cAdvisor+Prometheus+Grafana监控docker
cAdvisor+Prometheus+Grafana监控docker
一、cAdvisor(需要监控的主机都要安装)
官方地址:https://github.com/google/cadvisor
CAdvisor是谷歌开发的用于分析运行中容器的资源占用和性能指标的开源工具。CAdvisor是一个运行时的守护进程,负责收集、聚合、处理和输出运行中容器的信息。
注意在查找相关资料后发现这是最新版cAdvisor的bug,换成版本为google/cadvisor:v0.24.1 就ok了,映射主机端口默认是8080,可以修改。
sudo docker run \
--volume=/:/rootfs:ro \
--volume=/var/run:/var/run:ro \
--volume=/sys:/sys:ro \
--volume=/var/lib/docker/:/var/lib/docker:ro \
--volume=/dev/disk/:/dev/disk:ro \
--publish=8090:8080 \
--detach=true \
--name=cadvisor \
google/cadvisor:v0.24.1
cAdvisor exposes a web UI at its port:
http://<hostname>:<port>/
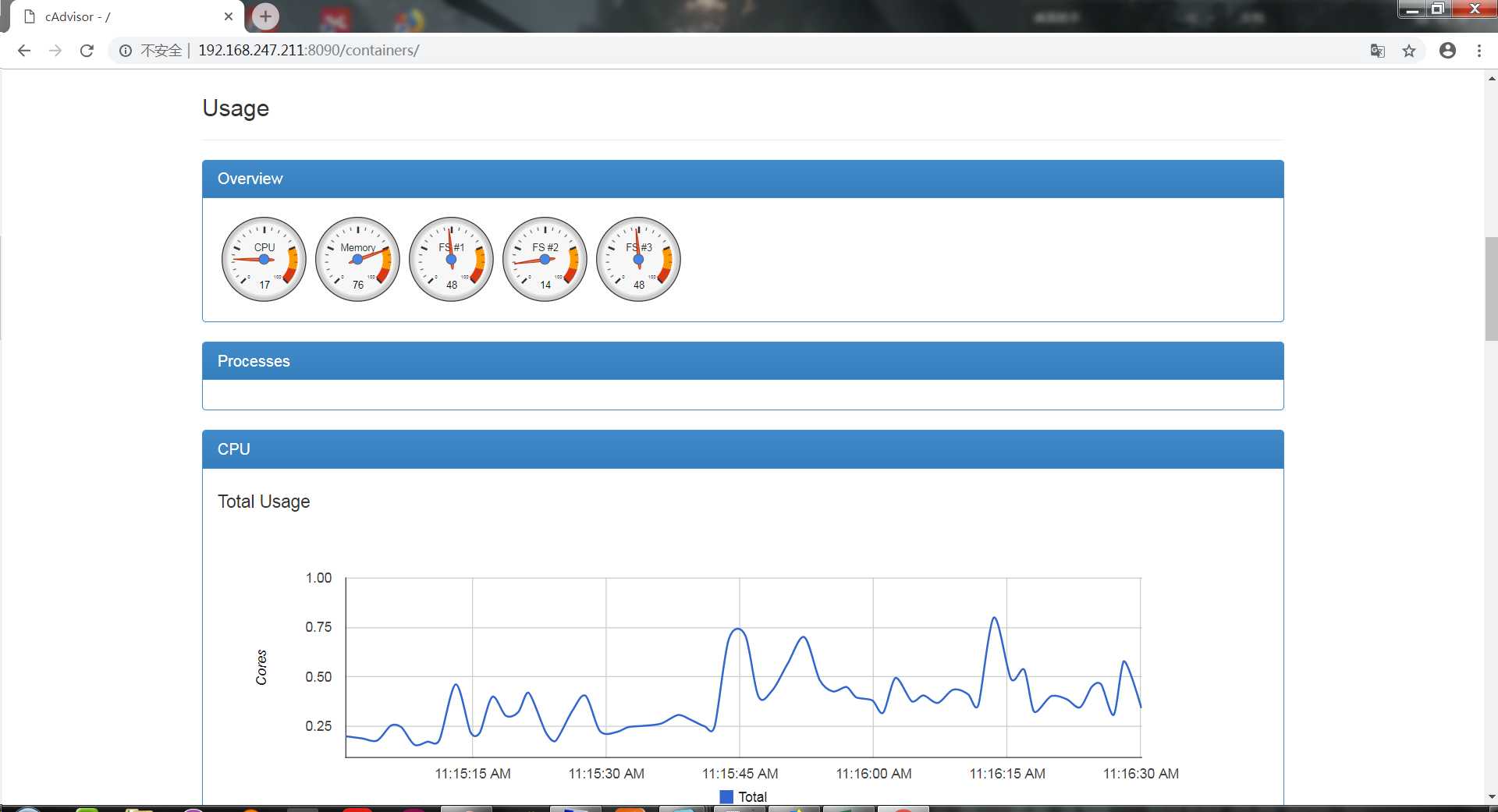
下图为cAdvisor的web界面,数据实时刷新但是不能存储。
查看json格式
http://192.168.247.212:8090/metrics
二、Prometheus
官方地址:https://prometheus.io/
随着容器技术的迅速发展,Kubernetes 已然成为大家追捧的容器集群管理系统。Prometheus 作为生态圈 Cloud Native Computing Foundation(简称:CNCF)中的重要一员,其活跃度仅次于 Kubernetes, 现已广泛用于 Kubernetes 集群的监控系统中。本文将简要介绍 Prometheus 的组成和相关概念,并实例演示 Prometheus 的安装,配置及使用,以便开发人员和云平台运维人员可以快速的掌握 Prometheus。
