Hadoop 5、HDFS HA 和 YARN
Hadoop 2.0 产生的背景
Hadoop 1.0 中HDFS和MapReduce存在高可用和扩展方面的问题
HDFS存在的问题
NameNode单点故障,难以用于在线场景
NameNode压力过大,内存受限,影响系统扩展
MapReduce存在问题
JobTracker 单点故障
JobTracker 压力过大,影响系统扩展
难以支持除MapReduce以外的计算框架如 Spark、Strom等;
Hadoop 2.x由 HDFS 、MapReduce、YARN三部分组成
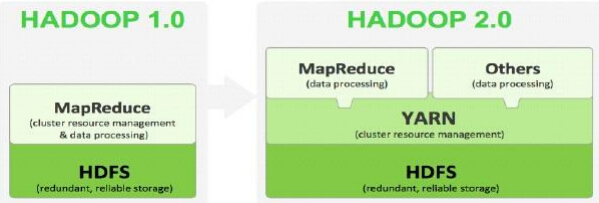
HDFS:NN Federation 、HA
MapReduce:运行在Yarn上的MR
Yarn:资源管理系统
HDFS 2.x
解决HDFS 1.0 中单点故障和内在受限问题
解决单点在故障
HDFS HA :通过主备NameNode解决,如果主NameNode发生在故障,则切换到备用的NameNode上
解决内存受限问题
HDFS Federation(联邦)
水平扩展,支持多个NameNode
每个NameNode分管一部分目录
所有NameNode共享所有的DataNode存储资源
HDFS 2.x 仅是架构眼生变化,使用方式不变
对HDFS使用者透明
HDFS 1.x 中的命令和API仍可以使用
HDFS 2.0 HA
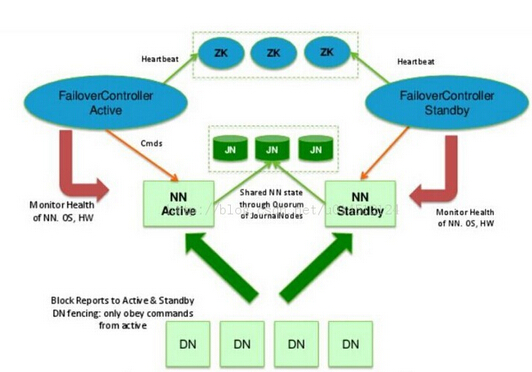
主备NameNode
解决单点故障
主NameNode对外提供服务,备NameNode同步主NameNode的元数据,以待切换
所有DataNode同时向两个NameNode汇报block信息(如上图)

JournaNodes集群 :三台或三台以上的 JournaNode节点(与Zookeeper节点相同),JournaNodes 接管了Secondary的工作和NameNode edits的工作 ,将edits 日志文件放在JournaNodes 所有节点上,所有的和NameNode相关的写入修改操作日志都存放在JournaNodes 每个节点上的edits上,在JournaNodes 节点上实现fsimage的合并工作 ,然后再由JournaNodes 将新的fsimage分发给主备NameNode;
两种切换选择
手动切换:通过命令实现主备之间的切换,可以用HDFS升级等 场合
自动切换:基于Zookeeper的实现
基于Zookeeper自动切换方案
Zookeeper Failover Controller :监控NameNode健康状态,并向Zookeeper注册NameNode,NameNode挂掉之后,ZKFC为NameNode竞争锁,获取ZKFC锁的NameNode变为Active;
HDFS 2.x Federation
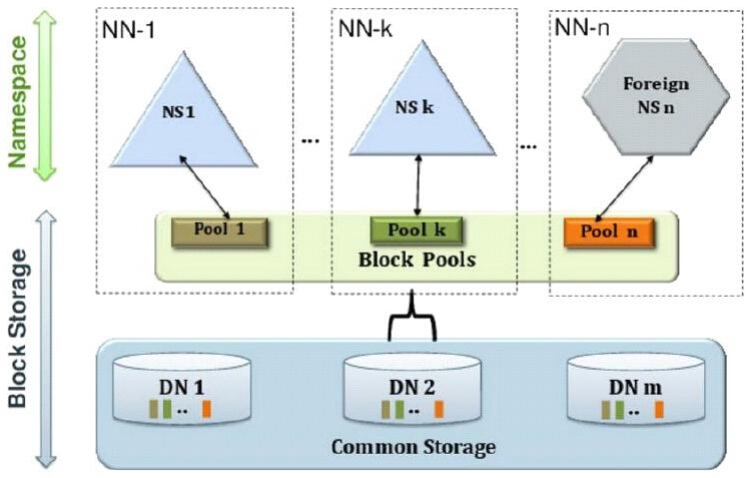
通过多个NameNode/NameSpace 把元数据的存储和管理分散到多个节点中,使NameNode/NameSpace可以通过增加机器来进行水平扩展。
能把单个NameNode的负载分散到多个节点中,在HDFS数据规模较大的时候不会降低HDFS的性能。可能通过多个NameSpace来隔离不同类型的应用,把不同类型应用的HDFS元数据的存储和管理分派到不同的NameNode中。
为了水平扩展namenode,federation使用了多个独立的namenode/namespace。这些namenode之间是联合的,也就是说,他们之间相互独立且不需要互相协调,各自分工,管理自己的区域。分布式的datanode被用作通用的数据块存储存储设备。每个datanode要向集群中所有的namenode注册,且周期性地向所有namenode发送心跳和块报告,并执行来自所有namenode的命令。
