【Hadoop学习之四】HDFS HA搭建(QJM)
环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk8
hadoop-3.1.1
由于NameNode对于整个HDFS集群重要性,为避免NameNode单点故障,在集群里创建2个或以上NameNode(不要超过5个),保证高可用。
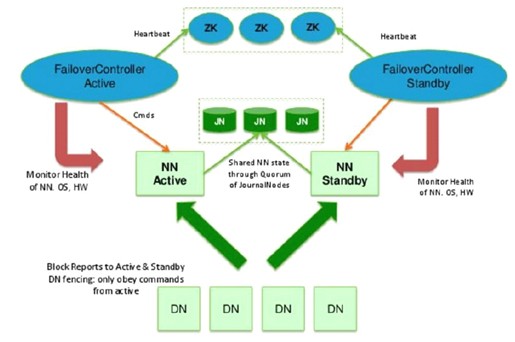
实现主备NameNode需要解决的问题:
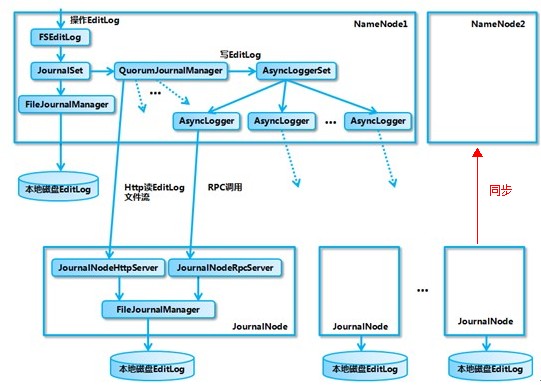
1、通过JournalNodes来保证Active NN与Standby NN之间的元数据同步
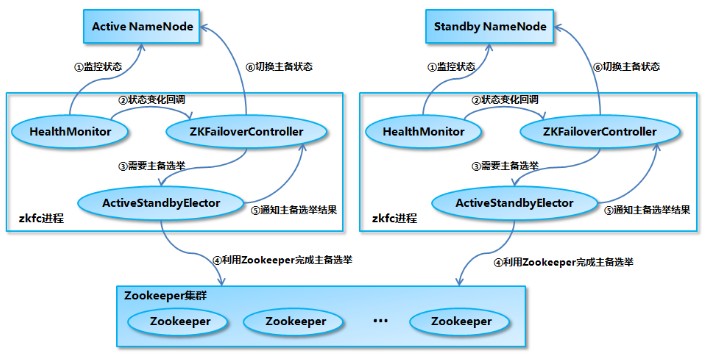
2、通过ZKFC来保证Active NN与Standby NN主备切换
3、DataNode会同时向Active NN与Standby NN上报数据块的位置信息
参考:
hdfs HA原理及安装
搭建HA集群部署节点清单:
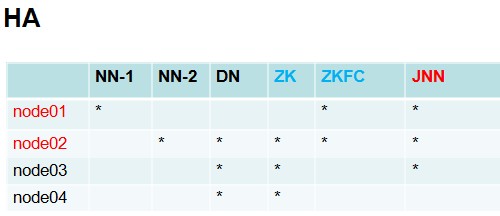
一、平台软件环境
1、平台:GNU/Linux
2、软件:jdk+免密登录
3、JAVA和Hadoop环境变量以及主机名设置
参考:【Hadoop学习之三】Hadoop全分布式安装
二、配置(node1-node4采用相同配置)
1、hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1..0_65
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
#设置ZKFC角色用户
export HDFS_ZKFC_USER=root
#设置JOURNALNODE角色用户
export HDFS_JOURNALNODE_USER=root
2、core-site.xml
<configuration>
<!--主节点通讯设置-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hdfscluster</value>
</property>
<!--元数据、Block存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/ha</value>
</property>
<!--静态目录用户-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!--zk集群-->
<property>
<name>ha.zookeeper.quorum</name>
<value>node2:2181,node3:2181,node4:2181</value>
</property>
</configuration>
3、hdfs-site.xml
(1)dfs.nameservices:namenode服务逻辑名称
(2)dfs.ha.namenodes.[nameservice ID] namenode清单,逗号分隔
(3)dfs.namenode.rpc-address.[nameservice ID].[name node ID] HDFS Client通过RPC访问HDFS
