python 爬取糗事百科 gui小程序
前言:有时候无聊看一些搞笑的段子,糗事百科还是个不错的网站,所以就想用Python来玩一下。也比较简单,就写出来分享一下。嘿嘿
环境:Python 2.7 + win7
现在开始,打开糗事百科网站,先来分析。地址:https://www.qiushibaike.com
一般像这种都是文本的话,查看源代码就可以看到内容了。


已经可以看到都是在一个class 为content 的div里面,这样就很简单了,直接上正则表达式来匹配就好了。
<div.*?class="content">(.*?)</div>
这样等会再代码里面就可以提取出来段子内容了,再来看一下分页。
分页也很简单,很有规律,直接接上页数就行了。
OK 既然 都分析完了 那就直接上代码。
#-*- coding: UTF-8 -*-
# author : Corleone
from Tkinter import *
import urllib2,re def load(page):
url="http://www.qiushibaike.com/text/page/"+str(page)+"/?s=4937798"
user_agent="Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.113 Safari/537.36"
headers={'User-Agent':user_agent}
res=urllib2.Request(url,headers = headers)
html = urllib2.urlopen(res).read()
reg=re.compile(r'<div.*?class="content">(.*?)</div>',re.S)
duanzi=reg.findall(html)
return duanzi
i=0
page=1
def get():
if i==0:
txtlist=load(page)
page+=1
if i<20:
txt.delete(1.0,END)
txt.insert(1.0,txtlist[i].replace("<span>","").replace("</span>","").replace("</br>","").replace("\n","").replace("<br/>",""))
i+=1
global i
global page
global txtlist
else:
i=0 def main():
root=Tk() # 定义一个窗口
root.title("Corleone") # 定义窗口标题
root.geometry('500x500') # 定义窗口大小
b=Button(root,text="next",width=25,bg="red",command=get) # 定义一个按钮
b.pack(side=BOTTOM) # 按钮的布局 放在窗口最下面
global txt
txt=Text(root,font=(u"黑体",20)) # 定义一个编辑界面
txt.pack(expand=YES,fill=BOTH) # 编辑界面布局 随窗口大小而自动改变
root.mainloop() # 让窗口一直在屏幕上显示出来 main()
这里用到了Python自带的图形化界面库 Tkinter 来做gui界面。一页大概20个段子 next 按钮 下一个 看完了 就翻页。
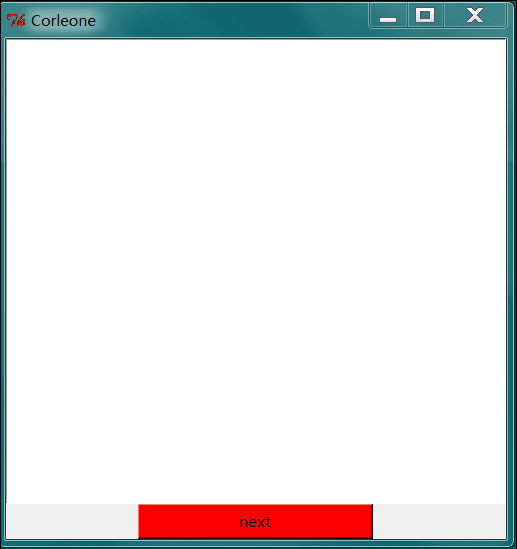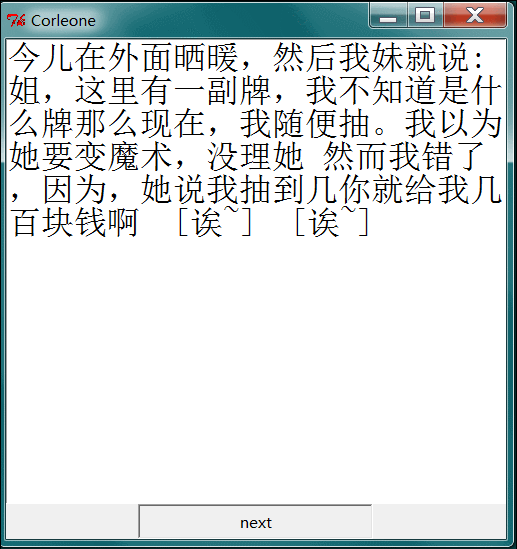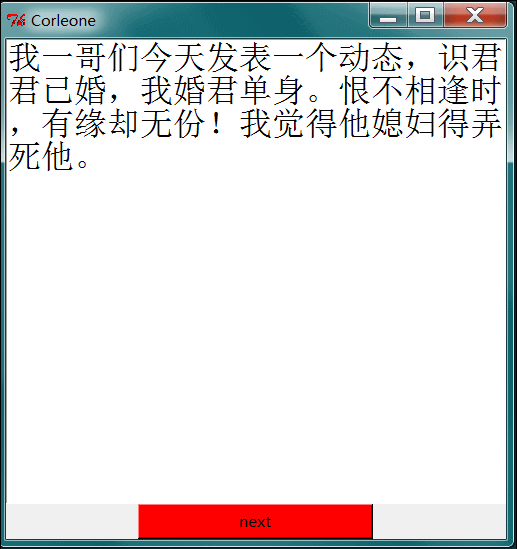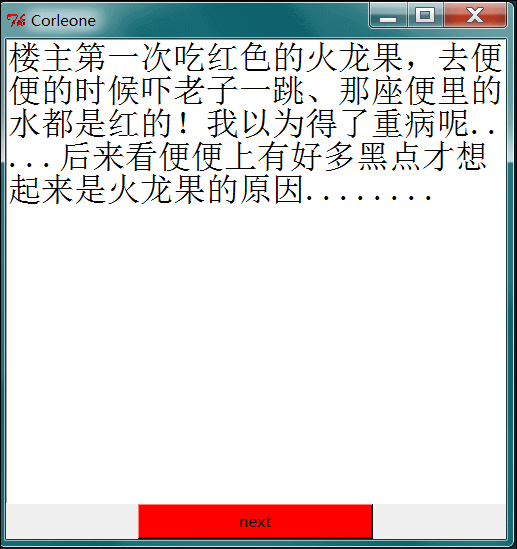
嘿嘿,这样就能直接看了。OK 好了 这篇文章也很简单,没啥技术含量,莫见怪,代码都是我之前写的,现在依然能用,就发出来了 : )
python 爬取糗事百科 gui小程序的更多相关文章
- python爬取糗事百科段子
初步爬取糗事百科第一页段子(发布人,发布内容,好笑数和评论数) #-*-coding:utf--*- import urllib import urllib2 import re page = url ...