一个block pool由属于同一个namespace的数据块组成,每个datanode可能会存储集群中所有block pool的数据块。
每个block pool内部自治,也就是说各自管理各自的block,不会与其他block pool交流。一个namenode挂掉了,不会影响其他namenode。
某个namenode上的namespace和它对应的block pool一起被称为namespace volume。它是管理的基本单位。当一个namenode/nodespace被删除后,其所有datanode上对应的block pool也会被删除。当集群升级时,每个namespace volume作为一个基本单元进行升级。
相关文章:http://dongxicheng.org/mapreduce/hdfs-federation-introduction/
YARN 资源管理系统
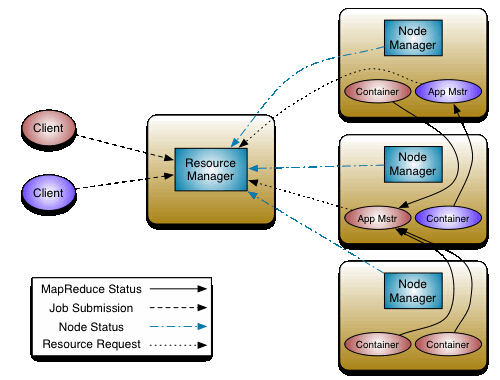
YARN : Yet Another Resource Negotiator;
Hadoop 2.0 新引入的资源管理系统,直接从MRv1演化而来的。
核心思想:将MRv1中的JobTracker的资源管理和任务调度两个功能分开,分加盟由ResourceManager和ApplicationMaster进程实现。
ResourceManager : 负责整个集群的资源管理和调度
ApplicationMaster : 负责应用程序相关的事务,比如任务调度、任务监控和容错等
YARN的引入,使得多个计算框架可运行在一个集群中
每个应用对应一个ApplicationMaster
目前多个计算框架可以运行在Yarn上,比如MapReduce、Spark、Storm等。
yarn相关文章:http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/
MapReduce On YARN
MapReduce On YARN : MRv2
将MapReduce作业直接运行在YARN上,而不是由JobTracker和TaskTarcker构建的MRv系统中
基本功能模块
YARN : 负责资源管理和调度
MRAppMaster : 负责任务切分、任务调度、任务监控和容错等
MapTask/ReduceTask :任务驱动引擎与MRv1一致
每个MapReduce作业对尖一个MRAppMaster
MRAppMaster任务调度
YARN将资源分配给MRAppMaster
MRAppMaster进一步将资源分配给内部的任务
MRAppMaster容错
失败后,由YARN重新启动
任务失败后,MRAppMaster重新申请资源
HDFS HA高可用集群搭建:http://www.cnblogs.com/raphael5200/p/5154325.html
Hadoop 5、HDFS HA 和 YARN的更多相关文章
- Apache版本的Hadoop HA集群启动详细步骤【包括Zookeeper、HDFS HA、YARN HA、HBase HA】(图文详解)
不多说,直接上干货! 1.先每台机器的zookeeper启动(bigdata-pro01.kfk.com.bigdata-pro02.kfk.com.bigdata-pro03.kfk.com) 2. ...
- hadoop(二):hdfs HA原理及安装
早期的hadoop版本,NN是HDFS集群的单点故障点,每一个集群只有一个NN,如果这个机器或进程不可用,整个集群就无法使用.为了解决这个问题,出现了一堆针对HDFS HA的解决方案(如:Linux ...