(4)dfs.namenode.http-address.[nameservice ID].[name node ID] webUI管理界面主机和端口
(5)dfs.namenode.shared.edits.dir JournalNodes元数据共享目录集群地址
(6)dfs.client.failover.proxy.provider.[nameservice ID] 故障转移的代理类
(7)dfs.ha.fencing.methods 两个namenode的隔离方法,避免脑裂局面
(原来的Active NN 可能由于网络、进程阻塞等原因暂时中断,此时ZKFC将Standby NameNode提升为 Active NN,等原来的Active NN网络或进程恢复后,又继续提供服务,这样就出现脑裂局面。
所以必需采取强制措施将SNN变成ANN之前,先要将原来的ANN变成SNN)
(8)dfs.ha.fencing.ssh.private-key-files 配置ssh私钥免密登录原ANN节点进行降级处理
(9)dfs.journalnode.edits.dir 配置journalnode共享元数据存放位置
(10)dfs.ha.automatic-failover.enabled 配置true支持故障自动转移
<configuration>
<!--副本数设置-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--NN集群逻辑名称-->
<property>
<name>dfs.nameservices</name>
<value>hdfscluster</value>
</property>
<!--NN集群节点清单-->
<property>
<name>dfs.ha.namenodes.hdfscluster</name>
<value>node1,node2</value>
</property>
<!--与客户端通讯端口-->
<property>
<name>dfs.namenode.rpc-address.hdfscluster.node1</name>
<value>node1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.hdfscluster.node2</name>
<value>node2:8020</value>
</property>
<!--WEBUI访问端口-->
<property>
<name>dfs.namenode.http-address.hdfscluster.node1</name>
<value>node1:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.hdfscluster.node2</name>
<value>node2:9870</value>
</property>
<!--journalnode地址-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1:8485;node2:8485;node3:8485/hdfscluster</value>
</property>