Prometheus 简介
Prometheus 是一套开源的系统监控报警框架。它启发于 Google 的 borgmon 监控系统,由工作在 SoundCloud 的 google 前员工在 2012 年创建,作为社区开源项目进行开发,并于 2015 年正式发布。2016 年,Prometheus 正式加入 Cloud Native Computing Foundation,成为受欢迎度仅次于 Kubernetes 的项目。
作为新一代的监控框架,Prometheus 具有以下特点:
强大的多维度数据模型:
- 时间序列数据通过 metric 名和键值对来区分。
- 所有的 metrics 都可以设置任意的多维标签。
- 数据模型更随意,不需要刻意设置为以点分隔的字符串。
- 可以对数据模型进行聚合,切割和切片操作。
- 支持双精度浮点类型,标签可以设为全 unicode。
灵活而强大的查询语句(PromQL):在同一个查询语句,可以对多个 metrics 进行乘法、加法、连接、取分数位等操作。
易于管理: Prometheus server 是一个单独的二进制文件,可直接在本地工作,不依赖于分布式存储。
高效:平均每个采样点仅占 3.5 bytes,且一个 Prometheus server 可以处理数百万的 metrics。
使用 pull 模式采集时间序列数据,这样不仅有利于本机测试而且可以避免有问题的服务器推送坏的 metrics。
可以采用 push gateway 的方式把时间序列数据推送至 Prometheus server 端。
可以通过服务发现或者静态配置去获取监控的 targets。
有多种可视化图形界面。
易于伸缩。
需要指出的是,由于数据采集可能会有丢失,所以 Prometheus 不适用对采集数据要 100% 准确的情形。但如果用于记录时间序列数据,Prometheus 具有很大的查询优势,此外,Prometheus 适用于微服务的体系架构
