Python爬虫使用lxml模块爬取豆瓣读书排行榜并分析
上次使用了BeautifulSoup库爬取电影排行榜,爬取相对来说有点麻烦,爬取的速度也较慢。本次使用的lxml库,我个人是最喜欢的,爬取的语法很简单,爬取速度也快。
本次爬取的豆瓣书籍排行榜的首页地址是:
https://www.douban.com/doulist/1264675/?start=0&sort=time&playable=0&sub_type=
该排行榜一共有22页,且发现更改网址的 start=0 的 0 为25、50就可以跳到排行榜的第二、第三页,所以后面只需更改这个数字然后通过遍历就可以爬取整个排行榜的书籍信息。
本次爬取的内容有书名、评分、评价数、出版社、出版年份以及书籍封面图,封面图保存为图片,其他数据存为csv文件,方面后面读取分析。
本次的项目步骤:一、分析网页,确定爬取数据
二、使用lxml库爬取内容并保存
三、读取数据并选择部分内容进行分析
- 步骤一:

分析网页源代码可以看到,书籍信息在属性为 class="doulist-item"的div标签中,打开发现,我们需要爬取的信息都在标签内部,通过xpath语法我们可以很简便的爬取所需内容。
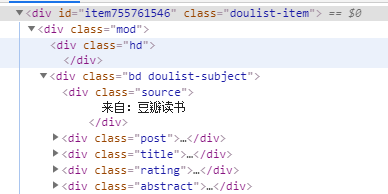 (书籍各类信息所在标签)
(书籍各类信息所在标签)
所需爬取的内容在 class为post、title、rating、abstract的div标签中。
- 步骤二:
- 先定义爬取函数,爬取所需内容
- 执行函数,并存入csv文件
具体代码如下: 注:转载代码请标明出处
import requests
from lxml import etree
import time
import csv #信息头
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
} #定义爬取函数
def douban_booksrank(url):
res = requests.get(url, headers=headers)
selector = etree.HTML(res.text)
contents = selector.xpath('//div[@class="article"]/div[contains(@class,"doulist-item")]') #循环点
for content in contents:
try:
title = content.xpath('div/div[2]/div[3]/a/text()')[0] #书名
scores = content.xpath('div/div[2]/div[4]/span[2]/text()') #评分
scores.append('9.0') #因为有一些书没有评分,导致列表为空,此处添加一个默认评分,若无评分则默认为9.0
score = scores[0]
comments = content.xpath('div/div[2]/div[4]/span[3]/text()')[0] #评论数量
author = content.xpath('div/div[2]/div[5]/text()[1]')[0] #作者
publishment = content.xpath('div/div[2]/div[5]/text()[2]')[0] #出版社
pub_year = content.xpath('div/div[2]/div[5]/text()[3]')[0] #出版时间
img_url = content.xpath('div/div[2]/div[2]/a/img/@src')[0] #书本图片的网址
img = requests.get(img_url) #解析图片网址,为下面下载图片