<!--故障转移代理类-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--采用ssh隔离-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!--采用私钥进行免密登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!--journalnode共享元数据存放位置-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/data/ha/journal</value>
</property>
<!--故障自动转移-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
4、workers DN节点
node2
node3
node4
将hadoop-env.sh、core-site.xml、hdfs-site.xml、workers分发至node2、node3、node4
[root@node1 hadoop]# scp hadoop-env.sh core-site.xml hdfs-site.xml workers node2:`pwd`
[root@node1 hadoop]# scp hadoop-env.sh core-site.xml hdfs-site.xml workers node3:`pwd`
[root@node1 hadoop]# scp hadoop-env.sh core-site.xml hdfs-site.xml workers node4:`pwd`
三、安装ZooKeeper
参考:zookeeper 安装以及集群搭建
四、启动
注意:启动HDFS之前一定要先启动ZK集群。
1、启动JournalNode守护程序
根据部署清单,在node1、node2、node3
[root@node1 hadoop]# hdfs --daemon start journalnode
[root@node2 hadoop]# hdfs --daemon start journalnode
[root@node3 hadoop]# hdfs --daemon start journalnode
[root@node1 hadoop]# jps
Jps
JournalNode
关闭:hdfs --daemon stop journalnode
查看journalnode共享元数据存放位置配置的路径dfs.journalnode.edits.dir下,会出现这个目录
[root@node1 ha]# ls
journal
2、格式化NameNode(集群首次搭建好之后需要格式化,只执行一次)
这里有两台NN,我们选择node1
[root@node1 /]# hdfs namenode -format
3、启动主NN
[root@node1 sbin]# hadoop-daemon.sh start namenode
或者
[root@node1 sbin]# hdfs --daemon start

4、备用NN 同步主NN信息
这里node2作为备机NN
[root@node2 sbin]# hdfs namenode -bootstrapStandby
