Group by 分组查询 实战
实战经历,由于本人在共享单车上班,我们的单车管理模块,可以根据单车号查询单车,但是单车号没有设置unique(独一无二约束),说以这就增加了单车号可能重复的风险,但是一般情况下,单车号是不会重复的,因为平台的单车都是人工录入的,但是二般情况下,就会出现,一旦出现,那么就shit了,很不幸,今天就出现了这个问题,“一个单车号,可以在单车管理模块查出来有两条记录”这个时候,我们就必须把出现这种问题的单车号,再次手动编辑改变,由于数据库里,单车管理表里有成千上万个单车,但是,都有哪一个单车号出现了两次或者多次(也就是单车号重复出现了)我们是不确定的,基于这个问题,总监说,小李扶着1-500单车号排查,小张扶着500-1000单车号排查....我想说一句:shit!
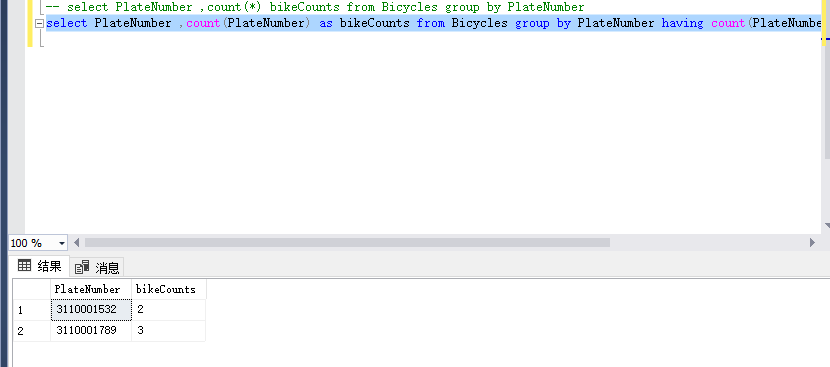
于是我写了一个分组查询,“根据单车号分组差单车出现的次数和单车号,把单车出线次数大于1的,都having筛选出来,这样这个问题就ok解决了”
//这是sql分组查询代码:
select PlateNumber ,count(PlateNumber) as bikeCounts from Bicycles group by PlateNumber having count(PlateNumber)>
这是效果图
由于很久没有写sql语句了,这些日子都是net core +ng.1.x ORM不带写sql的,感觉sql知识越来越淡薄,故,总结分享一下!
传授一下思想:
先排序在汇总
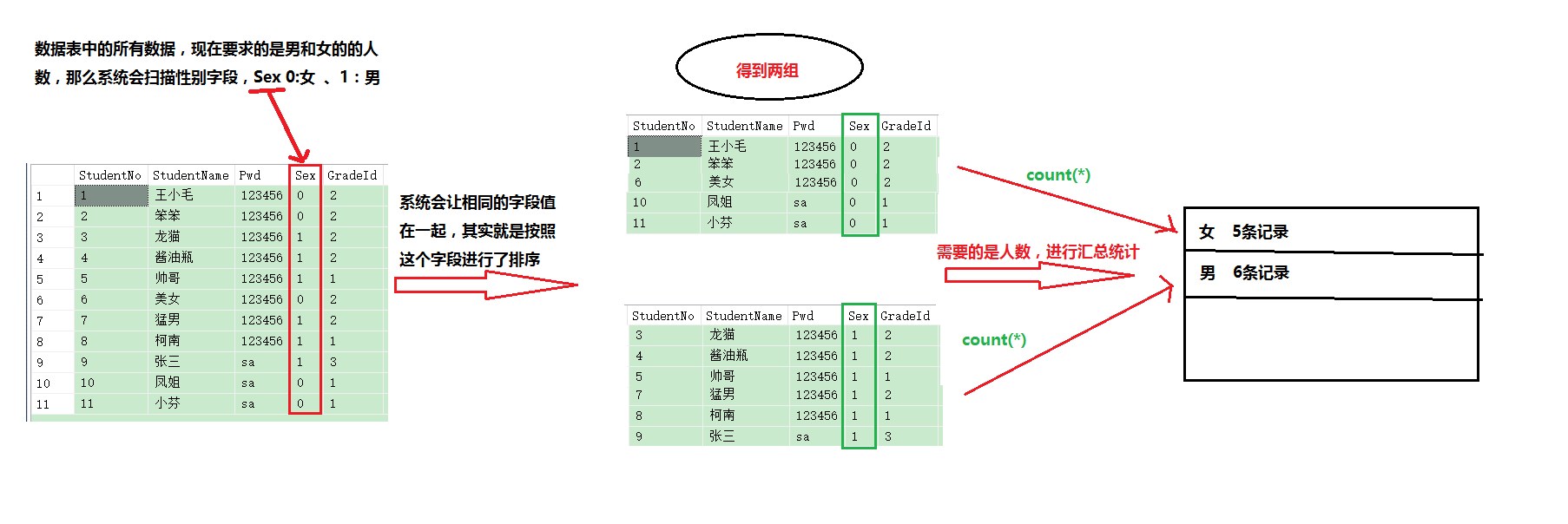
sql server里分组查询通常用于配合聚合函数,达到分类汇总统计的信息。而其分类汇总的本质实际上就是先将信息排序,排序后相同类别的信息会聚在一起,然后通过需求进行统计计算。
使用GROUP BY进行分组查询
实例演示
--查询男女生的人数
在没有学习分组查询之前,我们可以安装常规的思路解决查询需求:
select count(*) from student where sex='男'
select count(*) from student where sex='女'
那么现在又要个需要时,查询每个班级的总人数
如果按照常规解决查询,那么我们应该思考的是:
1.每个班级,我们并不知道在表里有哪些班级,那么我们where 后的条件如何写?