Prometheus 组成及架构
Prometheus 生态圈中包含了多个组件,其中许多组件是可选的:
- Prometheus Server: 用于收集和存储时间序列数据。
- Client Library: 客户端库,为需要监控的服务生成相应的 metrics 并暴露给 Prometheus server。当 Prometheus server 来 pull 时,直接返回实时状态的 metrics。
- Push Gateway: 主要用于短期的 jobs。由于这类 jobs 存在时间较短,可能在 Prometheus 来 pull 之前就消失了。为此,这次 jobs 可以直接向 Prometheus server 端推送它们的 metrics。这种方式主要用于服务层面的 metrics,对于机器层面的 metrices,需要使用 node exporter。
- Exporters: 用于暴露已有的第三方服务的 metrics 给 Prometheus。
- Alertmanager: 从 Prometheus server 端接收到 alerts 后,会进行去除重复数据,分组,并路由到对收的接受方式,发出报警。常见的接收方式有:电子邮件,pagerduty,OpsGenie, webhook 等。一些其他的工具。
Prometheus 架构图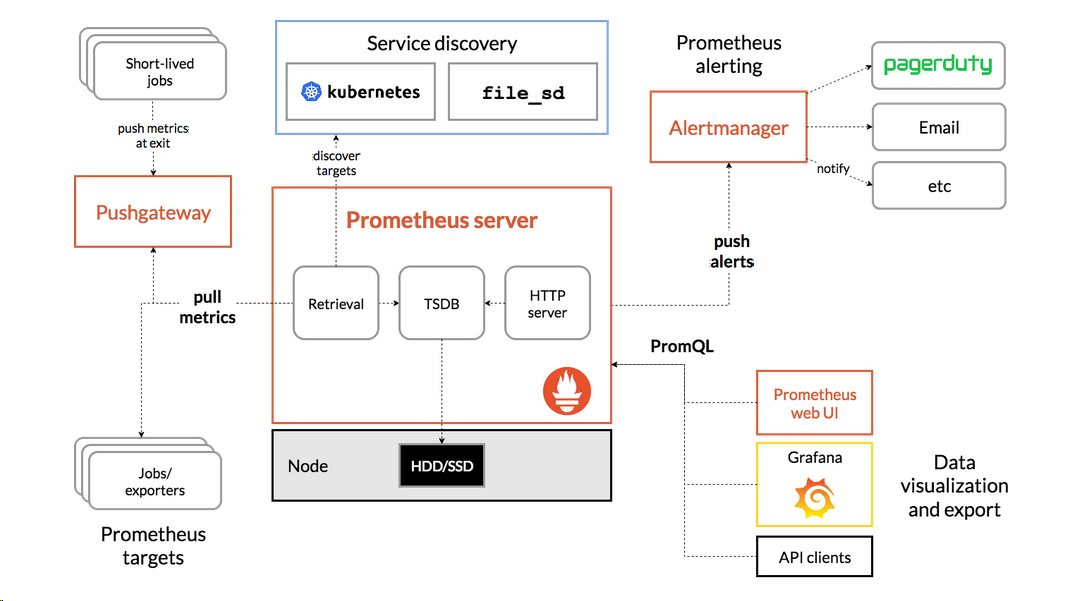
安装步骤:
wget https://github.com/prometheus/prometheus/releases/download/v2.8.0/prometheus-2.8.0.linux-amd64.tar.gz
tar -xf prometheus-2.8.0.linux-amd64.tar.gz
cd prometheus-2.8.0.linux-amd64
修改配置文件prometheus.yml,添加以下内容
static_configs:
- targets: ['192.168.247.211:9090']
- job_name: 'docker'
static_configs:
- targets:
- "192.168.247.211:8090"
- "192.168.247.212:8090" cp prometheus promtool /usr/local/bin/ 启动:
nohup prometheus --config.file=./prometheus.yml &
我的完整简单prometheus.yml配置文件:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s). # Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml" # A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus' # metrics_path defaults to '/metrics'
# scheme defaults to 'http'. static_configs:
- targets: ['192.168.247.211:9090']
- job_name: 'docker'
static_configs:
- targets:
- "192.168.247.211:8090"
- "192.168.247.212:8090"
访问:http://192.168.247.211:9090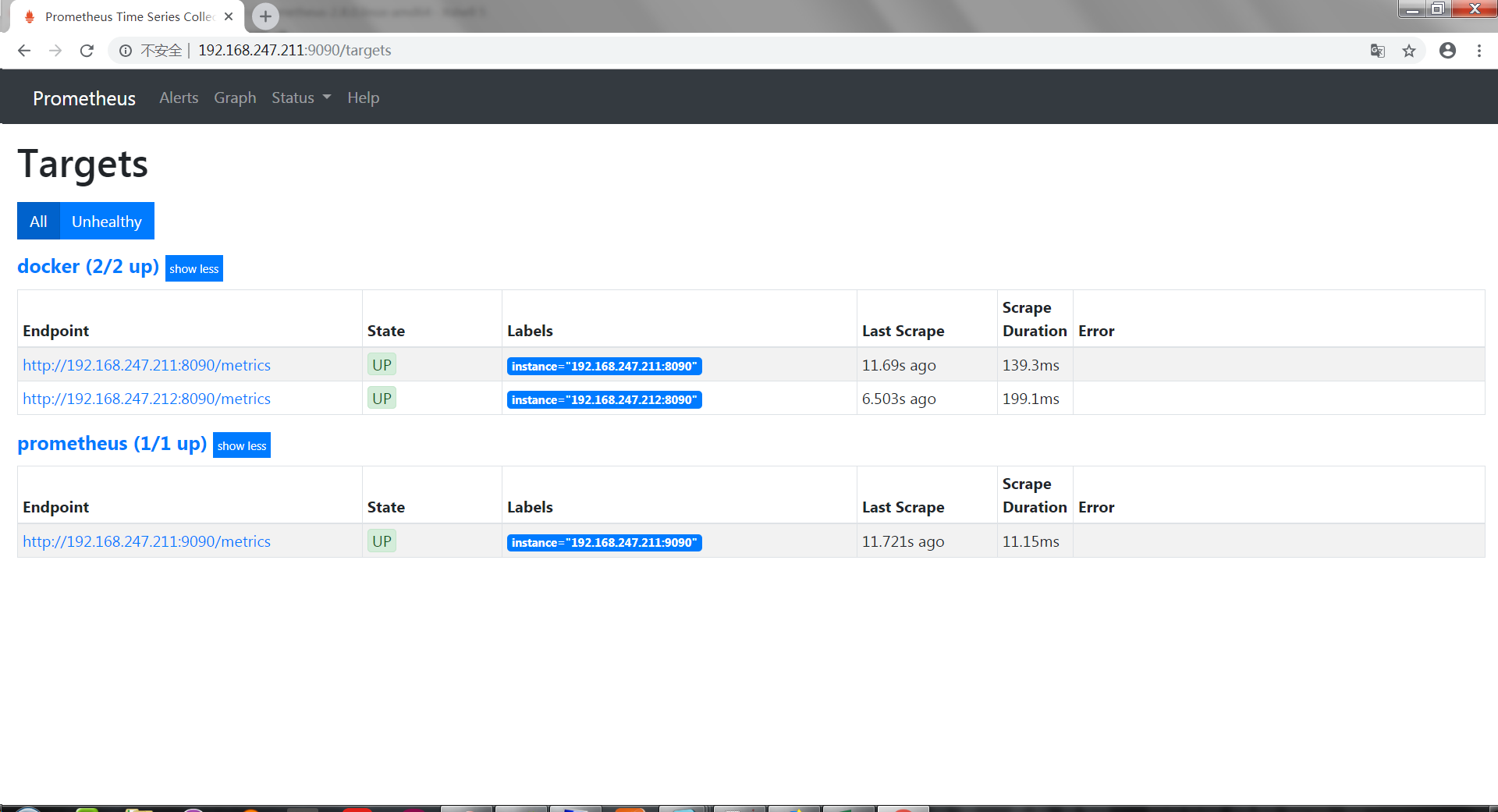
三、Grafana
官方地址:https://grafana.com/
安装步骤:
wget https://dl.grafana.com/oss/release/grafana-6.0.1-1.x86_64.rpm
sudo yum localinstall grafana-6.0.1-1.x86_64.rpm -y
systemctl daemon-reload
systemctl start grafana-server
systemctl status grafana-server
#设置开机自启动
Enable the systemd service so that Grafana starts at boot.
