python3爬虫——下载unsplash美图到本地
最近发现一个网站www.unsplash.com ( 没有广告费哈,纯粹觉得不错 ),网页做得很美观,上面也都是一些免费的摄影照片,觉得很好看,就决定利用蹩脚的技能写个爬虫下载图片。
先随意感受一下这个网站:
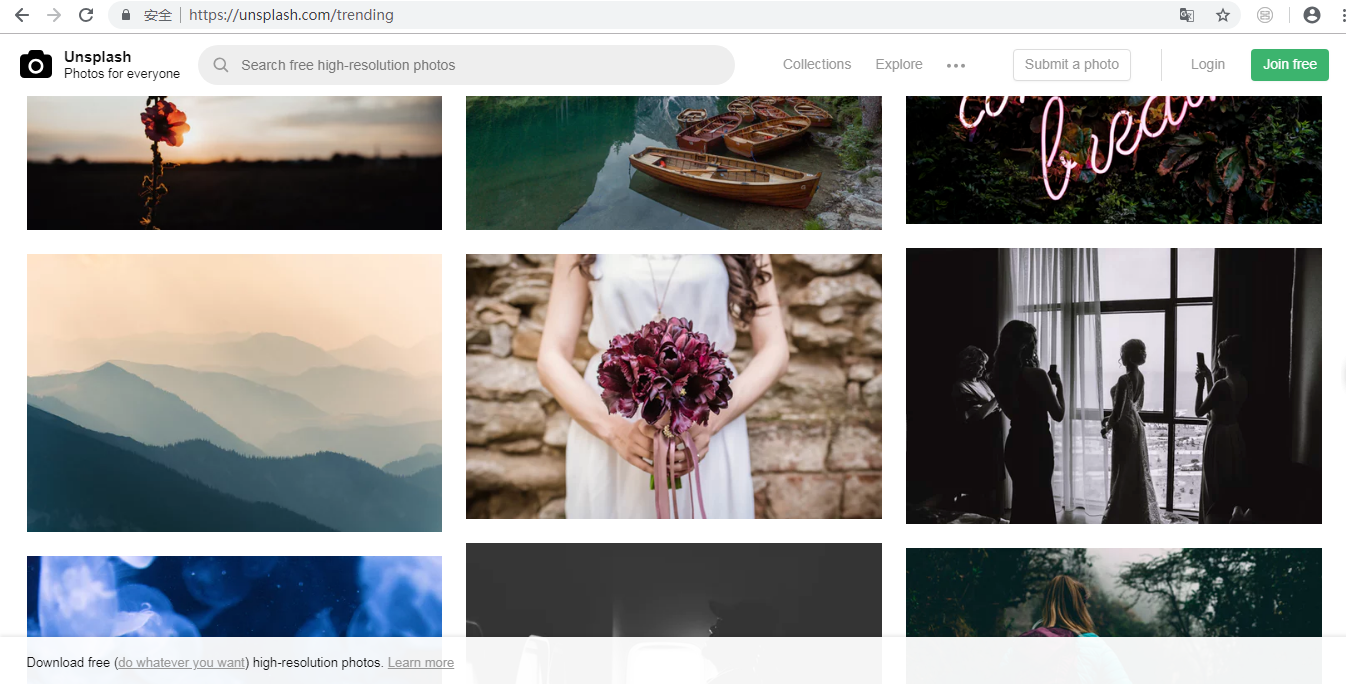
接下来开始对网页进行解析:
在该网页检查元素,选择其中一张图片查看它的代码
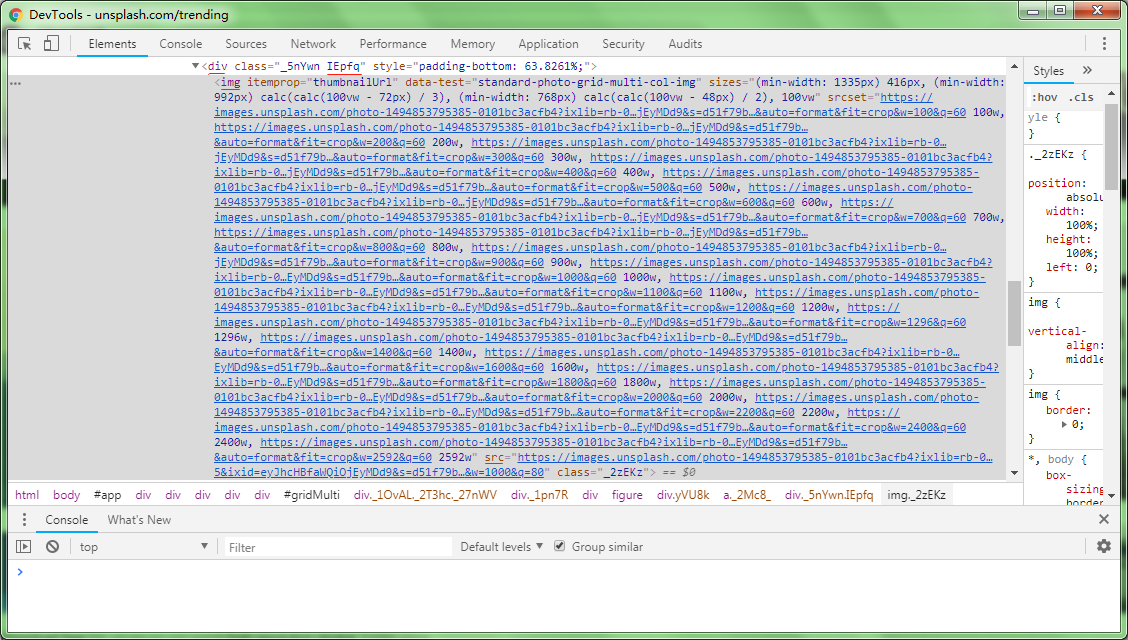
可以看到,图片 img 在一个 div 的 tag 里面,而且 class = ”IEpfq“,不过那么多内容,虽然有点乱,但其实看 src = ” “ 就行了。
但这只是一张图片的内容,得再看看其他的图片是不是一样。检查一下发现都是这样。这样子就算解析完成了。可以开始写代码了
#!/usr/bin/env python
# _*_ coding utf-8 _*_
from bs4 import BeautifulSoup
import requests i = 0
url = 'https://unsplash.com/'
html = requests.get(url)
soup = BeautifulSoup(html.text, 'lxml') img_class = soup.find_all('div', {"class": "IEpfq"}) # 找到div里面有class = "IEpfq"的内容 for img_list in img_class:
imgs = img_list.find_all('img') # 接着往下找到 img 标签
for img in imgs:
src = img['src'] # 以"src"为 key,找到 value
r = requests.get(src, stream=True)
image_name = 'unsplash_' + str(i) + '.jpg' # 图片命名
i += 1
with open('./img/%s' % image_name, 'wb') as file: # 打开文件
for chunk in r.iter_content(chunk_size=1024): # 以chunk_size = 1024的长度进行遍历
file.write(chunk)
print('Saved %s' % image_name)
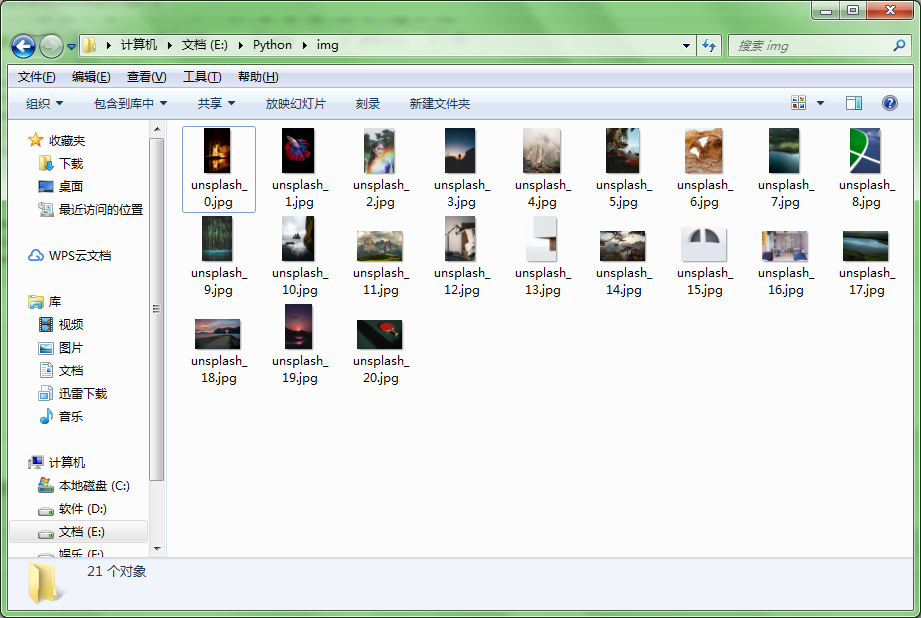
运行结果:
Saved unsplash_0.jpg
Saved unsplash_1.jpg
......
Saved unsplash_19.jpg
Saved unsplash_20.jpg
python3爬虫——下载unsplash美图到本地的更多相关文章
- 自学Python九 爬虫实战二(美图福利)
作为一个新世纪有思想有文化有道德时刻准备着的屌丝男青年,在现在这样一个社会中,心疼我大慢播抵制大百度的前提下,没事儿上上网逛逛YY看看斗鱼翻翻美女图片那是必不可少的,可是美图虽多翻页费劲!今天我们就搞 ...
