Mac配置Scala和Spark最详细过程
Mac配置Scala和Spark最详细过程
原文链接: http://www.cnblogs.com/blog5277/p/8567337.html
原文作者: 博客园--曲高终和寡
一,准备工作
1.下载Scala http://www.scala-lang.org/download/ 拖到最下面,下载for mac的版本

2.下载Spark http://spark.apache.org/downloads.html
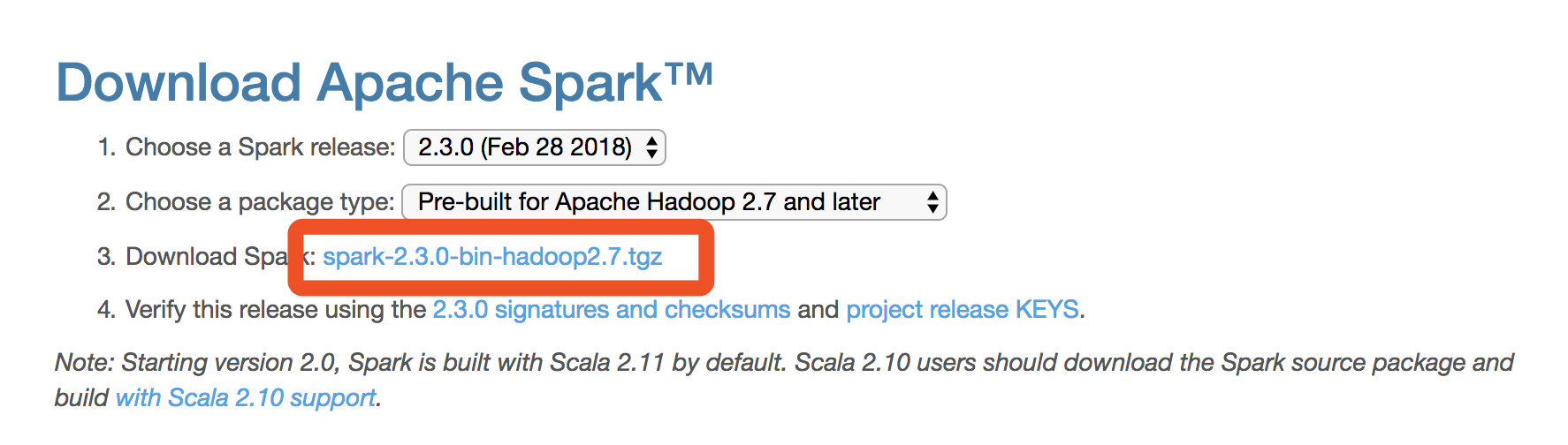
记得选版本啊,如果你是按照我之前的
Mac配置Hadoop最详细过程
配置的话就是最新的2.7版本以后的,就直接点3下载就可以了
二.安装Scala
1.我个人喜欢把各个软件都放在/Library/目录下,所以这里我也在改目录下新建文件夹,提取后放进去,如下图所示:
2.配置Scala的环境变量,打开终端,输入以下代码(涉及系统环境变量修改,所以应该会让你输入Mac的密码):
sudo vim /etc/profile
在/Library/Scala/scala-2.12.4路径上,同时按下 option + command +c 复制你选中的文件的路径 , 粘贴出来如下:
/Library/Scala/scala-2.12.4
然后在刚刚你打开的终端里面,按 i 进入编辑模式 , 输入如下代码(如果路径/版本不一样,记得替换成你刚刚粘贴的那个)
export SCALA_HOME=/Library/Scala/scala-2.12.4
export PATH=$PATH:$SCALA_HOME/bin
按esc退出编辑模式,输入:wq!保存并退出,输入以下代码:
source /etc/profile
使得改动立刻生效,输入:
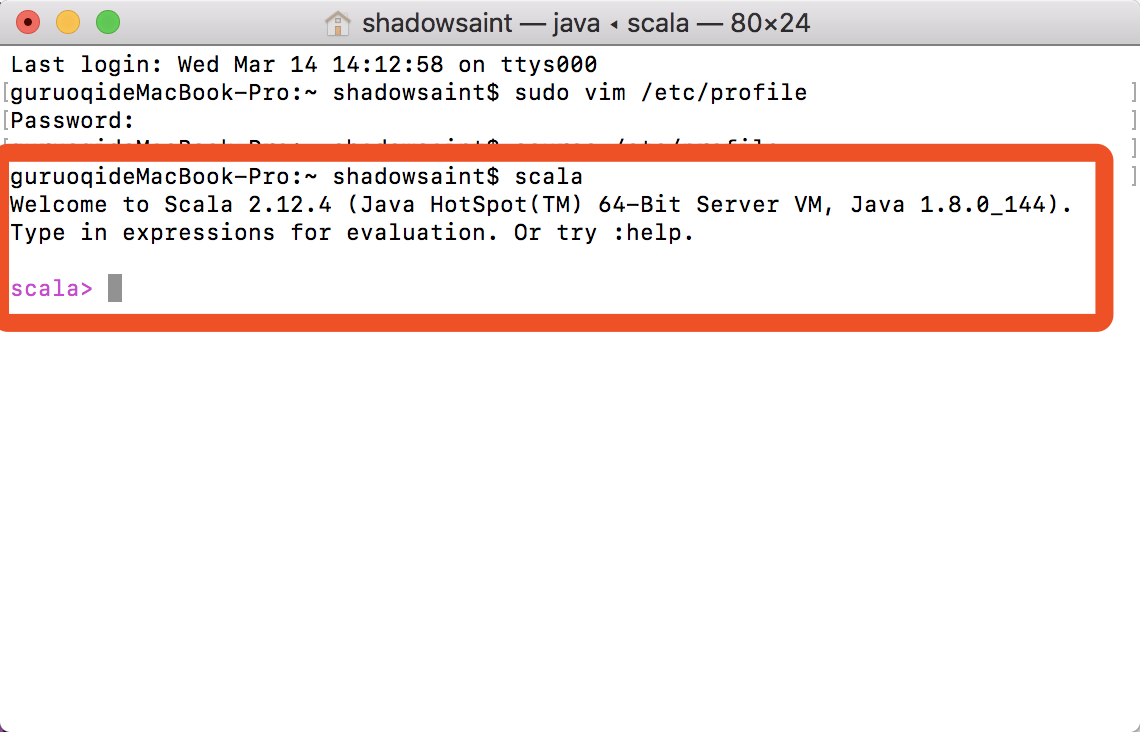
scala
即可看到你已经成功配置了Scala,如下图所示:
按下 control + c 或者输入 :quit 可以退出命令行Scala工具
三,安装Spark