- Hadoop2.2.0--Hadoop Federation、Automatic HA、Yarn完全分布式集群结构
Hadoop有很多的上场时间,与系统上线.手头的事情略少.So,抓紧时间去通过一遍Hadoop2在下面Hadoop联盟(Federation).Hadoop2可用性(HA)及Yarn的全然分布式配置. ...
- 大数据入门第十天——hadoop高可用HA
一.HA概述 1.引言 正式引入HA机制是从hadoop2.0开始,之前的版本中没有HA机制 2.运行机制 实现高可用最关键的是消除单点故障 hadoop-ha严格来说应该分成各个组件的HA机制——H ...
- Apache hadoop namenode ha和yarn ha ---HDFS高可用性
HDFS高可用性Hadoop HDFS 的两大问题:NameNode单点:虽然有StandbyNameNode,但是冷备方案,达不到高可用--阶段性的合并edits和fsimage,以缩短集群启动的时 ...
- Hadoop 学习笔记 (十) hadoop2.2.0 生产环境部署 HDFS HA Federation 含Yarn部署
其他的配置跟HDFS-HA部署方式完全一样.但JournalNOde的配置不一样>hadoop-cluster1中的nn1和nn2和hadoop-cluster2中的nn3和nn4可以公用同样的 ...
- Hadoop组件之-HDFS(HA实现细节)
NameNode 高可用整体架构概述 在 Hadoop 1.0 时代,Hadoop 的两大核心组件 HDFS NameNode 和 JobTracker 都存在着单点问题,这其中以 NameNode ...
- Hadoop 学习笔记 (九) hadoop2.2.0 生产环境部署 HDFS HA部署方法
step1:将安装包hadoop-2.2.0.tar.gz存放到某一个目录下,并解压 step2:修改解压后的目录中的文件夹/etc/hadoop下的xml配置文件(如果文件不存在,则自己创建) 包括 ...
- Hadoop 2、配置HDFS HA (高可用)
前提条件 先搭建 http://www.cnblogs.com/raphael5200/p/5152004.html 的环境,然后在其基础上进行修改 一.安装Zookeeper 由于环境有限,所以在仅 ...
随机推荐
- ajax+json+java
1.首先下载json所以依赖的包, Json-lib 最新版 json-lib-2.3-jdk15.jar,其官方网站是:http://json-lib.sourceforge.net/可以直接dow ...
- Paxos算法深入分析
在分布式系统设计领域,Paxos可谓是最重要一致性的算法.Google的大牛们称 All working protocols for asynchronous consensus we have ...
- C# LiNq的语法以及常用的扩展方法
首先先来扯一下,这篇博文是我第一次写的,主要是我的一些摘录,希望对大家有所帮助. Linq的基础 •LINQ(读音link):Linq To SQL(过时).Linq To Object.Linq T ...
- WPF学习记录1:ListView的一个模板
在网上找的一个模板,放在这里,作为笔记,收集 <ListView Grid.Column=" Name="ListmuLu" > <ListView.I ...
- Reverse Linked List II java
public static ListNode reverseBetween(ListNode head, int m, int n) { ListNode pre=head,current=head, ...
- C++中把string转成char
c_str函数的返回值是const char*的,不能直接赋值给char*, c++语言提供了两种字符串实现,其中较原始的一种只是字符串的c语言实现. 与C语言的其他部分一样,它在c+的所有实现中可用 ...
- 计算两个集合的交集数字(java)
循环判断2个数组 将相同的公共元素复制到新数组中即可 import java.util.Arrays; public class count_same_number { public static i ...
- C#制作简易屏保(转)
C#制作简易屏保[原创] 原始网址: http://www.cnblogs.com/drizzlecrj/archive/2006/10/06/522182.html 2006-10-06 16:25 ...
- RtlInitUnicodeString、IoCreateDevice、IoCreateSymbolicLink、IoDeleteDevice 四个 API 驱动函数的使用
要解释"驱动对象",就得先从 DriverEntry() 说起: 做过C语言开发的都知道程序是从 main() 函数开始执行.在进行 Windows 驱动程序开发的时候没有 mai ...
- BullseyeCoverage:代码覆盖率。
1,安装和使用步骤 阅读READER文档.并安装(非常简单,README中有详细指令说明) 配置环境:同样可以阅读相关文档. 增加PATH环境变量.需要注意,此路径需要增加在PATH的最前列.即< ...