sudo systemctl enable grafana-server.service
1.访问:http://192.168.247.211:3000/login
默认密码:admin/admin
2.配置Prometheus数据源
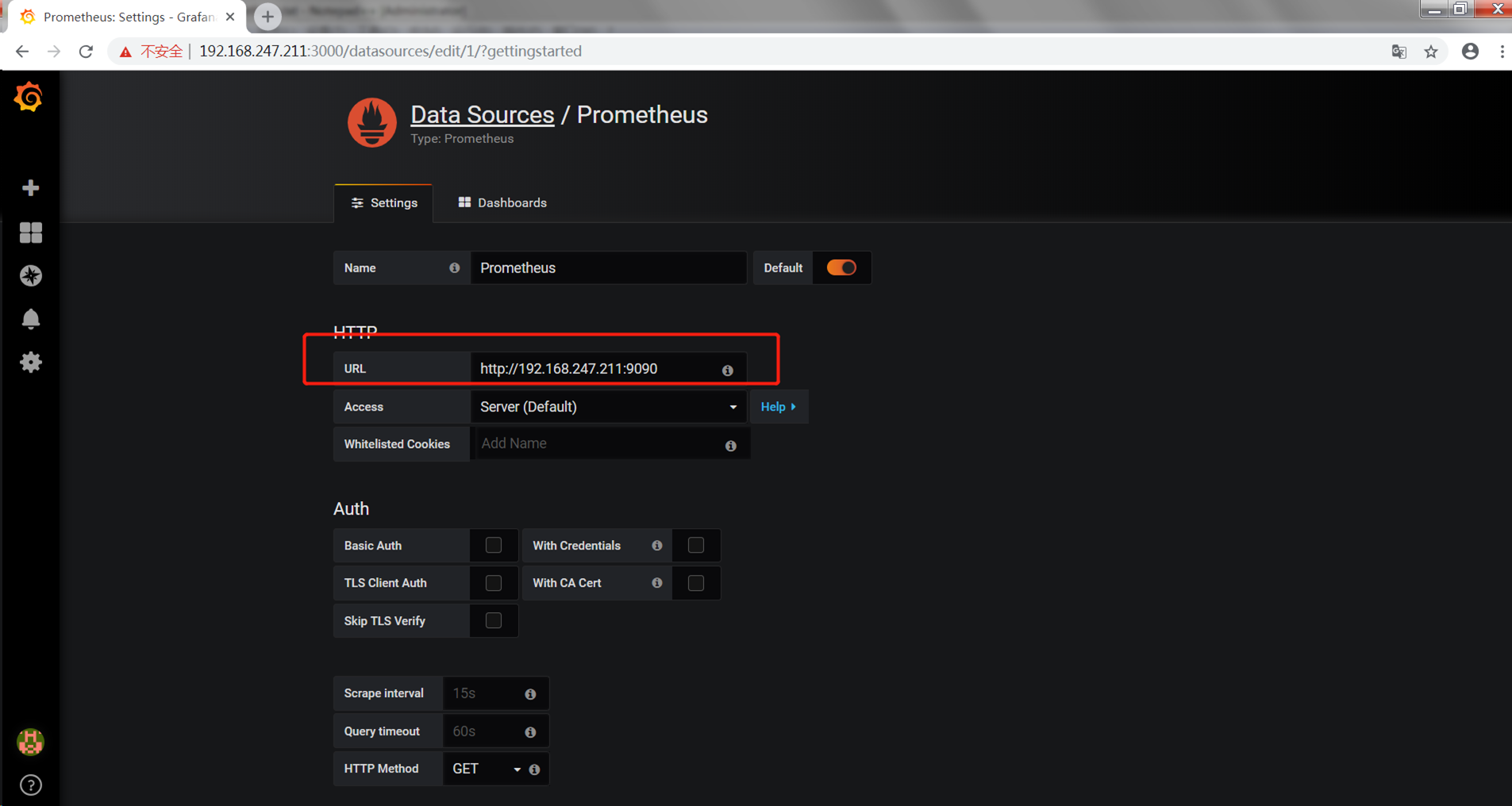
3.下载模板模板地址:https://grafana.com/dashboards
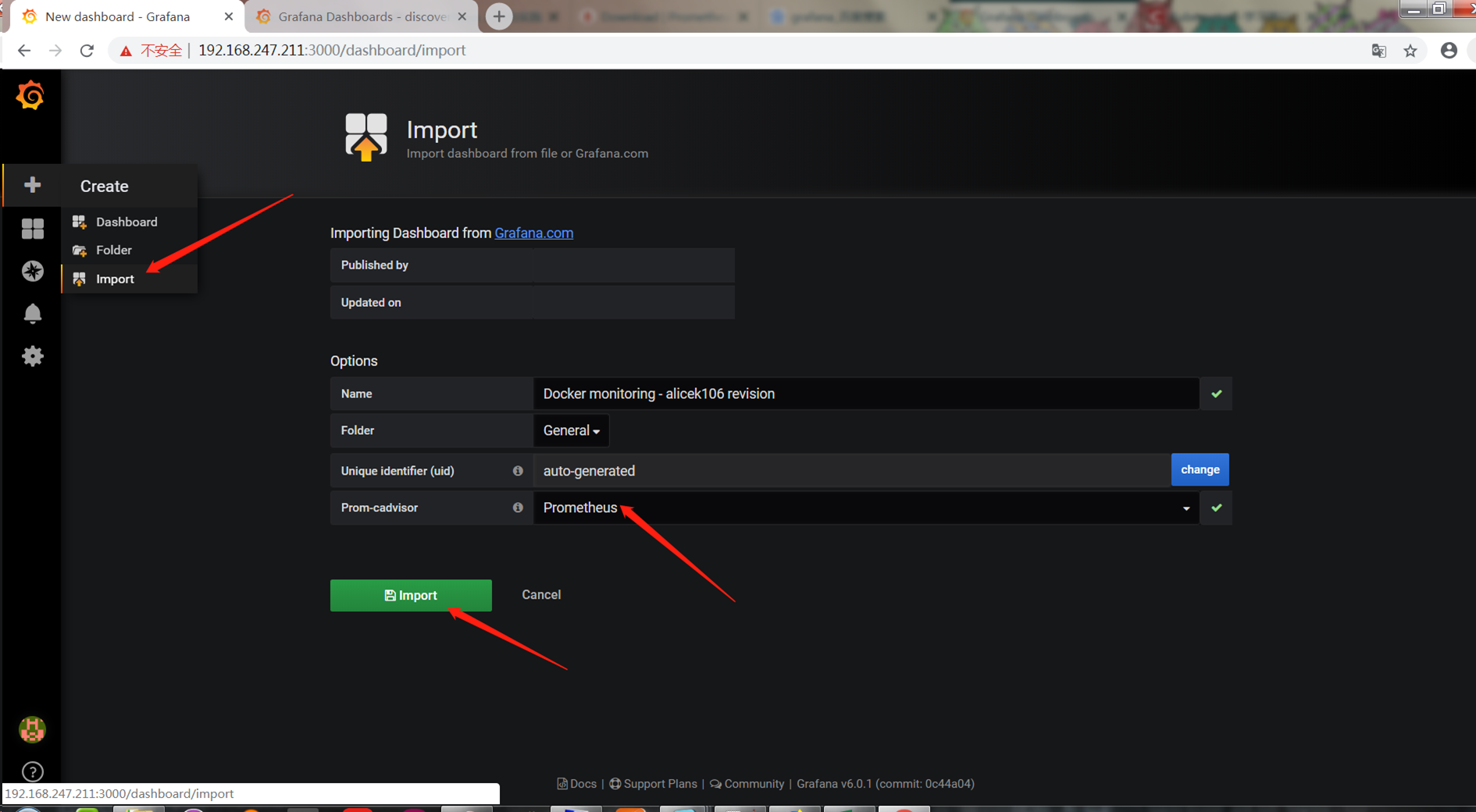
4.导入模板
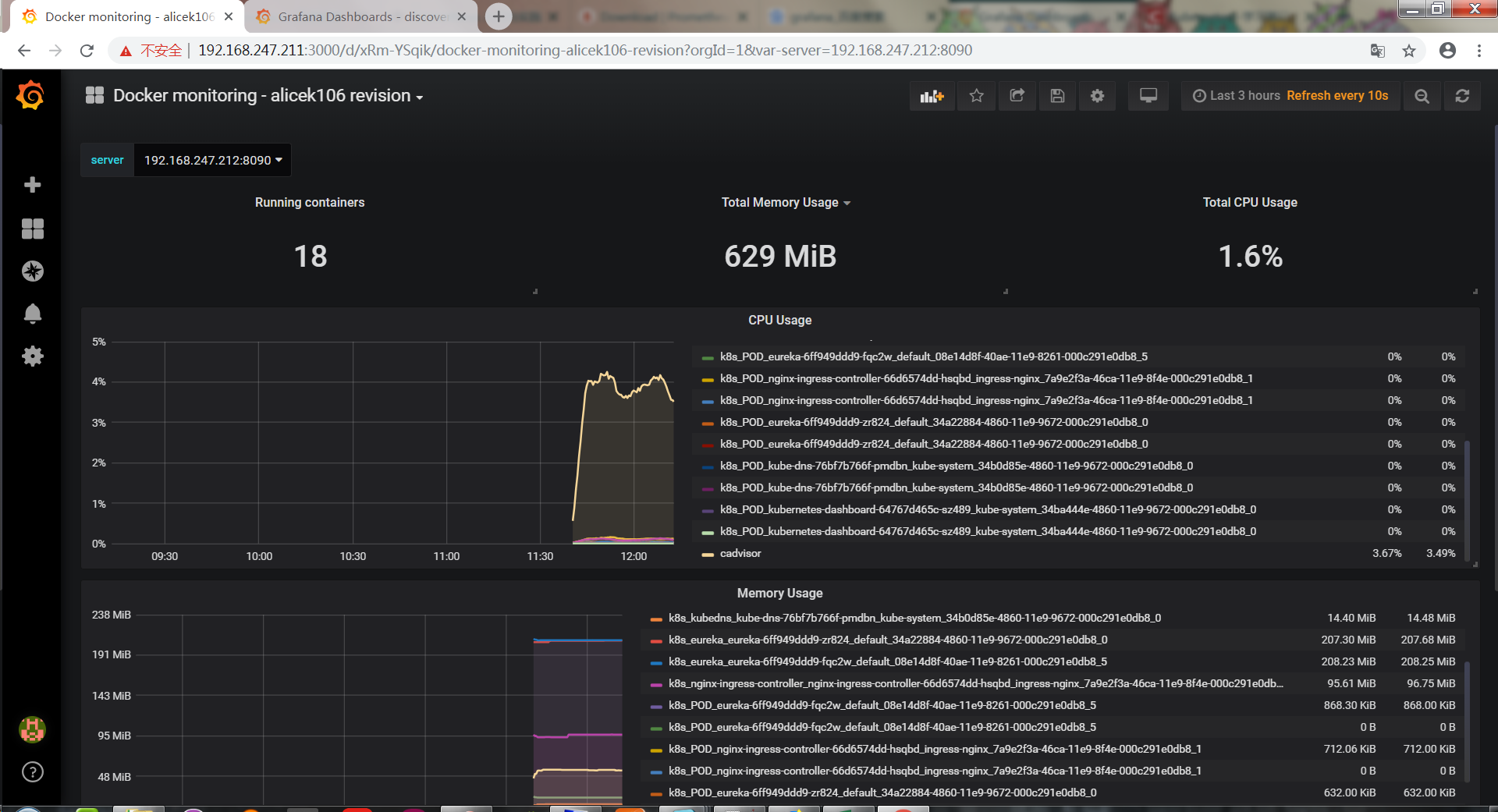
5.成品
cAdvisor+Prometheus+Grafana监控docker的更多相关文章
- cAdvisor+InfluxDB+Grafana 监控Docker
容器的监控方案其实有很多,有docker自身的docker stats命令.有Scout.有Data Dog等等,本文主要和大家分享一下比较经典的容器开源监控方案组合:cAdvisor+InfluxD ...
- Prometheus+Grafana 监控 Docker
cAdvisor (Container Advisor) :用于收集正在运行的容器资源使用和性能信息. https://github.com/google/cadvisor Prometheus(普罗 ...
- 部署Prometheus+Grafana监控
Prometheus 1.不是很友好,各种配置都手写 2.对docker和k8s监控有成熟解决方案 Prometheus(普罗米修斯) 是一个最初在SoudCloud上构建的监控系统,开源项目,拥有非 ...
- [转帖]Prometheus+Grafana监控Kubernetes
原博客的位置: https://blog.csdn.net/shenhonglei1234/article/details/80503353 感谢原作者 这里记录一下自己试验过程中遇到的问题: . 自 ...
