(爬虫解析器)
BeautifulSoup简介 我们知道,Python拥有出色的内置HTML解析器模块——HTMLParser,然而还有一个功能更为强大的HTML或XML解析工具——BeautifulSoup(美味的 ...
- Python网页解析
续上篇文章,网页抓取到手之后就是解析网页了. 在Python中解析网页的库不少,我最开始使用的是BeautifulSoup,貌似这个也是Python中最知名的HTML解析库.它主要的特点就是容错性很好 ...
- 转:Python网页解析:BeautifulSoup vs lxml.html
转自:http://www.cnblogs.com/rzhang/archive/2011/12/29/python-html-parsing.html Python里常用的网页解析库有Beautif ...
- python——BS解析器
随机推荐
- 根据IP获取所在的国家城市
根据IP获取所在的国家城市 新浪的IP地址查询接口:http://int.dpool.sina.com.cn/iplookup/iplookup.php?format=js 新浪多地域测试方法:htt ...
- 左移和右移运算符<< >>
左移的符号为<< 首先来个简单的例子 求8左移两位的值 8<<2 首先 将十进制的8转为二进制的数 倒序输出----> 1000 1000 左移两位 ...
- C++重载>>和<<(输入输出运算符)
在C++中,标准库本身已经对左移运算符<<和右移运算符>>分别进行了重载,使其能够用于不同数据的输入输出,但是输入输出的对象只能是 C++ 内置的数据类型(例如 bool.in ...
- spring框架入门之一
一.什么是Spring框架 1.什么是Spring Spring框架是个一个全栈的框架.意思就是使用Spring的框架可以开发web层,service层还有dao层. 本质:Spring就是一个对象的 ...
- apache编译安装php后需要注意以下配置
安装后, 编辑apache配置文件 vi /usr/local/apache2/conf/httpd.conf 可以看到 LoadModule php7_module modules/libphp7. ...
- Golang字符串解析成数字
package main import ( "strconv" "fmt" ) func main() { // 使用ParseFloat解析浮点数,64是说明 ...
- Zookeeper集群方式安装
分布式安装部署 配置系统环境变量等 /etc/profile export JAVA_HOME=/opt/app/jdk1.8.0_181 #export CLASSPATH=.:${JAVA_HOM ...
- P1383 高级打字机
P1383 高级打字机 主席树 一发主席树解决. 插入操作十分显然. 撤销操作复制前面的版本就行. 询问操作十分显然. #include<iostream> #include<cst ...
- 快速阅读《QT5.9 c++开发指南》2
1.sample2_2 信号和槽 MFC中最让人印象深刻的就是"消息映射",这里有理由相信,"信号和槽"是这种功能的发扬和扩展.通过简单的 connect(ui ...
- 20145315何佳蕾《网络对抗》Web安全基础
20145315何佳蕾<网络对抗>Web安全基础 1.实验后回答问题 (1)SQL注入攻击原理,如何防御 SQL Injection:就是通过把SQL命令插入到Web表单递交或输入域名或页 ...