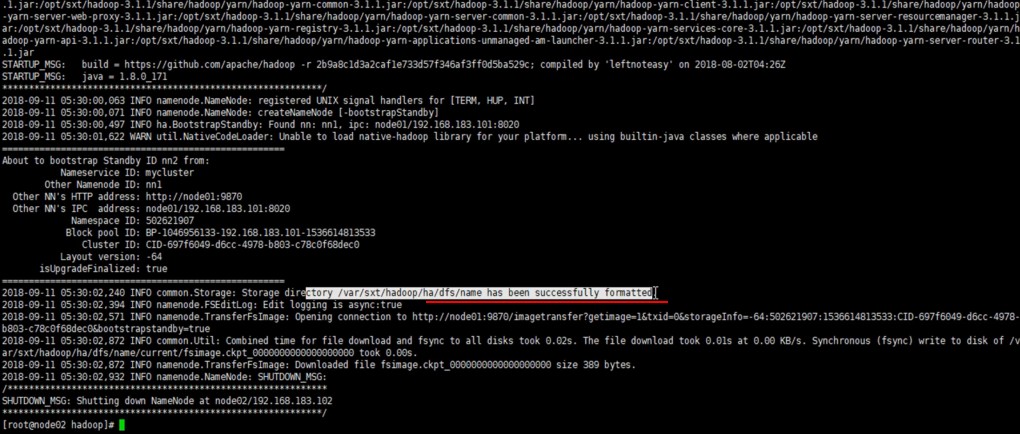
在hadoop.tmp.dir配置的目录下面会出现同步的目录:dfs
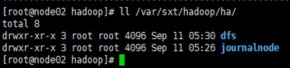
如果非HA转做HA时,需要在备机上执行:hdfs namenode -initializeSharedEdits 将主机原来的元数据信息同步到备机上
5、格式化ZK
在其中一台NN上执行命令:
[root@node1 sbin]# hdfs zkfc -formatZK
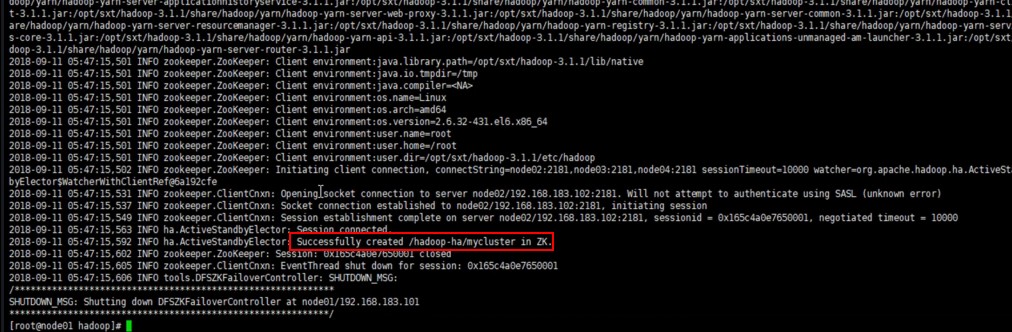
通过zkCli.sh客户端登录ZK集群,会看到生成了hadoop对应的集群节点
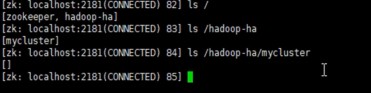
6、启动hadoop集群
在主节点NameNode启动集群,会在主和备NN上启动ZKFC守护进程(维护时,可以手动启动ZKFC:hdfs --daemon start zkfc)
[root@node1 sbin]# start-dfs.sh
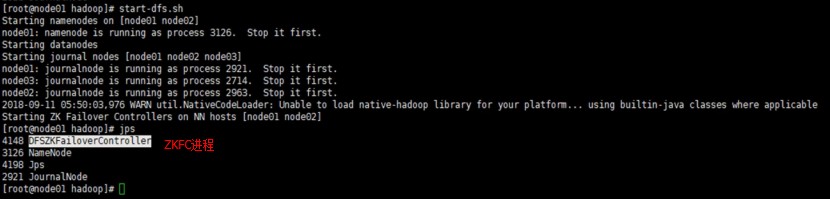
通过zkCli.sh查看节点:
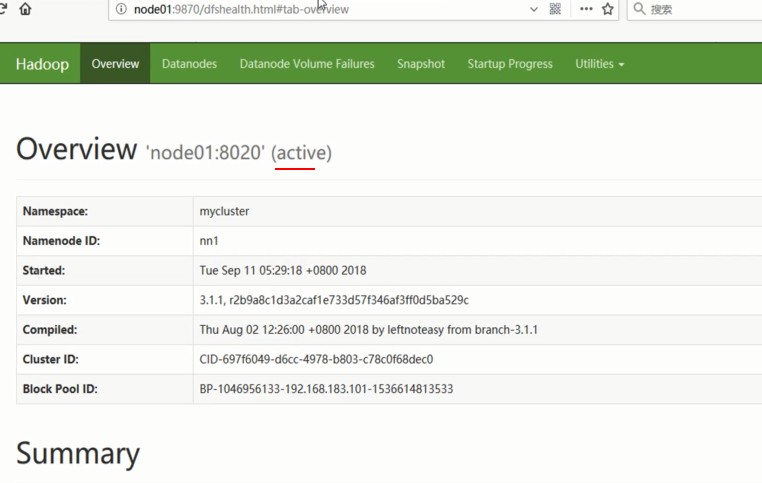
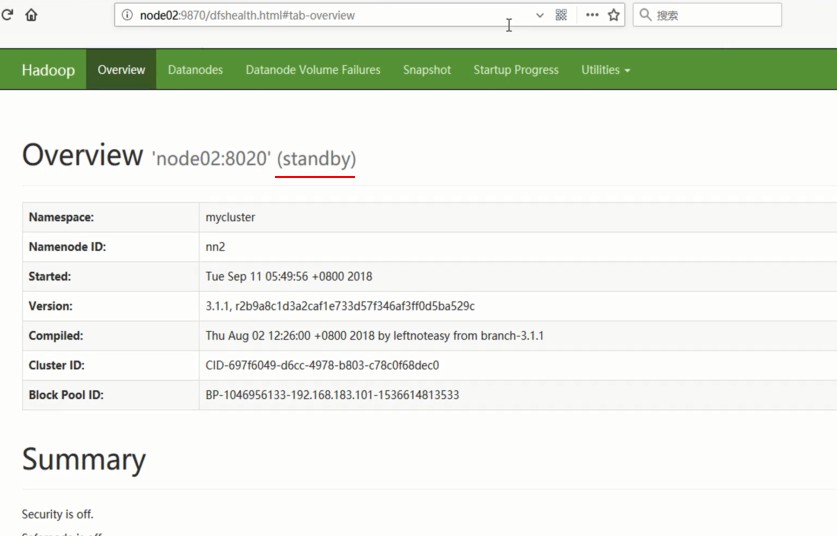
通过浏览器查看:
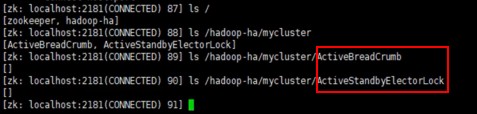
查看ZK中主节点抢占注册:
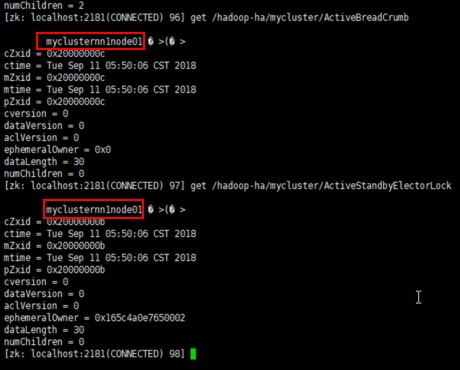
7、主备切换测试
(1)关闭Active NameNode
[root@node1 sbin]# hdfs --daemon stop namenode
关闭前:ANN:node1,SNN:node2
关闭后:ANN:node2,SNN:node1

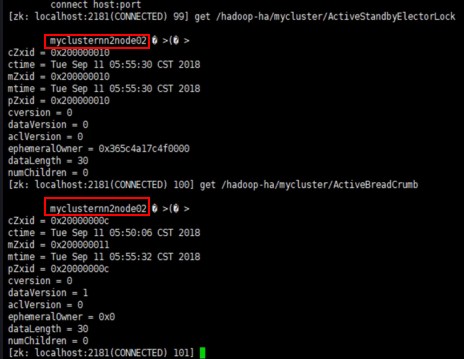
(2)启动刚才关闭的NameNode
[root@node1 sbin]# hdfs --daemon start namenode
启动前:ANN:node2,SNN:node1
启动后:ANN:node2,SNN:node1
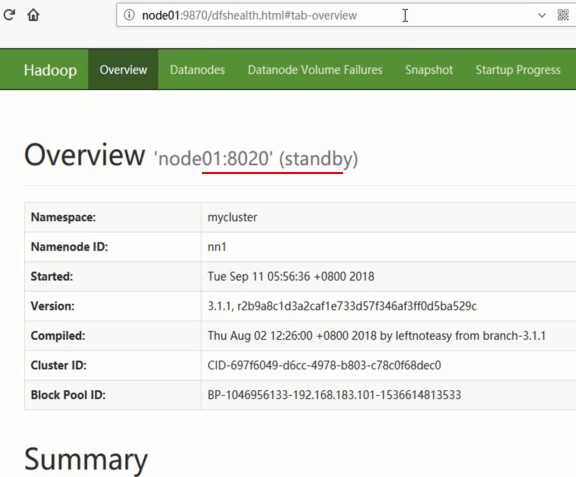
(3)关闭node2上的ZKFC
[root@node2 sbin]# hdfs --daemon stop zkfc
关闭前:ANN:node2,SNN:node1
关闭后:ANN:node1,SNN:node2
参考:
hadoop-3.1.1/hadoop-3.1.1/share/doc/hadoop/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
【Hadoop学习之四】HDFS HA搭建(QJM)的更多相关文章
- hadoop学习之HDFS
1.什么是大数据?什么是云计算?什么是hadoop? 大数据现在很火,到底什么是大数据,多大的数据才算大,一般而言对于TB级以上的数据我们成为大数据,对于这些数据它的价值在哪?大数据的价值就是我们大量 ...