img_name_file = 'C:/Users/lenovo/Desktop/douban_books/{}.png'.format((title.strip())[:3]) #图片存储位置,图片名只取前3
#写入csv
with open('C:\\Users\lenovo\Desktop\\douban_books.csv', 'a+', newline='', encoding='utf-8')as fp: #newline 使不隔行
writer = csv.writer(fp)
writer.writerow((title, score, comments, author, publishment, pub_year, img_url))
#下载图片,为防止图片名导致格式错误,加入try...except
try:
with open(img_name_file, 'wb')as imgf:
imgf.write(img.content)
except FileNotFoundError or OSError:
pass
time.sleep(0.5) #睡眠0.5s
except IndexError:
pass
#执行程序
if __name__=='__main__':
#爬取所有书本,共22页的内容
urls = ['https://www.douban.com/doulist/1264675/?start={}&sort=time&playable=0&sub_type='.format(str(i))for i in range(0,550,25)]
#写csv首行
with open('C:\\Users\lenovo\Desktop\\douban_books.csv', 'a+', newline='', encoding='utf-8')as f:
writer = csv.writer(f)
writer.writerow(('title', 'score', 'comment', 'author', 'publishment', 'pub_year', 'img_url'))
#遍历所有网页,执行爬取程序
for url in urls:
douban_booksrank(url)
爬取结果截图如下:
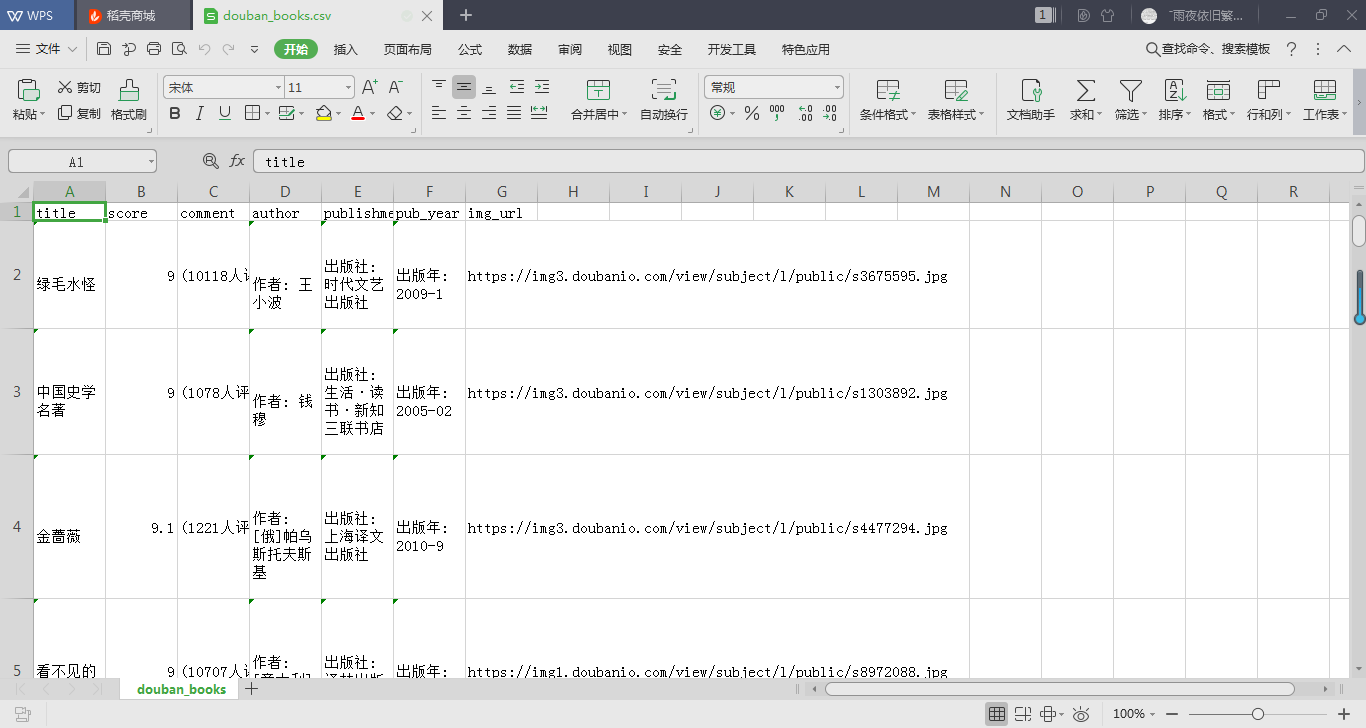
- 步骤三:
本次使用Python常用的数据分析库pandas来提取所需内容。pandas的read_csv()函数可以读取csv文件并根据文件格式转换为Series、DataFrame或面板对象。
此处我们提取的数据转变为DataFrame(数据帧)对象,然后通过Matplotlib绘图库来进行绘图。
具体代码如下:
from matplotlib import pyplot as plt
import pandas as pd
import re plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
plt.subplots_adjust(wsapce=0.5, hspace=0.5) #调整subplot子图间的距离 pd.set_option('display.max_rows', None) #设置使dataframe 所有行都显示 df = pd.read_csv('C:\\Users\lenovo\Desktop\\douban_books.csv') #读取csv文件,并赋为dataframe对象 comment = re.findall('\((.*?)人评价', str(df.comment), re.S) #使用正则表达式获取评论人数
#将comment的元素化为整型
new_comment = []
for i in comment:
new_comment.append(int(i)) pub_year = re.findall(r'\d{4}', str(df.pub_year),re.S) #获取书籍出版年份
#同上
new_pubyear = []
for n in pub_year:
new_pubyear.append(int(n)) #绘图
#1、绘制书籍评分范围的直方图
plt.subplot(2,2,1)
plt.hist(df.score, bins=16, edgecolor='black')
plt.title('豆瓣书籍排行榜评分分布', fontweight=700)
plt.xlabel('scores')
plt.ylabel('numbers') #绘制书籍评论数量的直方分布图
plt.subplot(222)
plt.hist(new_comment, bins=16, color='green', edgecolor='yellow')
plt.title('豆瓣书籍排行榜评价分布', fontweight=700)
plt.xlabel('评价数')
plt.ylabel('书籍数量(单位/本)') #绘制书籍出版年份分布图
plt.subplot(2,2,3)
plt.hist(new_pubyear, bins=30, color='indigo',edgecolor='blue')
plt.title('书籍出版年份分布', fontweight=700)
plt.xlabel('出版年份/year')
plt.ylabel('书籍数量/本') #寻找关系
plt.subplot(224)
plt.bar(new_pubyear,new_comment, color='red', edgecolor='white')
plt.title('书籍出版年份与评论数量的关系', fontweight=700)
plt.xlabel('出版年份/year')
plt.ylabel('评论数') plt.savefig('C:\\Users\lenovo\Desktop\\douban_books_analysis.png') #保存图片
plt.show()
这里需要注意的是,使用了正则表达式来提取评论数和出版年份,将其中的符号和文字等剔除。
分析结果如下:
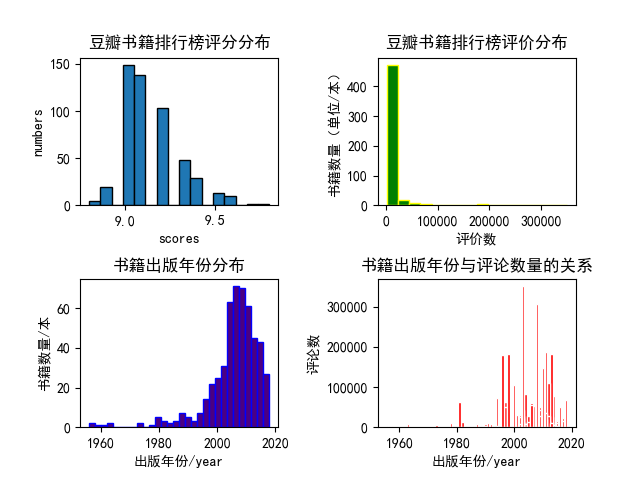
本次分析的内容也较为简单,从上面的几个图形中我们也能得出一些结论。
- 这些高分书籍中绝大多数的评论数量都在50000以下;
- 多数排行榜上的高分书籍都出版在2000年以后;
- 出版年份在2000年后的书籍有更多的评论数量。
以上数据也见解的说明了在进入二十世纪后我国的图书需求量更大了,网络更发达,更多人愿意发表自己的看法。
本次的分享到此。若有错误,欢迎指正。有建议的话也可以留言。
Python爬虫使用lxml模块爬取豆瓣读书排行榜并分析的更多相关文章
- python爬虫:利用正则表达式爬取豆瓣读书首页的book
1.问题描述: 爬取豆瓣读书首页的图书的名称.链接.作者.出版日期,并将爬取的数据存储到Excel表格Douban_I.xlsx中 2.思路分析: 发送请求--获取数据--解析数据--存储数据 1.目 ...
- Python爬虫之利用BeautifulSoup爬取豆瓣小说(一)——设置代理IP
自己写了一个爬虫爬取豆瓣小说,后来为了应对请求不到数据,增加了请求的头部信息headers,为了应对豆瓣服务器的反爬虫机制:防止请求频率过快而造成“403 forbidden”,乃至封禁本机ip的情况 ...
- python实例:自动爬取豆瓣读书短评,分析短评内容
思路: 1.打开书本“更多”短评,复制链接 2.脚本分析链接,通过获取短评数,计算出页码数 3.通过页码数,循环爬取当页短评 4.短评写入到txt文本 5.读取txt文本,处理文本,输出出现频率最高的 ...
