Spark架构
Spark架构
为了更好地理解调度,我们先来鸟瞰一下集群模式下的Spark程序运行架构图。
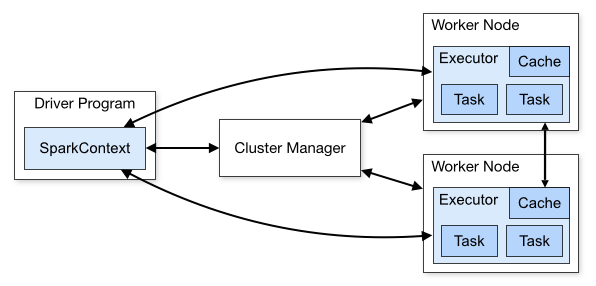
1. Driver Program
用户编写的Spark程序称为Driver Program。每个Driver程序包含一个代表集群环境的SparkContext对象,程序的执行从Driver程序开始,所有操作执行结束后回到Driver程序中,在Driver程序中结束。如果你是用spark shell,那么当你启动 Spark shell的时候,系统后台自启了一个 Spark 驱动器程序,就是在Spark shell 中预加载的一个叫作 sc 的 SparkContext 对象。如果驱动器程序终止,那么Spark 应用也就结束了。
2. SparkContext对象
每个Driver Program里都有一个SparkContext对象,职责如下:
1)SparkContext对象联系 cluster manager(集群管理器),让 cluster manager 为Worker Node分配CPU、内存等资源。此外, cluster manager会在 Worker Node 上启动一个执行器(专属于本驱动程序)。
2)和Executor进程交互,负责任务的调度分配。
3. cluster manager 集群管理器
它对应的是Master进程。集群管理器负责集群的资源调度,比如为Worker Node分配CPU、内存等资源。并实时监控Worker的资源使用情况。一个Worker Node默认情况下分配一个Executor(进程)。
从图中可以看到sc和Executor之间画了一根线条,这表明:程序运行时,sc是直接与Executor进行交互的。
所以,cluster manager 只是负责资源的管理调度,而任务的分配和结果处理它不
4.Worker Node
Worker节点。集群上的计算节点,对应一台物理机器
5.Worker进程
它对应Worder进程,用于和Master进程交互,向Master注册和汇报自身节点的资源使用情况,并管理和启动Executor进程
6.Executor
负责运行Task计算任务,并将计算结果回传到Driver中。
7.Task
在执行器上执行的最小单元。比如RDD Transformation操作时对RDD内每个分区的计算都会对应一个Task。
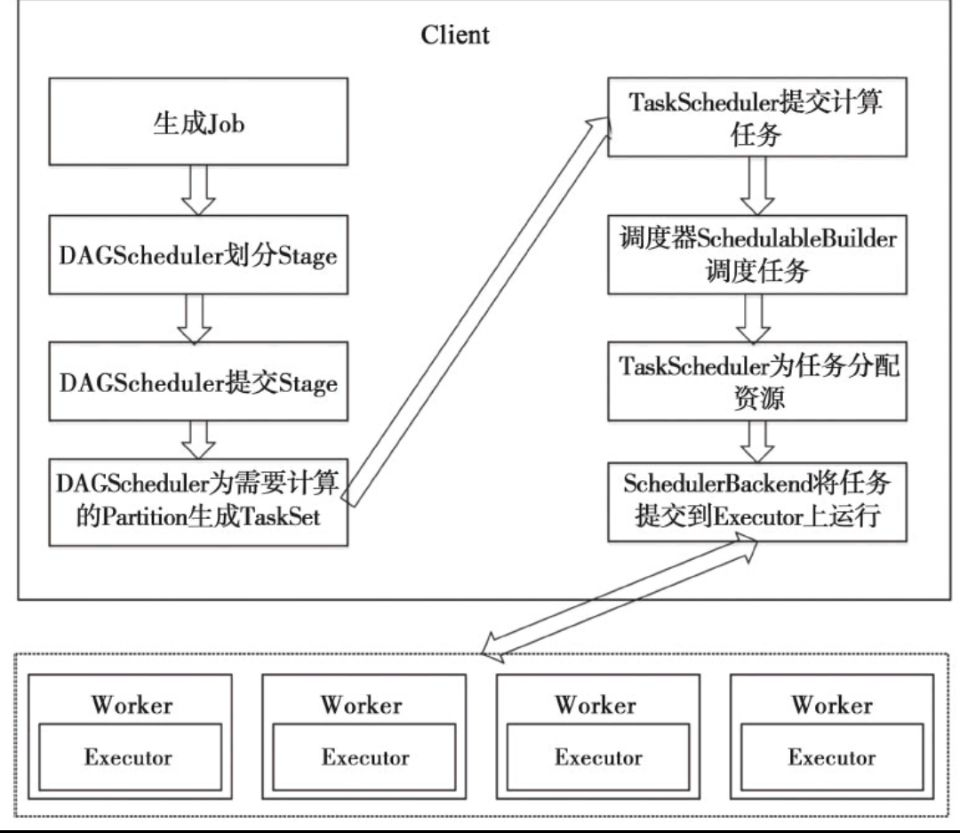
Spark调度模块
Driver 的sc负责和Executor交互,完成任务的分配和调度,在底层,任务调度模块主要包含两大部分:
1)DAGScheduler
2)TaskScheduler
