『计算机视觉』经典RCNN_其一:从RCNN到Faster-RCNN
一、目标检测
1、两个任务
目标检测可以拆分成两个任务:识别和定位
图像识别(classification)
输入:图片
输出:物体的类别
评估方法:准确率

定位(localization)
输入:图片
输出:方框在图片中的位置(x,y,w,h)
评估方法:检测评价函数 intersection-over-union ( IOU )

对于识别任务,卷积神经网络可以很好的帮助我们完成,但是定位任务则更加麻烦一些,我们接下来讨论一下定位任务的解决思路。
2、两种思路
看做回归问题
我们需要预测出(x,y,w,h)四个参数的值,从而得出方框的位置。

步骤1:
• 先解决简单问题, 搭一个识别图像的神经网络
• 在AlexNet VGG GoogleLenet上fine-tuning一下

步骤2:
• 在上述神经网络的尾部展开(也就说CNN前面保持不变,我们对CNN的结尾处作出改进:加了两个头:“分类头”和“回归头”)
• 成为classification + regression模式

步骤3:
• Regression那个部分用欧氏距离损失
• 使用SGD训练
步骤4:
• 预测阶段把2个头部拼上
• 完成不同的功能
这里需要进行两次fine-tuning
第一次在ALexNet上做,第二次将头部改成regression head,前面不变,做一次fine-tuning
Regression的部分加在哪?
有两种处理方法:
• 加在最后一个卷积层后面(如VGG)
• 加在最后一个全连接层后面(如R-CNN)
regression太难做了,应想方设法转换为classification问题。
regression的训练参数收敛的时间要长得多,所以上面的网络采取了用classification的网络来计算出网络共同部分的连接权值。
取图像窗口
• 还是刚才的classification + regression思路
• 我们预先划好不同大小的“框”
• 让框出现在不同的位置,得出这个框的判定得分
• 取得分最高的那个框
左上角的黑框:得分0.5

右上角的黑框:得分0.75

左下角的黑框:得分0.6

右下角的黑框:得分0.8

根据得分的高低,我们选择了右下角的黑框作为目标位置的预测。
注:有的时候也会选择得分最高的两个框,然后取两框的交集作为最终的位置预测。
如何选区候选框?
取不同的框,依次从左上角扫到右下角。
总结一下思路:
对一张图片,用各种大小的框(遍历整张图片)将图片截取出来,输入到CNN,然后CNN会输出这个框的得分(classification)以及这个框图片对应的x,y,h,w(regression)。

这方法实在太耗时间了,做个优化。
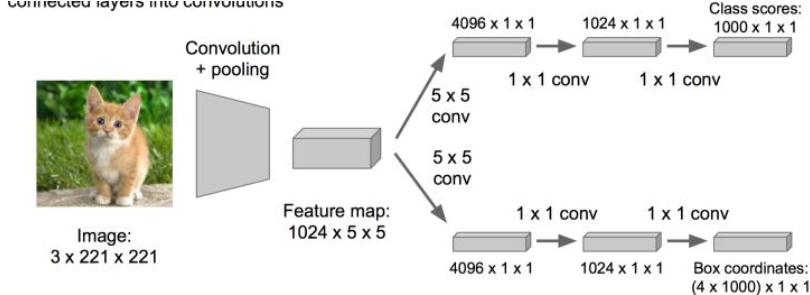
原来网络是这样的(overfeat的全卷积结构思路):