- 【Springboot】用Prometheus+Grafana监控Springboot应用
1 简介 项目越做越发觉得,任何一个系统上线,运维监控都太重要了.关于Springboot微服务的监控,之前写过[Springboot]用Springboot Admin监控你的微服务应用,这个方案可 ...
- Prometheus + Grafana 监控系统搭
本文主要介绍基于Prometheus + Grafana 监控Linux服务器. 一.Prometheus 概述(略) 与其他监控系统对比 1 Prometheus vs. Zabbix Zabbix ...
- Prometheus+Grafana监控SpringBoot
Prometheus+Grafana监控SpringBoot 一.Prometheus监控SpringBoot 1.1 pom.xml添加依赖 1.2 修改application.yml配置文件 1. ...
- Prometheus+Grafana监控Kubernetes
涉及文件下载地址:链接:https://pan.baidu.com/s/18XHK7ex_J0rzTtfW-QA2eA 密码:0qn6 文件中需要下载的镜像需要自己提前下载好,eg:prom/node ...
- prometheus+grafana监控redis
prometheus+grafana监控redis redis安装配置 https://www.cnblogs.com/autohome7390/p/6433956.html redis_export ...
随机推荐
- bash: pip: command not found... 解决方法
下载安装wget "https://pypi.python.org/packages/source/p/pip/pip-1.5.4.tar.gz#md5=834b2904f92d46aaa3 ...
- Java Script 学习笔记 (一) 基础
1. 设置变量 const: 赋常量,不可更改. let :设置可更改变量. ES6 中推荐使用let 而不是var. Let 和var的区别 : let 将变量的作用域限定在当前{}中, var 定 ...
- 【双连通分量】Bzoj2730 HNOI2012 矿场搭建
Description 煤矿工地可以看成是由隧道连接挖煤点组成的无向图.为安全起见,希望在工地发生事故时所有挖煤点的工人都能有一条出路逃到救援出口处.于是矿主决定在某些挖煤点设立救援出口,使得无论哪一 ...
- BZOJ_4554_[Tjoi2016&Heoi2016]游戏_二分图匹配
BZOJ_4554_[Tjoi2016&Heoi2016]游戏_二分图匹配 Description 在2016年,佳缘姐姐喜欢上了一款游戏,叫做泡泡堂.简单的说,这个游戏就是在一张地图上放上若 ...
- 这么用Mac才叫爽!
用了近一年的 Macbook Pro,已经离不开它了.真是生活工作学习必备之良品啊. 如果你将要买苹果电脑或者刚买,那么不妨看看此文.推荐一些个人觉得好用的软件,而Mac本身的使用技巧----触控板. ...
- Android--app性能问题的总结(一)
一个应用程序的性能问题体现在很多方面,app的性能问题,很大程度上决定了使用app的用户量,如果正在使用app的过程中出现app崩溃.卡顿半天加载不出数据(跟网络也有一定的关系).用户请求事件半天获 ...
- Spark学习之Spark Streaming
一.简介 许多应用需要即时处理收到的数据,例如用来实时追踪页面访问统计的应用.训练机器学习模型的应用,还有自动检测异常的应用.Spark Streaming 是 Spark 为这些应用而设计的模型.它 ...
- 深入解读Service Mesh的数据面Envoy
在前面的一篇文章中,详细解读了Service Mesh中的技术细节,深入解读Service Mesh背后的技术细节. 但是对于数据面的关键组件Envoy没有详细解读,这篇文章补上. 一.Envoy的工 ...
- 华为手机无法使用USB调试的解决方案
在Android开发中,一直在使用华为的荣耀8进行调试,但是突然某一次,发现USB调试无法使用了,且在其他的电脑上进行调试也不行. 后来经过查资料,总算解决了此问题,在这里进行一下解决方案的记录. 需 ...
- WebGL three.js学习笔记 纹理贴图模拟太阳系运转
纹理贴图的应用以及实现一个太阳系的自转公转 点击查看demo演示 demo地址:https://nsytsqdtn.github.io/demo/solar/solar three.js中的纹理 纹理 ...