- Hadoop 2.7.3 HA 搭建及遇到的一些问题
看了Hadoop的一个7天视频教程,里面给出了搭建的详细步骤,教程中是按2.4.1版本搭建的,我用的是2.7.3版本,好像没什么差别.下面是抄过来的,加了一点注释. hadoop2.0已经发布了稳定版 ...
- Hadoop 5、HDFS HA 和 YARN
Hadoop 2.0 产生的背景Hadoop 1.0 中HDFS和MapReduce存在高可用和扩展方面的问题 HDFS存在的问题 NameNode单点故障,难以用于在线场景 NameNode压力过大 ...
- hadoop学习(五)----HDFS的java操作
前面我们基本学习了HDFS的原理,hadoop环境的搭建,下面开始正式的实践,语言以java为主.这一节来看一下HDFS的java操作. 1 环境准备 上一篇说了windows下搭建hadoop环境, ...
- Hadoop学习笔记—HDFS
目录 搭建安装 三个核心组件 安装 配置环境变量 配置各上述三组件守护进程的相关属性 启停 监控和性能 Hadoop Rack Awareness yarn的NodeManagers监控 命令 hdf ...
- Hadoop学习笔记-HDFS命令
进入 $HADOOP/bin 一.文件操作 文件操作 类似于正常的linux操作前面加上“hdfs dfs -” 前缀也可以写成hadoop而不用hdfs,但终端中显示 Use of this scr ...
- hadoop学习笔记壹 --环境搭建及配置文件的修改
Hadoop生态和其他生态最大的不同之一就是“单一平台多种应用”的理念了. hadoop能解决是什么问题: 1.HDFS :海量数据存储 MapReduce: 海量数据分析 YARN :资源管理调 ...
- Hadoop学习笔记---HDFS
Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.HDFS能提供高吞吐 ...
- Hadoop组件之-HDFS(HA实现细节)
NameNode 高可用整体架构概述 在 Hadoop 1.0 时代,Hadoop 的两大核心组件 HDFS NameNode 和 JobTracker 都存在着单点问题,这其中以 NameNode ...
随机推荐
- 对称加密----AES和DES加密、解密
目前主流的加密方式有:(对称加密)AES.DES (非对称加密)RSA.DSA 调用AES/DES加密算法包最精要的就是下面两句话: Cipher cipher = Cipher.get ...
- 重读《深入理解Java虚拟机》四、虚拟机如何加载Class文件
1.Java语言的特性 Java代码经过编译器编译成Class文件(字节码)后,就需要虚拟机将其加载到内存里面执行字节码所定义的代码实现程序开发设定的功能. Java语言中类型的加载.连接(验证.准备 ...
- 第 7 章 Data 类型
目录 第 7 章 Data 类型 一.创建方式 二.转时间戳 其他 第 7 章 Data 类型 @(es5) 参考了: 阮一峰javascript的标准.<javascript高级教程> ...
- vue启动调试、启动编译的批处理
Rundev.bat cd %~dp0npm run dev RunBuild.bat cd %~dp0npm run build
- Python3学习之路~6.3 类变量 VS 实例变量
类变量 VS 实例变量 #Author:Zheng Na # 实例里面可以查询.增加.删除.修改实例变量 class Role: # 类名 # 类变量 name = '我是类name' n=1 n_l ...
- .NET 三层框架
1.三层架构 三层架构(3-tier architecture) 通常意义上的三层架构就是将整个业务应用划分为:表现层(Presentation layer).业务逻辑层(Business Logic ...
- 快学Scala 1
1. Scala解释器读到一个表达式,对它进行求值,将它打印出来,接着再继续读下一个表达式.这个过程被称作“读取-求值-打印-循环”,即REPL. 2. 从技术上来讲,scala程序并不是一个 ...
- maven配置本地仓库通用
只要在settings.xml文件中指定仓库就可以了,然后复制仓库到任何地方都可以使用,eclipse中指定一个settings.xml就可以了 仓库的位置是.locks所在目录
- 调试https接口
1. wireshark的 pre master key只能使用在浏览器上,现在mac电脑不支持chrome,只有firefox才有SSL的日志提供给wireshark. 2. wirshark不能解 ...
- SQL Server2008 R2 数据库镜像实施手册(双机)SQL Server2014同样适用
这篇文章主要介绍了SQL Server2008 R2 数据库镜像实施手册(双机)SQL Server2014同样适用,需要的朋友可以参考下 一.配置主备机 1. 服务器基本信息 主机名称为:HOST_ ...