它们负责将用户提交的计算任务按照DAG划分为不同的阶段并且将不同阶段的计算任务提交到集群进行最终的计算。
RDD Objects可以理解为用户实际代码中创建的RDD,这些代码逻辑上组成了一个DAG。
DAGScheduler主要负责分析依赖关系,然后将DAG划分为不同的Stage(阶段),其中每个Stage由可以并发执行的一组Task构成,这些Task的执行逻辑完全相同,只是作用于不同的数据。
在DAGScheduler将这组Task划分完成后,会将这组Task提交到TaskScheduler。TaskScheduler通过Cluster Manager 申请计算资源,比如在集群中的某个Worker Node上启动专属的Executor,并分配CPU、内存等资源。接下来,就是在Executor中运行Task任务,如果缓存中没有计算结果,那么就需要开始计算,同时,计算的结果会回传到Driver或者保存在本地。
Scheduler的实现概述
任务调度模块涉及的最重要的三个类是:
1)org.apache.spark.scheduler.DAGScheduler 前面提到的DAGScheduler的实现。将一个DAG划分为一个一个的Stage阶段(每个Stage是一组Task的集合)然后把Task Set 交给TaskScheduler模块。
2)org.apache.spark.scheduler.TaskScheduler 它的作用是为创建它的SparkContext调度任务,即从DAGScheduler接收不同Stage的任务。向Cluster Manager 申请资源。然后Cluster Manager收到资源请求之后,在Worker为其启动进程
3)org.apache.spark.scheduler.SchedulerBackend 是一个trait,作用是分配当前可用的资源,具体就是向当前等待分配计算资源的Task分配计算资源(即Executor),并且在分配的Executor上启动Task,完成计算的调度过程。
4)AKKA是一个网络通信框架,类似于Netty,此框架在Spark1.8之后已全部替换成Netty
任务调度流程图
Spark架构的更多相关文章
- Spark 架构
本文转之Pivotal的一个工程师的博客.觉得极好. 作者本人经常在StackOverflow上回答一个关系Spark架构的问题,发现整个互联网都没有一篇文章能对Spark总体架构进行很好的描述, ...
- 把传统的基于sql的企业信息中心迁移到spark 架构应该考虑的几点思考...[修改中]
把传统的基于sql的企业信息中心迁移到spark 架构应该考虑的几点 * 理由: 赶时髦, 这还不够大条么? > 数据都设计为NO-SQL模式, 只有需要search的才建立2级索引. 就可以 ...
