【机器学习】--鲁棒性调优之L1正则,L2正则
一、前述
鲁棒性调优就是让模型有更好的泛化能力和推广力。
二、具体原理
1、背景

第一个更好,因为当把测试集带入到这个模型里去。如果测试集本来是100,带入的时候变成101,则第二个模型结果偏差很大,而第一个模型偏差不是很大。
2、目的
鲁棒性就是为了让w参数也就是模型变小,但不是很小。所以引出了 L1和L2正则。
L1和L2的使用就是让w参数减小的使用就是让w参数减小。
L1正则,L2正则的出现原因是为了推广模型的泛化能力。相当于一个惩罚系数。

3、具体使用
L1正则:Lasso Regression
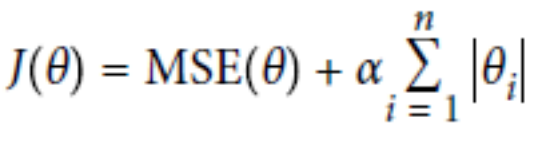
L2正则:Ridge Regression

总结:
经验值 MSE前系数为1 ,L1 , L2正则前面系数一般为0.4~0.5 更看重的是准确性。
L2正则会整体的把w变小。
L1正则会倾向于使得w要么取1,要么取0 ,稀疏矩阵 ,可以达到降维的角度。
ElasticNet函数(把L1正则和L2正则联合一起):