优化成这样:把全连接层改为卷积层,这样可以提提速。
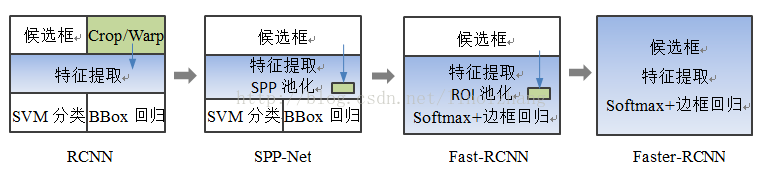
二、RCNN谱系
1、R-CNN
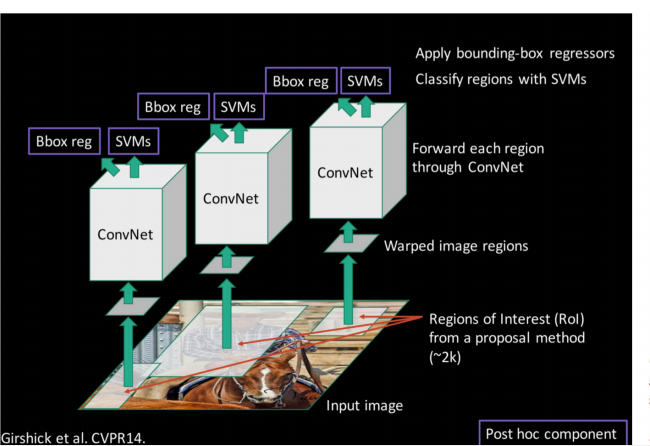
(1)输入测试图像;
(2)利用selective search 算法在图像中从上到下提取2000个左右的Region Proposal;
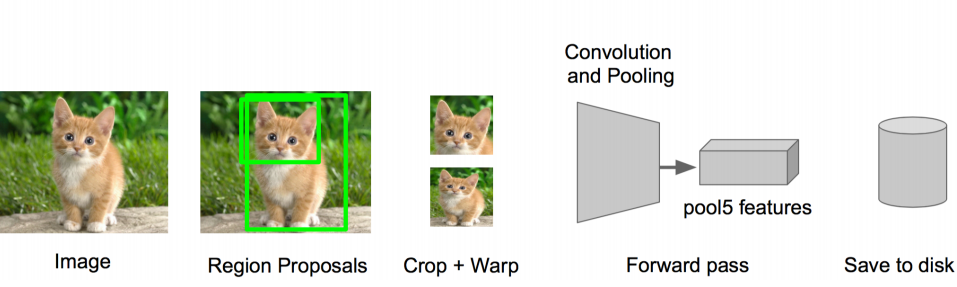
(3)将每个Region Proposal缩放(warp)成227*227的大小并输入到CNN,将CNN的fc7层的输出作为特征(原文会funtune如下图);


(4)将每个Region Proposal提取的CNN特征输入到SVM进行分类(原文将特征保存到磁盘,再分别使用SVM处理,如下图);

(5)对于SVM分好类的Region Proposal做边框回归,用Bounding box回归值校正原来的建议窗口,生成预测窗口坐标.


缺陷
(1) 训练分为多个阶段,步骤繁琐:微调网络+训练SVM+训练边框回归器;
(2) 训练耗时,占用磁盘空间大;5000张图像产生几百G的特征文件;
(3) 速度慢:使用GPU,VGG16模型处理一张图像需要47s;
(4) 测试速度慢:每个候选区域需要运行整个前向CNN计算;
(5) SVM和回归是事后操作,在SVM和回归过程中CNN特征没有被学习更新.
2、FAST-RCNN

(1)输入测试图像;
(2)利用selective search 算法在图像中从上到下提取2000个左右的建议窗口(Region Proposal);
(3)将整张图片输入CNN,进行特征提取;
(4)把建议窗口映射到CNN的最后一层卷积feature map上;
(5)通过RoI pooling层使每个建议窗口生成固定尺寸的feature map;
(6)利用Softmax Loss(探测分类概率) 和Smooth L1 Loss(探测边框回归)对分类概率和边框回归(Bounding box regression)联合训练.
相比R-CNN,主要两处不同
(1) 最后一层卷积层后加了一个ROI pooling layer;
(2) 损失函数使用了多任务损失函数(multi-task loss),将边框回归直接加入到CNN网络中训练
改进
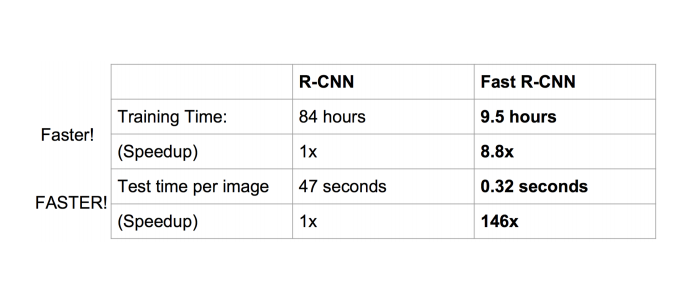
测试时速度慢:R-CNN把一张图像分解成大量的建议框,每个建议框拉伸形成的图像都会单独通过CNN提取特征.实际上这些建议框之间大量重叠,特征值之间完全可以共享,造成了运算能力的浪费.
FAST-RCNN将整张图像归一化后直接送入CNN,在最后的卷积层输出的feature map上,加入建议框信息,使得在此之前的CNN运算得以共享.
效果提升明显
3、FASTER -RCNN
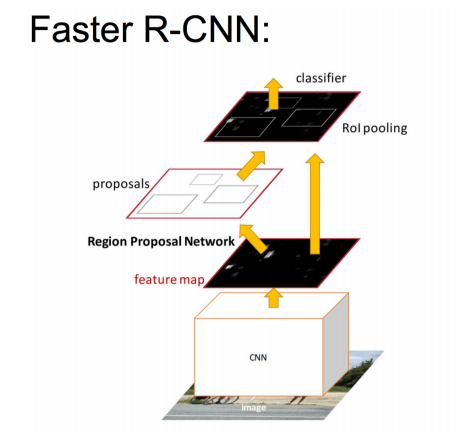
(1)输入测试图像;
(2)将整张图片输入CNN,进行特征提取;
(3)用RPN生成建议窗口(proposals),每张图片保留约300个建议窗口;
(4)把建议窗口映射到CNN的最后一层卷积feature map上;
(5)通过RoI pooling层使每个RoI生成固定尺寸的feature map;
(6)利用Softmax Loss(探测分类概率) 和Smooth L1 Loss(探测边框回归)对分类概率和边框回归(Bounding box regression)联合训练.
相比FAST-RCNN,主要两处不同
(1)使用RPN(Region Proposal Network)代替原来的Selective Search方法产生建议窗口;
(2)产生建议窗口的CNN和目标检测的CNN共享
改进
快速产生建议框:FASTER-RCNN创造性地采用卷积网络自行产生建议框,并且和目标检测网络共享卷积网络,使得建议框数目从原有的约2000个减少为300个,且建议框的质量也有本质的提高.
RPN简介
• 在feature map上滑动窗口
• 建一个神经网络用于物体分类+框位置的回归
• 滑动窗口的位置提供了物体的大体位置信息
• 框的回归提供了框更精确的位置
PRN的构成和SSD中特征层的处理极为相似。