- Python爬取糗事百科
import urllib import urllib.request from bs4 import BeautifulSoup """ 1.抓取糗事百科所有纯 ...
- Python爬取糗事百科示例代码
参考链接:http://python.jobbole.com/81351/#comment-93968 主要参考自伯乐在线的内容,但是该链接博客下的源码部分的正则表达式部分应该是有问题,试了好几次,没 ...
- 8.Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
- python网络爬虫--简单爬取糗事百科
刚开始学习python爬虫,写了一个简单python程序爬取糗事百科. 具体步骤是这样的:首先查看糗事百科的url:http://www.qiushibaike.com/8hr/page/2/?s=4 ...
- python爬虫之爬取糗事百科并将爬取内容保存至Excel中
本篇博文为使用python爬虫爬取糗事百科content并将爬取内容存入excel中保存·. 实验环境:Windows10 代码编辑工具:pycharm 使用selenium(自动化测试工具)+p ...
- [爬虫]用python的requests模块爬取糗事百科段子
虽然Python的标准库中 urllib2 模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 “HTTP for Humans”,说明使用更 ...
随机推荐
- MyEclipse中阿里JAVA代码规范插件(P3C)的安装及使用
JAVA代码规范插件(P3C)是阿里巴巴2017年10月14日在杭州云栖大会上首发的,使之前的阿里巴巴JAVA开发手册正式以插件形式公开走向业界.插件的相关信息及安装包都可以在GitHub(https ...
- IEEE754 处理数据变换
public class IEEE754 { /// <summary> /// 将二进制值转ASCII格式十六进制字符串 /// </summary> /// <pa ...
- 【转】国际GNSS服务组织IGS
国际GNSS服务组织The International GNSS Service,简称IGS,前身为国际GPS服务组织.IGS提供的高质量数据和产品被用于地球科学研究等多个领域. IGS组织由卫星跟踪 ...
- JavaSE基础篇—MySQL三大范式—数据库设计规范
1.概 念 范式是一种符合设计要求的总结,要想设计一个结构合理的关系型数据库,必须满足一定的范式.各个范式是以此嵌套包含的,范式越高,设计等级越高,在现实设计中也越难实现,一般数据库只要打 ...
- 13 Basic Cat Command Examples in Linux(转) Linux中cat命令的13中基本用法
Cat (串联) 命令是Linux/Unix开源系统中比较常用的一个命令.我们可以通过Cat命令创建一个或多个文件,查看文件内容,串联文件并将内容输出到终端设备或新的文件当中,这篇文章我们将会以实例的 ...
- SpringMVC 知识整理
SpringMVC架构设计 MVC是一种架构模式,它把业务的实现和展示相分离. SpringMVC与struts2的区别 Struts2是类级别的拦截, 一个类对应一个request上下文,Sprin ...
- fread和fwrite的使用
fread和fwrite的使用 fread和fwrite一般用于二进制文件的输入/输出,要不然你打开fwrite写入的文件就是乱码. 1.fread和fwrite函数 数据块I/O fread与fwr ...
- [DeeplearningAI笔记]神经网络与深度学习人工智能行业大师访谈
觉得有用的话,欢迎一起讨论相互学习~Follow Me 吴恩达采访Geoffrey Hinton NG:前几十年,你就已经发明了这么多神经网络和深度学习相关的概念,我其实很好奇,在这么多你发明的东西中 ...
- spring之p命名空间注入
<bean id="personId" class="com.itheima.f_xml.c_p.Person" p:pname="禹太璞&qu ...
- java 世界中Annotation
java 世界中Annotation 在github上开始汇总一些自己学习,收集,总结,经验的一些信息,有利于跟踪,修改,提升.如果你感兴趣 可以关注一下,也可以提供自己的内容进来. https:// ...