2.如果该表里有1000个班级,那么我难道要写一千条where查询语句?
面对这样的问题 sql server为我们准备了Group by 关键字实现分组查询
在使用介绍Group by关键字之前,我们先来看看系统实现分组查询的原理和逻辑:
映射成SQL语句:
select sex ,count(*) as 人数 from student group by sex这个简短的语句,经过上图的原理,应该要知道,第一步是先from查询表的所有信息,然后group by根据字段进行分组后在统计汇总
上面的案例是通过Count()函数进行统计,当然分组汇总还可以使用其他的聚合函数进行汇总。
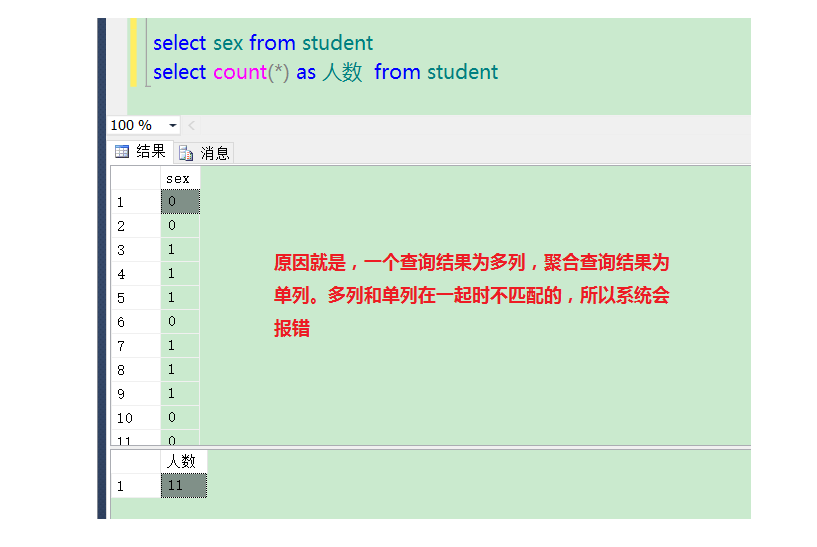
使用GROUP BY 语句注意事项一:
图中使用查询语句,包含一个字段和一个聚合函数为什么会报错呢?
原因,我们把两个字段分开来查询:
总结:为了保证完整性,系统约定俗成,在使用了聚合函数的查询语句中,除了聚合函数,可以在查询列表上,要出现其他字段,那么该字段就必须为分组字段,而且该字段一定要跟随在GROUP BY关键字后面。
与聚合函数一起出现在select后面进行查询的列,只有两种可能性:被聚合 、被分组
多列分组查询
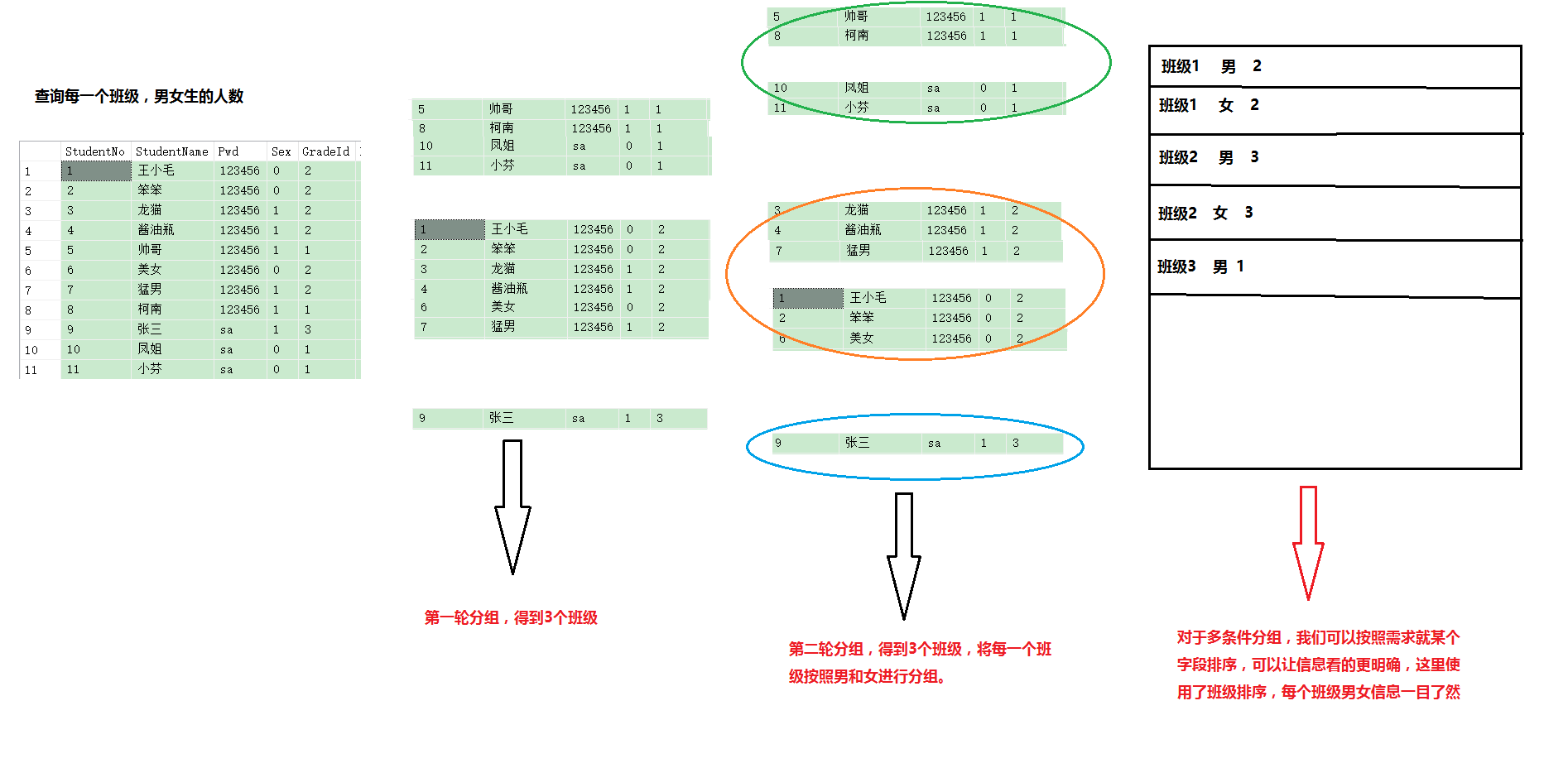
--实例需求,查询每一个班级,男女生的人数
分析:显然需求是两组,每一个班需要划分组,男女也需要分组
实现图解:
SQL语句:
select GradeId,sex,COUNT(*) from student group by GradeId,Sex order by GradeId经验:搞清楚需要分几组,搞清楚分组的顺序,一轮一轮的分,系统是等分组之后才会进行汇总信息
使用HAVING子句
演示示例:--查询每一个班级男女生的人数,同时只需要显示人数数量超过3人的记录