- python 站点爬虫 下载在线盗墓笔记小说到本地的脚本
近期闲着没事想看小说,找到一个全是南派三叔的小说的站点,决定都下载下来看看,于是动手,在非常多QQ群里高手的帮助下(本人正則表達式非常烂.程序复杂的正则都是一些高手指导的),花了三四天写了一个脚本 须 ...
- 【Python3网络爬虫开发实战】6.4-分析Ajax爬取今日头条街拍美图【华为云技术分享】
[摘要] 本节中,我们以今日头条为例来尝试通过分析Ajax请求来抓取网页数据的方法.这次要抓取的目标是今日头条的街拍美图,抓取完成之后,将每组图片分文件夹下载到本地并保存下来. 1. 准备工作 在本节 ...
- 【Python3网络爬虫开发实战】 分析Ajax爬取今日头条街拍美图
前言本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理.作者:haoxuan10 本节中,我们以今日头条为例来尝试通过分析Ajax请求 ...
- 转:【Python3网络爬虫开发实战】6.4-分析Ajax爬取今日头条街拍美图
[摘要] 本节中,我们以今日头条为例来尝试通过分析Ajax请求来抓取网页数据的方法.这次要抓取的目标是今日头条的街拍美图,抓取完成之后,将每组图片分文件夹下载到本地并保存下来. 1. 准备工作 在本节 ...
- Python3爬虫系列:理论+实验+爬取妹子图实战
Github: https://github.com/wangy8961/python3-concurrency-pics-02 ,欢迎star 爬虫系列: (1) 理论 Python3爬虫系列01 ...
- python爬虫之分析Ajax请求抓取抓取今日头条街拍美图(七)
python爬虫之分析Ajax请求抓取抓取今日头条街拍美图 一.分析网站 1.进入浏览器,搜索今日头条,在搜索栏搜索街拍,然后选择图集这一栏. 2.按F12打开开发者工具,刷新网页,这时网页回弹到综合 ...
- Qt Quick 图像处理实例之美图秀秀(附源代码下载)
在<Qt Quick 之 QML 与 C++ 混合编程具体解释>一文中我们解说了 QML 与 C++ 混合编程的方方面面的内容,这次我们通过一个图像处理应用.再来看一下 QML 与 C++ ...
- python3爬虫(4)各种网站视频下载方法
python3爬虫(4)各种网站视频下载方法原创H-KING 最后发布于2019-01-09 11:06:23 阅读数 13608 收藏展开理论上来讲只要是网上(浏览器)能看到图片,音频,视频,都能够 ...
随机推荐
- 如何自行搭建一个威胁感知大脑 SIEM?| 硬创公开课
如何自行搭建一个威胁感知大脑 SIEM?| 硬创公开课 本文作者:谢幺 2017-03-10 10:09 专题:硬创公开课 导语:十年安全产品经验的百度安全专家兜哥,手把手教你用开源项目搭建SIEM安 ...
- python基础之Day10
一.函数的返回值 1.什么是返回值返回值是一个函数的处理结果, 2.为什么要有返回值如果我们需要在程序中拿到函数的处理结果做进一步的处理,则需要函数必须有返回值 3.函数的返回值的应用函数的返回值用r ...
- Oracle 忘记sys与system管理员密码重置操作
首先打开cmd 执行 orapwd file=C:\app\PWDorcl.ora password=orclorcl C:\app\PWDorcl.ora是你要存放的路径文件 Password=or ...
- predict predict_proba区别的小例子
predict_proba返回的是一个n行k列的数组,第i行第j列上的数值是模型预测第i个预测样本的标签为j的概率.所以每一行的和应该等于1. 举个例子 >>> from sklea ...
- P3258 [JLOI2014]松鼠的新家 (简单的点差分)
https://www.luogu.org/problemnew/show/P3258 注意开始和最后结尾 #include <bits/stdc++.h> #define read re ...
- 【转】nc 使用说明
netcat是网络工具中的瑞士军刀,它能通过TCP和UDP在网络中读写数据.通过与其他工具结合和重定向,你可以在脚本中以多种方式使用它.使用netcat命令所能完成的事情令人惊讶. netcat所做的 ...
- session和cookie相关知识总结
HTTP协议本身是无状态的,这与HTTP协议本来的目的是相符的,客户端只需要简单的向服务器请求下载某些文件,无论是客户端还是服务器都没有必要纪录彼此过去的行为,每一次请求之间都是独立的. 人们很快发现 ...
- 公司git服务器记录
gitolite:server/web/AmomeWebApp.git gitolite:server/web/AmomeBackendManage.git git@192.168.1.183 === ...
- 包含复杂函数的excel 并下载
POI 版本: <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi</a ...
- A1280. 最长双回文串
学习了回文树,地址:http://blog.csdn.net/u013368721/article/details/42100363: 这个题就是正这反着加一遍就好,一开始我想的是枚举每个位置,然后一 ...