放到整体网络中如下,
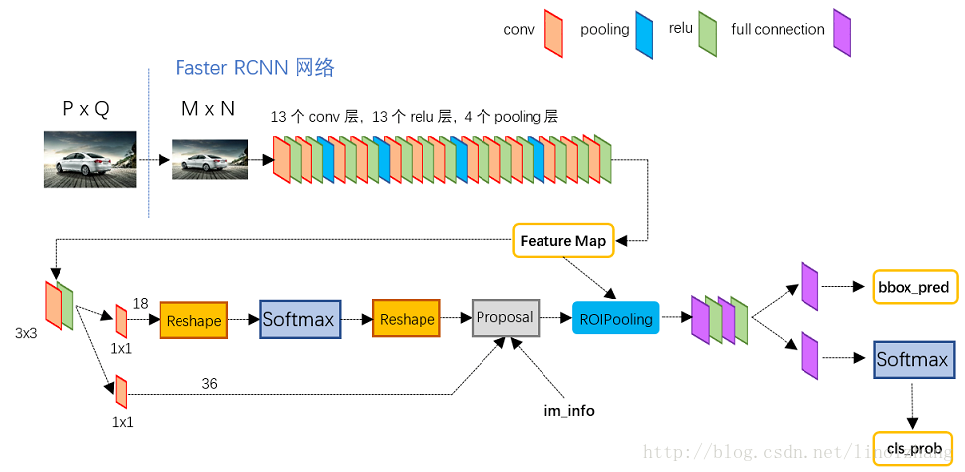
使用3*3的滑窗,每个滑动窗口位置生成9个候选窗口(不同尺度、不同宽高),对应36个坐标、18个分类。
训练过程中,
1)丢弃跨越边界的anchor;
2)与样本重叠区域大于0.7的anchor标记为前景,重叠区域小于0.3的标定为背景;
与FastRCNN类似。目标分类只需要区分候选框内特征为前景或者背景。 边框回归确定更精确的目标位置,基本网络结构如下图所示:
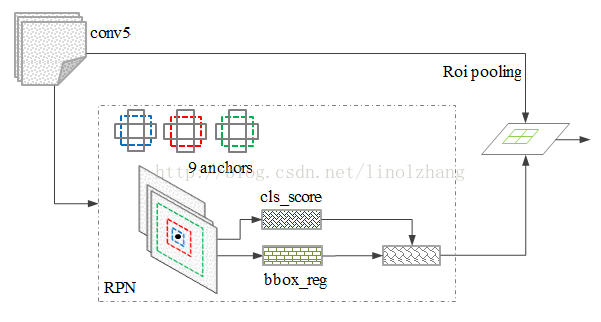
故一个网络,四个损失函数;
• RPN calssification(anchor good.bad)
• RPN regression(anchor->propoasal)
• Fast R-CNN classification(over classes)
• Fast R-CNN regression(proposal ->box)