分析:此查询显然是对上一个示例的多列分组进行筛选。
试在这学的知识范围内来解决此查询需求。。。。
一、那么就按照我们学的where来进行筛选
结果如图:
这个错误告诉了我们:where里面不能出现聚合函数作为条件,失败!
二、既然不能使用聚合函数,那就给聚合函数取一个别名,让它当做一个列
结果如图:
错误原因:原因是where是对源数据进行筛选的,也就是对from 后面的表进行筛选,既然是源数据,那么where去源数据表里找一个别名字段,怎么可能会有!所以才会报错
让我们来探讨一下,这里为什么不能使用where
1.需求是对分组之后的数据集进行筛选,where只针对数据表原始数据筛选
2.where关键字显然只能出现一次,而且根据查询的顺序,是先执行where条件筛选后得到的结果集,在进行的group by分组
解决办法,使用HAVING关键字:
HAVING核心:是对分组统计之后的结果集,进行数据的筛选
SQL语句:
select GradeId,sex,COUNT(*) as renshu from student group by GradeId,Sex having count(*)>=3 order by GradeIdwhere和having的不同:where是对原始数据进行筛选,having是对分组时候的数据进行筛选
查询语句的执行顺序
在这里引出查询机制里对查询语句里的关键字的执行顺序
查询关键字家族成员
select top/distinct 字段列表 from 表列表 where 筛选条件 group by 分组字段列表 having 对分组之后得到的结果集筛选 order by 排序字段列表执行顺序:
1.from
2.where
3.group by
4.having
5.根据select 关键之后的要显示的字段,进行结果集显示
6.order by 对最终结果集进行排序
7.top/dictinct
觉得不错可以推荐一下哦!