- Python爬虫之利用BeautifulSoup爬取豆瓣小说(二)——回车分段打印小说信息
在上一篇文章中,我主要是设置了代理IP,虽然得到了相关的信息,但是打印出来的信息量有点多,要知道每打印一页,15个小说的信息全部会显示而过,有时因为屏幕太小,无法显示全所有的小说信息,那么,在这篇文章 ...
- Python爬虫之利用BeautifulSoup爬取豆瓣小说(三)——将小说信息写入文件
#-*-coding:utf-8-*- import urllib2 from bs4 import BeautifulSoup class dbxs: def __init__(self): sel ...
- python爬虫学习01--电子书爬取
python爬虫学习01--电子书爬取 1.获取网页信息 import requests #导入requests库 ''' 获取网页信息 ''' if __name__ == '__main__': ...
- python爬虫:了解JS加密爬取网易云音乐
python爬虫:了解JS加密爬取网易云音乐 前言 大家好,我是"持之以恒_liu",之所以起这个名字,就是希望我自己无论做什么事,只要一开始选择了,那么就要坚持到底,不管结果如何 ...
- Python爬虫:为什么你爬取不到网页数据
前言: 之前小编写了一篇关于爬虫为什么爬取不到数据文章(文章链接为:Python爬虫经常爬不到数据,或许你可以看一下小编的这篇文章), 但是当时小编也是胡乱编写的,其实里面有很多问题的,现在小编重新发 ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
随机推荐
- Effective C++ 读书笔记(39-45)
条款三十九:明智而审慎的使用private继承 1.C++裁定凡是独立(非附属)对象都必须有非零大小. class Empty{};//没有数据,所以其对象应该不使用任何内存 class HoldAn ...
- 微信小程序开发问题汇总
前言 经过将近一个多月的开发,我们团队开发的微信小程序 "出发吧一起" 终于开发完成,现在的线上版本为 2.2.4-beta 版 本文档主要介绍该小程序在开发中所用到的技术,已经在 ...
- 团队项目第二阶段个人进展——Day7
一.昨天工作总结 冲刺第七天,动手完成了一个demo来实现数据的上传与下载 二.遇到的问题 代码逻辑没看太懂 三.今日工作规划 对发布页面的数据进行处理,实现能够请求和响应,并学习如何实现图片的上传与 ...
- PAT1079 :Total Sales of Supply Chain
1079. Total Sales of Supply Chain (25) 时间限制 250 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 CHE ...
- 如何提高缓存命中率(Redis)
缓存命中率的介绍 命中:可以直接通过缓存获取到需要的数据. 不命中:无法直接通过缓存获取到想要的数据,需要再次查询数据库或者执行其它的操作.原因可能是由于缓存中根本不存在,或者缓存已经过期. 通常来讲 ...
- RedHat Linux下iptables防火墙设置
一般情况下iptables已经包含在Linux发行版中.运行 # iptables --version 来查看系统是否安装iptables 启动iptables:# service iptables ...
- SSM-Spring-15:Spring中名称自动代理生成器BeanNameAutoProxyCreator
------------吾亦无他,唯手熟尔,谦卑若愚,好学若饥------------- 名称自动代理生成器:BeanNameAutoProxyCreator 为了更好的测试,我放了俩个接口,俩个实现 ...
- thinkphp 自动生成模块目录结构
要达到的目的 在application目录下创建自定义模块如admin,用命令行方式自动创建该目录及目录下默认结构 要运行的命令 > php think build --module admin ...
- sap 内表
内表的目的在ABAP/4中,主要使用表格.表格是R/3系统中的关键数据结构.长期使用的数据存储在关系数据库表格中.关于如何读取和处理数据库表格的详细信息,参见读取并处理数据库表.除了数据库表格,还可以 ...
- Linux时间子系统之五:低分辨率定时器的原理和实现
专题文档汇总目录 Notes:低精度timer在内核中的数据结构以及API接口:低精度timer精巧高效的分组,使用cascade进行定时器移位,组内Timer FIFO:低精度Timer的初始化流程 ...