4、回顾演进路线
附一、回归/微调的对象是什么?
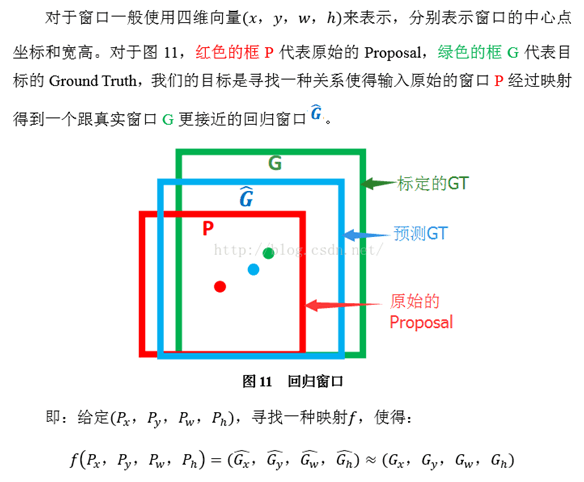
(4) Bounding-box regression(边框回归)
那么经过何种变换才能从图11中的窗口P变为窗口呢?比较简单的思路就是:
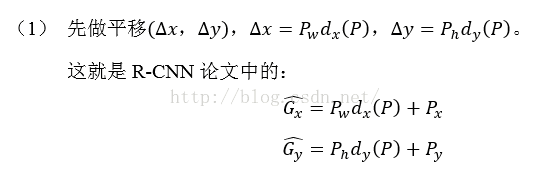

注意:只有当Proposal和Ground
Truth比较接近时(线性问题),我们才能将其作为训练样本训练我们的线性回归模型,否则会导致训练的回归模型不work(当Proposal跟GT离得较远,就是复杂的非线性问题了,此时用线性回归建模显然不合理).这个也是G-CNN:
an Iterative Grid Based Object
Detector多次迭代实现目标准确定位的关键.
线性回归就是给定输入的特征向量X,学习一组参数W,使得经过线性回归后的值跟真实值Y(Ground Truth)非常接近.即.那么Bounding-box中我们的输入以及输出分别是什么呢?


附录二、损失函数设计
在计算Loss值之前,作者设置了anchors的标定方法.正样本标定规则:
1) 如果Anchor对应的reference box与ground truth的IoU值最大,标记为正样本;
2) 如果Anchor对应的reference box与ground truth的IoU>0.7,标记为正样本.事实上,采用第2个规则基本上可以找到足够的正样本,但是对于一些极端情况,例如所有的Anchor对应的reference box与groud truth的IoU不大于0.7,可以采用第一种规则生成.
3) 负样本标定规则:如果Anchor对应的reference box与ground truth的IoU<0.3,标记为负样本.
4) 剩下的既不是正样本也不是负样本,不用于最终训练.
5) 训练RPN的Loss是有classification loss (即softmax loss)和regression loss (即L1 loss)按一定比重组成的.
计算softmax loss需要的是anchors对应的groundtruth标定结果和预测结果,计算regression loss需要三组信息:
i. 预测框,即RPN网络预测出的proposal的中心位置坐标x,y和宽高w,h;
ii. 锚点reference box:
之前的9个锚点对应9个不同scale和aspect_ratio的reference boxes,每一个reference boxes都有一个中心点位置坐标x_a,y_a和宽高w_a,h_a;
iii. ground truth:标定的框也对应一个中心点位置坐标x*,y*和宽高w*,h*.因此计算regression loss和总Loss方式如下:

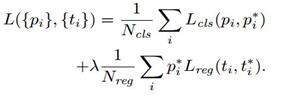
『计算机视觉』经典RCNN_其一:从RCNN到Faster-RCNN的更多相关文章
- 『计算机视觉』经典RCNN_其二:Faster-RCNN
项目源码 一.Faster-RCNN简介 『cs231n』Faster_RCNN 『计算机视觉』Faster-RCNN学习_其一:目标检测及RCNN谱系 一篇讲的非常明白的文章:一文读懂Faster ...
- 『计算机视觉』Mask-RCNN
一.Mask-RCNN流程 Mask R-CNN是一个实例分割(Instance segmentation)算法,通过增加不同的分支,可以完成目标分类.目标检测.语义分割.实例分割.人体姿势识别等多种 ...
- 『计算机视觉』FPN:feature pyramid networks for object detection
对用卷积神经网络进行目标检测方法的一种改进,通过提取多尺度的特征信息进行融合,进而提高目标检测的精度,特别是在小物体检测上的精度.FPN是ResNet或DenseNet等通用特征提取网络的附加组件,可 ...
- 『计算机视觉』Mask-RCNN_从服装关键点检测看KeyPoints分支
下图Github地址:Mask_RCNN Mask_RCNN_KeyPoints『计算机视觉』Mask-RCNN_论文学习『计算机视觉』Mask-RCNN_项目文档翻译『计算机视觉』Mas ...
- 『计算机视觉』Mask-RCNN_训练网络其二:train网络结构&损失函数
Github地址:Mask_RCNN 『计算机视觉』Mask-RCNN_论文学习 『计算机视觉』Mask-RCNN_项目文档翻译 『计算机视觉』Mask-RCNN_推断网络其一:总览 『计算机视觉』M ...
- 『计算机视觉』Mask-RCNN_训练网络其一:数据集与Dataset类
Github地址:Mask_RCNN 『计算机视觉』Mask-RCNN_论文学习 『计算机视觉』Mask-RCNN_项目文档翻译 『计算机视觉』Mask-RCNN_推断网络其一:总览 『计算机视觉』M ...
- 『计算机视觉』Mask-RCNN_锚框生成
Github地址:Mask_RCNN 『计算机视觉』Mask-RCNN_论文学习 『计算机视觉』Mask-RCNN_项目文档翻译 『计算机视觉』Mask-RCNN_推断网络其一:总览 『计算机视觉』M ...
- 『计算机视觉』Mask-RCNN_推断网络其六:Mask生成
一.Mask生成概览 上一节的末尾,我们已经获取了待检测图片的分类回归信息,我们将回归信息(即待检测目标的边框信息)单独提取出来,结合金字塔特征mrcnn_feature_maps,进行Mask生成工 ...
- 『计算机视觉』Mask-RCNN_推断网络其四:FPN和ROIAlign的耦合
一.模块概述 上节的最后,我们进行了如下操作获取了有限的proposal, # [IMAGES_PER_GPU, num_rois, (y1, x1, y2, x2)] # IMAGES_PER_GP ...
随机推荐
- keySet,entrySet用法 以及遍历map的用法
Set<K> keySet() //返回值是个只存放key值的Set集合(集合中无序存放的)Set<Map.Entry<K,V>> entrySet() //返回映 ...
- 订单BOM、销售BOM、标准BOM
订单BOM.销售BOM.标准BOM 訂單BOM: 是實際生產時用的BOM, 在標準BOM和銷售BOM基礎上增減物料的BOM銷售BOM: 是為特定客戶設定的BOM, 在主檔數據層次上的BOM, 在生 ...
- UVa 11488 超级前缀集合(Trie的应用)
https://vjudge.net/problem/UVA-11488 题意: 给定一个字符串集合S,定义P(s)为所有字符串的公共前缀长度与S中字符串个数的乘积.比如P( {000, 001, 0 ...
- vs里32位项目和64位项目的区别
由于操作系统内存分配的不同,导致软件开发过程中,需要编译不同版本的软件. 1.编译程序根据需要选择不同的编译环境. x86和win32为32位程序,x64为64位程序,可以选择不同的编译条件形成不同位 ...
- iPhone 尺寸 iPhonex
http://tool.lanrentuku.com/guifan/ui.html 这是本人复制的链接,,如有不适用,,请;联系本人删除链接,,谢谢. iPhone x尺寸 1125x2436@3x ...
- 【一】php 基础知识
1 php标记,<?php php代码 ?> 2 注释:代码的解释和说明 多行注释 /**/ 单行注释 //.# 3“.”连接符 echo "hello".date(& ...
- PostMan做接口自动化测试
try{ var jsonData = pm.response.json(); } catch (e) { console.log("No body"); } pm.environ ...
- [转]fatal error LNK1112: 模块计算机类型“X86”与目标计算机类型“x64”冲突
来自--------------------- 原文:https://blog.csdn.net/qtbmp/article/details/7273191?utm_source=copy win7 ...
- Eclipse使用之将Git项目转为Maven项目, ( 注意: 最后没有pom.xml文件的, 要转化下 )
Eclipse使用之将Git项目转为Maven项目(全图解) 2017年08月11日 09:24:31 阅读数:427 1.打开Eclipse,File->Import 2.Git->Pr ...
- EditText取消焦点
EditText取消焦点: 在父容器添加: android:focusable="true" android:focusableInTouchMode="true&quo ...