Group by 分组查询 实战的更多相关文章
- 【mybatis】【mysql】mybatis查询mysql,group by分组查询报错:Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column
mybatis查询mysql,group by分组查询报错:Expression #1 of SELECT list is not in GROUP BY clause and contains no ...
- mysql group by分组查询后 查询个数
mysql group by分组查询后 查询个数2个方法随便你选 <pre>select count(distinct colA) from table1;</pre>< ...
- SQL group by分组查询(转)
本文导读:在实际SQL应用中,经常需要进行分组聚合,即将查询对象按一定条件分组,然后对每一个组进行聚合分析.创建分组是通过GROUP BY子句实现的.与WHERE子句不同,GROUP BY子句用于归纳 ...
- mysql group by分组查询
分组的SQL语句有2个: group by 和分组聚合函数实现 partition by (oracle和postgreSQL中的语句)功能 group by + having 组合赛选数据 注意:h ...
- SQL group by分组查询
本文导读:在实际SQL应用中,经常需要进行分组聚合,即将查询对象按一定条件分组,然后对每一个组进行聚合分析.创建分组是通过GROUP BY子句实现的.与WHERE子句不同,GROUP BY子句用于归纳 ...
- ysql常用sql语句(12)- group by 分组查询
测试必备的Mysql常用sql语句,每天敲一篇,每次敲三遍,每月一循环,全都可记住!! https://www.cnblogs.com/poloyy/category/1683347.html 前言 ...
- group by分组查询
有如下数据: 一个简单的分组查询的案例 按照部门编号deptno分组,统计每个部门的平均工资. select deptno,avg(sal) avgs from emp group by deptno ...
- oracle Group by 分组查询后,分页
------------恢复内容开始------------ 1.分页查询 select count(*) times,title from menulog group by title order ...
- mysql group by分组查询错误修改
select @@global.sql_mode;set @@sql_mode ='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR ...
随机推荐
- 集合框架map_DAY18
1:map集合(掌握) (1)Map集合存储的是键值对元素.键是唯一的,值可以重复. (2)Map和Collection的区别? A:Map是双列集合,存储的元素键值对,键唯一,值可以重复. B:Co ...
- chrome中Timeline的使用(译)
一.概括 Timeline面板包括以下四个部分: 控制面板.开始记录.停止记录.配置捕获信息: 概况.页面性能的整体概况: flame chart.直观展示cpu堆的情况.你能够看到三条虚线,蓝色的代 ...
- Centos iptables防火墙关闭启动详解
CentOS .0默认使用的是firewall作为防火墙,使用iptables必须重新设置一下 .直接关闭防火墙 systemctl stop firewalld.service #停止firewal ...
- 散列算法-SHA
一种生成信息摘要的算法.主要用于数据一致性和完整性的校验 SHA算法分很多版本,最大的分类是SHA-1和SHA-2.SHA-2包括很多子版本,SHA-224,SHA-256,SHA-384,SHA-5 ...
- Entity Framework 6 Recipes 2nd Edition(目录索引)
Chapter01. Getting Started with Entity Framework / 实体框架入门 1-1. A Brief Tour of the Entity Framework ...
- SpringBoot入门 (十三) WebSocket使用
本文记录在SpringBoot中使用WebSocket. 一 什么是WebSocket WebSocket是基于TCP协议的一种网络协议,它实现了浏览器与服务器全双工通信,支持客户端和服务端之间相互发 ...
- NAT介绍
NAT 即网络地址转换NAT作用:实现内网IP地址和公网IP地址之间的转换可以有效地缓解IP地址危机可以隐藏内网地址实现负载均衡实现内网和内网之间的通信 NAT分类:分类静态NAT:将内网IP地址一对 ...
- MySQL、Mariadb 复制原理
复制的作用 l 水平扩展 l 数据备份 l 数据分析 l 数据分布 l 高可用性 复制的工作原理 Mariadb的复制功能是基于binlog进行的.复制的工作主要是由主库上Master du ...
- 在ASP.NET MVC应用程序中随机获取一个字符串
在开发ASP.NET MVC应用程序时,有可能需要一个随机字符串,作为密码或是验证码等. 如果你需要的是SQL版本,可以参考<密码需要带特殊字符(二)>http://www.cnblogs ...
- Spring源码分析:非懒加载的单例Bean初始化过程(上)
上文[Spring源码分析]Bean加载流程概览,比较详细地分析了Spring上下文加载的代码入口,并且在AbstractApplicationContext的refresh方法中,点出了finish ...