用where导致group by分组字段的索引失效
把两个单独的索引合并成一个组合索引,即把where条件字段的索引和group by的分组字段索引组合成一个。
如果分组的字段需要用函数处理,可以用索引函数
Generated Column(函数索引)
mysql5.7版本,函数索引用虚拟列,virtual是查询时在内存中计算,而store是计算好后存放在磁盘中。一般作为索引,默认用virtual。
语法:
<type> [ GENERATED ALWAYS ] AS ( <expression> ) [ VIRTUAL|STORED ] [ UNIQUE [KEY] ] [ [PRIMARY] KEY ] [ NOT NULL ] [ COMMENT <text> ]
修改table添加一个新列,由函数处理已有字段自动生成。
新建虚拟列
ALTER TABLE tblName ADD virtualField varchar(50) GENERATED ALWAYS AS (FROM_UNIXTIME(bus_remind.arrivingTimeStamp)) virtual;
删除虚拟列
alter table tblName drop column fieldName;
例子
组合索引如下

sql语句
SELECT
avg(arrivingBattery) AS battery
FROM
bus_remind
WHERE
parkingCode = ''
GROUP BY
DATE_FORMAT( FROM_UNIXTIME(arrivingTimeStamp ), '%Y-%m-%d %H:%i' )
explain结果

分析原因:
分组字段根据分钟分组(对字段进行函数处理)导致抛弃索引。
解决方案:
复合索引使用虚拟列技术,将虚拟列作为索引,Sql如下
/*创建*/
ALTER TABLE bus_remind ADD virtualArrivingTimeStamp char(16) GENERATED ALWAYS AS (DATE_FORMAT(FROM_UNIXTIME(arrivingTimeStamp),'%Y-%m-%d %H:%i')) VIRTUAL comment '来车时间函数索引列';
/*删除*/
alter table bus_remind drop column virtualArrivingTimeStamp
复合索引更改为(版本必须为5.7及以上)
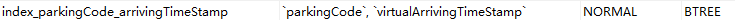
sql语句更改
SELECT
avg(arrivingBattery) AS battery
FROM
bus_remind
WHERE
parkingCode = ''
GROUP BY
virtualArrivingTimeStamp
explain结果

用where导致group by分组字段的索引失效的更多相关文章
- Group by 分组查询 实战
实战经历,由于本人在共享单车上班,我们的单车管理模块,可以根据单车号查询单车,但是单车号没有设置unique(独一无二约束),说以这就增加了单车号可能重复的风险,但是一般情况下,单车号是不会重复的,因 ...
- group by 多字段分组
在平时的开发任务中我们经常会用到MYSQL的GROUP BY分组, 用来获取数据表中以分组字段为依据的统计数据.比如有一个学生选课表,表结构如下: Table: Subject_Selection S ...
- group by多字段分组
在平时的开发任务中我们经常会用到MYSQL的GROUP BY分组, 用来获取数据表中以分组字段为依据的统计数据.比如有一个学生选课表,表结构如下: Table: Subject_Selection S ...
- python实现简易数据库之三——join多表连接和group by分组
上一篇里面我们实现了单表查询和top N查询,这一篇我们来讲述如何实现多表连接和group by分组. 一.多表连接 多表连接的时间是数据库一个非常耗时的操作,因为连接的时间复杂度是M*N(M,N是要 ...
- 关于MYSQL group by 分组按时间取最大值的实现方法!
类如 有一个帖子的回复表,posts( id , tid , subject , message , dateline ) , id 为 自动增长字段, tid为该回复的主题帖子的id(外键关联), ...
- join多表连接和group by分组
join多表连接和group by分组 上一篇里面我们实现了单表查询和top N查询,这一篇我们来讲述如何实现多表连接和group by分组. 一.多表连接 多表连接的时间是数据库一个非常耗时的操作, ...
- 利用GROUP_CONCAT和GROUP BY实现字段拼接
在开发过程中遇到这样的一个需求,通过GROUP BY分组归类后将同属性的字段进行拼接. 表结构为: id value a b c a b 需要得到结果: id value a,b,c a,b 一开始在 ...
- hive:数据库“行专列”操作---使用collect_set/collect_list/collect_all & row_number()over(partition by 分组字段 [order by 排序字段])
方案一:请参考<数据库“行专列”操作---使用row_number()over(partition by 分组字段 [order by 排序字段])>,该方案是sqlserver,orac ...
- 关于MYSQL group by 分组按时间取最大值的实现方法
类如 有一个帖子的回复表,posts( id , tid , subject , message , dateline ) , id 为 自动增长字段, tid为该回复的主题帖子的id(外键关联), ...
随机推荐
- Python3基础 list del 从内存中删除整个列表
Python : 3.7.0 OS : Ubuntu 18.04.1 LTS IDE : PyCharm 2018.2.4 Conda ...
- 【ContextLoaderListener】Web项目启动报错java.lang.ClassNotFoundException: ContextLoaderListener
错误原因: 进入到tomcat的部署路径.metadata\.plugins\org.eclipse.wst.server.core\tmp0\wtpwebapps\下检查了一下,发现工程部署后在WE ...
- Read.csv: some rows are missing
read.csv in R doesn't import all rows from csv file The OP indicates that the problem is caused by q ...
- 今天的任务--git练习
克隆远程仓库项目 从版本控制中选择git 填写地址和本地目录,test测试成功后点击clone 克隆完成回到主界面,点击open打开刚才克隆的项目 git操作 添加文件py1.html 打开命令行 新 ...
- SPOJ 687 REPEATS - Repeats
题意 给定字符串,求重复次数最多的连续重复子串 思路 后缀数组的神题 让我对着题解想了快1天 首先考虑一个暴力,枚举循环串的长度l,然后再枚举每个点i,用i和i+l匹配,如果匹配长度是L,这个循环串就 ...
- 怎么在父窗口调用它页面的iframe里面数据,进行操作?
注:在服务器下操作有效果,本地无效 document.getElementById("taskdetail1").contentWindow.test(a) document.ge ...
- HBase与列存储
传统的行存储和(HBase)列存储的区别 1.为什么要按列存储 列式存储(Columnar or column-based)是相对于传统关系型数据库的行式存储(Row-basedstorage)来说的 ...
- NodeJS 获取网页源代码
获取网页源代码 node 获取网页源代码 var http = require('http'); var url = "http://www.baidu.com/"; // 参数u ...
- Javascript 垃圾回收机制
转载于https://www.cnblogs.com/zhwl/p/4664604.html 一.垃圾回收的必要性 由于字符串.对象和数组没有固定大小,所有当他们的大小已知时,才能对他们进行动态的存储 ...
- vue--vuex
https://vuex.vuejs.org/ vuex是专为 vue.js 应用程序开发的 状态管理模式 采用集中式存储管理应用的所有组件状态 并以相应的规则保证状态以一种可预测的方式发生变化 vu ...