- 从spark架构中透视job
本博文的主要内容如下: 1.通过案例观察Spark架构 2.手动绘制Spark内部架构 3.Spark Job的逻辑视图解析 4.Spark Job的物理视图解析 1.通过案例观察Spark架构 sp ...
- 大数据 Spark 架构
一.Spark的产生背景起源 1.spark特点 1.1轻量级快速处理 Saprk允许传统的hadoop集群中的应用程序在内存中已100倍的速度运行即使在磁盘上也比传统的hadoop快10倍,Spar ...
- [Spark]Spark章1 Spark架构浅析
Spark架构 Spark架构采用了分布式计算中的Master-Slave模型.集群中运行Master进程的节点称为Master,同样,集群中含有Worker进程的节点为Slave.Master负责控 ...
- Spark集群基础概念 与 spark架构原理
一.Spark集群基础概念 将DAG划分为多个stage阶段,遵循以下原则: 1.将尽可能多的窄依赖关系的RDD划为同一个stage阶段. 2.当遇到shuffle操作,就意味着上一个stage阶段结 ...
- Spark 概念学习系列之从spark架构中透视job(十六)
本博文的主要内容如下: 1.通过案例观察Spark架构 2.手动绘制Spark内部架构 3.Spark Job的逻辑视图解析 4.Spark Job的物理视图解析 1.通过案例观察Spark架构 s ...
- Spark架构解析(转)
Application: Application是创建了SparkContext实例对象的Spark用户,包含了Driver程序, Spark-shell是一个应用程序,因为spark-shell在启 ...
- Spark- Spark内核架构原理和Spark架构深度剖析
Spark内核架构原理 1.Driver 选spark节点之一,提交我们编写的spark程序,开启一个Driver进程,执行我们的Application应用程序,也就是我们自己编写的代码.Driver ...
随机推荐
- Zabbix告警脚本-短信
[root@iot-svndata02 bin]# cat zbsms.sh #!/bin/sh #curl http://221.179.180.137:8080/smsaServer/lkSend ...
- Teemo's tree problem
题目链接 : https://nanti.jisuanke.com/t/29228 There is an apple tree in Teemo's yard. It contains n node ...
- Python项目--Scrapy框架(二)
本文主要是利用scrapy框架爬取果壳问答中热门问答, 精彩问答的相关信息 环境 win8, python3.7, pycharm 正文 1. 创建scrapy项目文件 在cmd命令行中任意目录下执行 ...
- 初始Spring mvc
转自:http://elf8848.iteye.com/blog/875830很棒的一篇博客,想了解SpringMvc的入门选手可以去看看. 一,核心类与接口: DispatcherServlet - ...
- 使用GO开发ChainCode
本来不会GO,最近突击学了些GO的基础,就开始搞chaincode了. 首先给大家推荐一个非常好的Hyperldeger Fabric项目 marble:https://github.com/ibm- ...
- POJ 3107.Godfather 树形dp
Godfather Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 7536 Accepted: 2659 Descrip ...
- python基础之Day11
一.函数是对象 函数是第一类对象的含义是函数可以被当作数据处理 二.函数的嵌套定义 def f1(): def f2(): print('from f2') f2()f1() 三.名称空间与作用域 1 ...
- unable to bind listening socket for address '127.0.0.1:9090': Address already in use (98)
unable to bind listening socket for address '127.0.0.1:9090': Address already in use (98) php-fpm 启动 ...
- Python中添加中文注释报错SyntaxError: Non-UTF-8 code starting with '\xc1'
问题:在文本编辑器中编辑Python文件时添加中文注释,运行python文件时报错.SyntaxError: Non-UTF-8 code starting with '\xc1' 解决方法:在文本开 ...
- 51nod 1344
一个很简单的算法题,求最小的前缀和,就是要注意数据范围要开一个longlong #include<iostream> using namespace std; int main() { i ...