总结:
1.默认情况下选用L2正则。
2.如若认为少数特征有用,可以用L1正则。
3.如若认为少数特征有用,但特征数大于样本数,则选择ElasticNet函数。
4、在保证正确率的情况下加上正则。
5、如果把lamda设置成0,就只看准确率。
6、如果把lamda设置大些,就看中推广能力。
7、L1倾向于使得w要么取1,要么取0 稀疏编码 可以降维
8、L2倾向于使得w整体偏小 岭回归 首选
4、图示
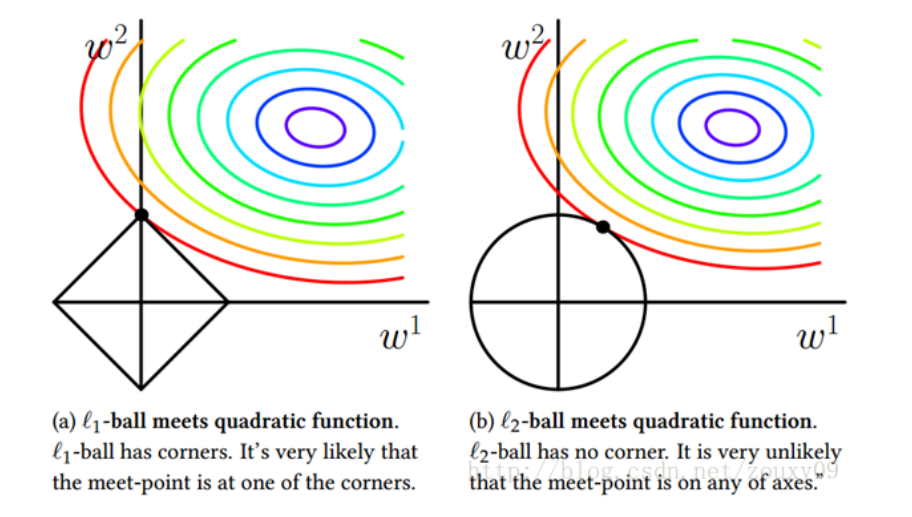
左边是L1正则+基本损失函数
右边是L2正则+基本损失函数
中间部分是圆心,损失函数最小,与正则函数相交,则既要满足基本函数,也要满足L1,L2正则,则损失函数增大了。
w1,w2等等与基本函数相交,则w1,w2都在[0,1]之间。
三、代码演示
代码一:L1正则
# L1正则
import numpy as np
from sklearn.linear_model import Lasso
from sklearn.linear_model import SGDRegressor X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1) lasso_reg = Lasso(alpha=0.15)
lasso_reg.fit(X, y)
print(lasso_reg.predict(1.5)) sgd_reg = SGDRegressor(penalty='l1')
sgd_reg.fit(X, y.ravel())
print(sgd_reg.predict(1.5))
代码二:L2正则
# L2正则
import numpy as np
from sklearn.linear_model import Ridge
from sklearn.linear_model import SGDRegressor X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1) #两种方式第一种岭回归
ridge_reg = Ridge(alpha=1, solver='auto')
ridge_reg.fit(X, y)
print(ridge_reg.predict(1.5))#预测1.5的值
#第二种 使用随机梯度下降中L2正则
sgd_reg = SGDRegressor(penalty='l2')
sgd_reg.fit(X, y.ravel())
print(sgd_reg.predict(1.5))
代码三:Elastic_Net函数
# elastic_net函数
import numpy as np
from sklearn.linear_model import ElasticNet
from sklearn.linear_model import SGDRegressor X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
#两种方式实现Elastic_net
elastic_net = ElasticNet(alpha=0.1, l1_ratio=0.5)
elastic_net.fit(X, y)
print(elastic_net.predict(1.5)) sgd_reg = SGDRegressor(penalty='elasticnet')
sgd_reg.fit(X, y.ravel())
print(sgd_reg.predict(1.5))
【机器学习】--鲁棒性调优之L1正则,L2正则的更多相关文章
- 大白话5分钟带你走进人工智能-第十四节过拟合解决手段L1和L2正则
第十四节过拟合解决手段L1和L2正则 第十三节中, ...
- 大白话5分钟带你走进人工智能-第十五节L1和L2正则几何解释和Ridge,Lasso,Elastic Net回归
第十五节L1和L2正则几何解释和Ridge,Lasso,Elastic Net回归 上一节中我们讲解了L1和L2正则的概念,知道了L1和L2都会使不重要的维度权重下降得多,重要的维度权重下降得少,引入 ...
- 机器学习:模型泛化(L1、L2 和弹性网络)
一.岭回归和 LASSO 回归的推导过程 1)岭回归和LASSO回归都是解决模型训练过程中的过拟合问题 具体操作:在原始的损失函数后添加正则项,来尽量的减小模型学习到的 θ 的大小,使得模型的泛化能力 ...
- L1与L2正则(转)
概念: L0范数表示向量中非零元素的个数:NP问题,但可以用L1近似代替. L1范数表示向量中每个元素绝对值的和: L1范数的解通常是稀疏性的,倾向于选择:1. 数目较少的一些非常大的值 2. 数目 ...
- 机器学习中规范化项:L1和L2
规范化(Regularization) 机器学习中几乎都可以看到损失函数后面会添加一个额外项,常用的额外项一般有两种,一般英文称作ℓ1-norm和ℓ2-norm,中文称作L1正则化和L2正则化,或者L ...
- 【笔记】简谈L1正则项L2正则和弹性网络
L1,L2,以及弹性网络 前情提要: 模型泛化与岭回归与LASSO 正则 ridge和lasso的后面添加的式子的格式上其实和MSE,MAE,以及欧拉距离和曼哈顿距离是非常像的 虽然应用场景不同,但是 ...
- L1和L2正则
https://blog.csdn.net/jinping_shi/article/details/52433975
- 【机器学习】--线性回归中L1正则和L2正则
一.前述 L1正则,L2正则的出现原因是为了推广模型的泛化能力.相当于一个惩罚系数. 二.原理 L1正则:Lasso Regression L2正则:Ridge Regression 总结: 经验值 ...
- 机器学习(二十三)— L0、L1、L2正则化区别
1.概念 L0正则化的值是模型参数中非零参数的个数. L1正则化表示各个参数绝对值之和. L2正则化标识各个参数的平方的和的开方值. 2.问题 1)实现参数的稀疏有什么好处吗? 一个好处是可以简化 ...
随机推荐
- 比较集合List<T>集合,前后多了哪些数据,少了哪些数据Except
1.少了哪些数据 private List<int> GetRoleIdListReduce(List<int> roleIdListOld, List<int> ...
- Dubbo中服务消费者和服务提供者之间的请求和响应过程
服务提供者初始化完成之后,对外暴露Exporter.服务消费者初始化完成之后,得到的是Proxy代理,方法调用的时候就是调用代理. 服务消费者经过初始化之后,得到的是一个动态代理类,InvokerIn ...
- vector作为函数返回值
在实际的操作中,我们经常会碰到需要返回一序列字符串或者一列数字的时候,以前会用到数组来保存这列的字符串或者数字,现在我们可以用vector来保存这些数据.但是当数据量很大的时候使用vector效率就比 ...
- loj548 「LibreOJ β Round #7」某少女附中的体育课
这道题好神啊!!! 发现这题就是定义了一种新的卷积,然后做k+1次卷积. 这里我们就考虑构造一个变换T,使得$T(a) \cdot T(b) =T(a∘b)$,这里是让向量右乘这个转移矩阵. 于是我们 ...
- 在CentOS 7中启动/停止/重启服务
RHEL/CentOS 7.0中一个最主要的改变,就是切换到了systemd.它用于替代红帽企业版Linux前任版本中的SysV和Upstart,对系统和服务进行管理.systemd兼容SysV和Li ...
- Django基础四<二>(OneToMany和 ManyToMany,ModelForm)
上一篇博文是关于setting.py文件数据库的配置以及model与数据库表关系,实现了通过操作BlogUser,把BlogUser的信息存入后台数据库中.实际开发中有许多东西是相互联系的,除了数据的 ...
- MIP技术进展月报第3期:MIP小姐姐听说,你想改改MIP官网?
一. 官网文档全部开源 MIP 是一项永久的开源的项目,提供持续优化的解决方案,当然官网也不能例外.从现在开始,任何人都可以在 MIP 官网贡献文档啦! GitHub 上,我们已经上传了 <官网 ...
- Spring里的Async注解实现异步操作
异步执行一般用来发送一些消息数据,数据一致性不要求太高的场景,对于spring来说,它把这个异步进行了封装,使用一个注解就可以实现. 用法 程序启动时开启@EnableAsync注解 建立新的类型,建 ...
- 【转载】Docker+Kubernetes 干货文章精选
主要涉及到以下关键字: K8S.Docker.微服务.安装.教程.网络.日志.存储.安全.工具.CI/CD.分布式.实践.架构等: 以下盘点2018年一些精选优质文章! 漫画形式: 漫画:小黄人学 S ...
- ab性能测试工具的使用
一.什么是ab ab,即Apache Benchmark,是一种用于测试Apache超文本传输协议(HTTP)服务器的工具. ab命令会创建很多的并发访问线程,模拟多个访问者同时对某一URL地址进行访 ...