1.在/Library/下新建目录,把之前下载的东西提取并放进去,如下图所示:
2.配置Spark的环境变量,打开终端,输入以下代码(涉及系统环境变量修改,所以应该会让你输入Mac的密码):
sudo vim /etc/profile
在/Library/Spark/spark-2.3.0-bin-hadoop2.7路径上,同时按下 option + command +c 复制你选中的文件的路径 , 粘贴出来如下:
/Library/Spark/spark-2.3.0-bin-hadoop2.7
然后在刚刚你打开的终端里面,按 i 进入编辑模式 , 输入如下代码(如果路径/版本不一样,记得替换成你刚刚粘贴的那个)
export SPARK_HOME=/Library/Spark/spark-2.3.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
按esc退出编辑模式,输入:wq!保存并退出,输入以下代码:
source /etc/profile
使得改动立刻生效
3.进入/Library/Spark/spark-2.3.0-bin-hadoop2.7/conf目录下,将 spark-env.sh.template 复制一份 , 把复制出来的 spark-env.sh的副本.template 重命名为 spark-env.sh 右键-->打开方式-->文本编辑.app
在末尾加入下面代码:
export SCALA_HOME=/Library/Spark/spark-2.3.0-bin-hadoop2.7 export SPARK_MASTER_IP=localhost export SPARK_WORKER_MEMORY=4g
4.截止上面,Spark已经配置完成了,下面测试一下,在终端中跳转至 /Library/Spark/spark-2.3.0-bin-hadoop2.7/sbin
cd /Library/Spark/spark-2.3.0-bin-hadoop2.7/sbin
输入
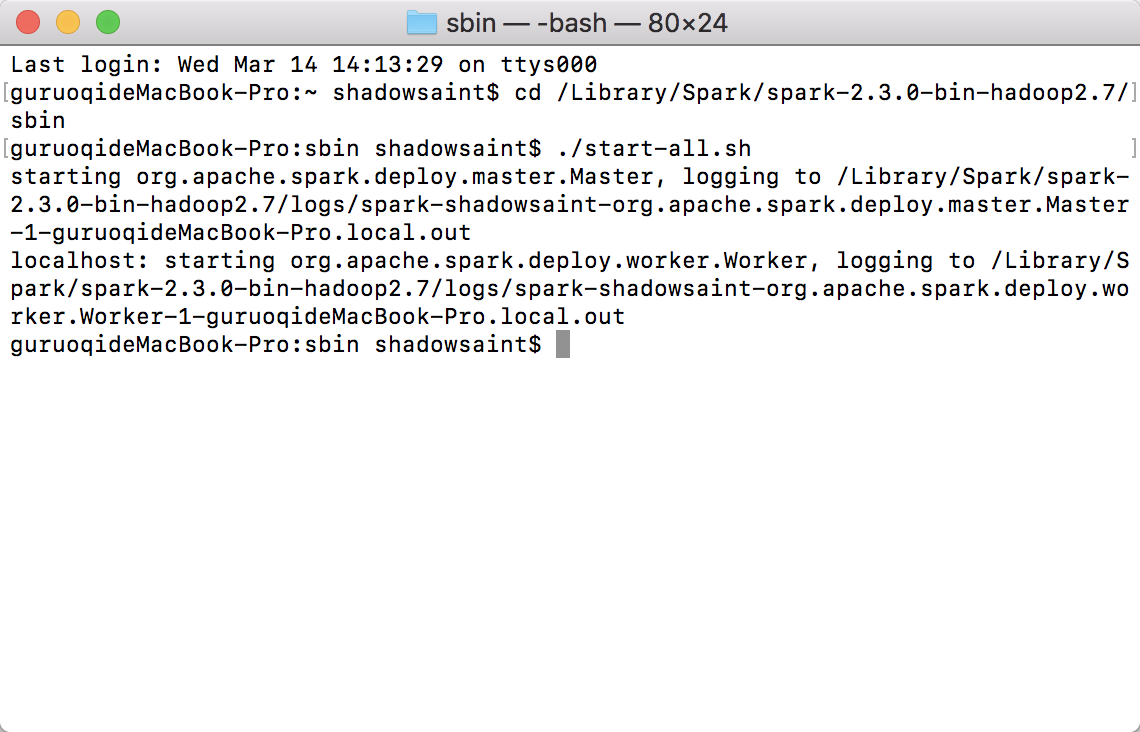
./start-all.sh
如下图所示,即为启动成功:
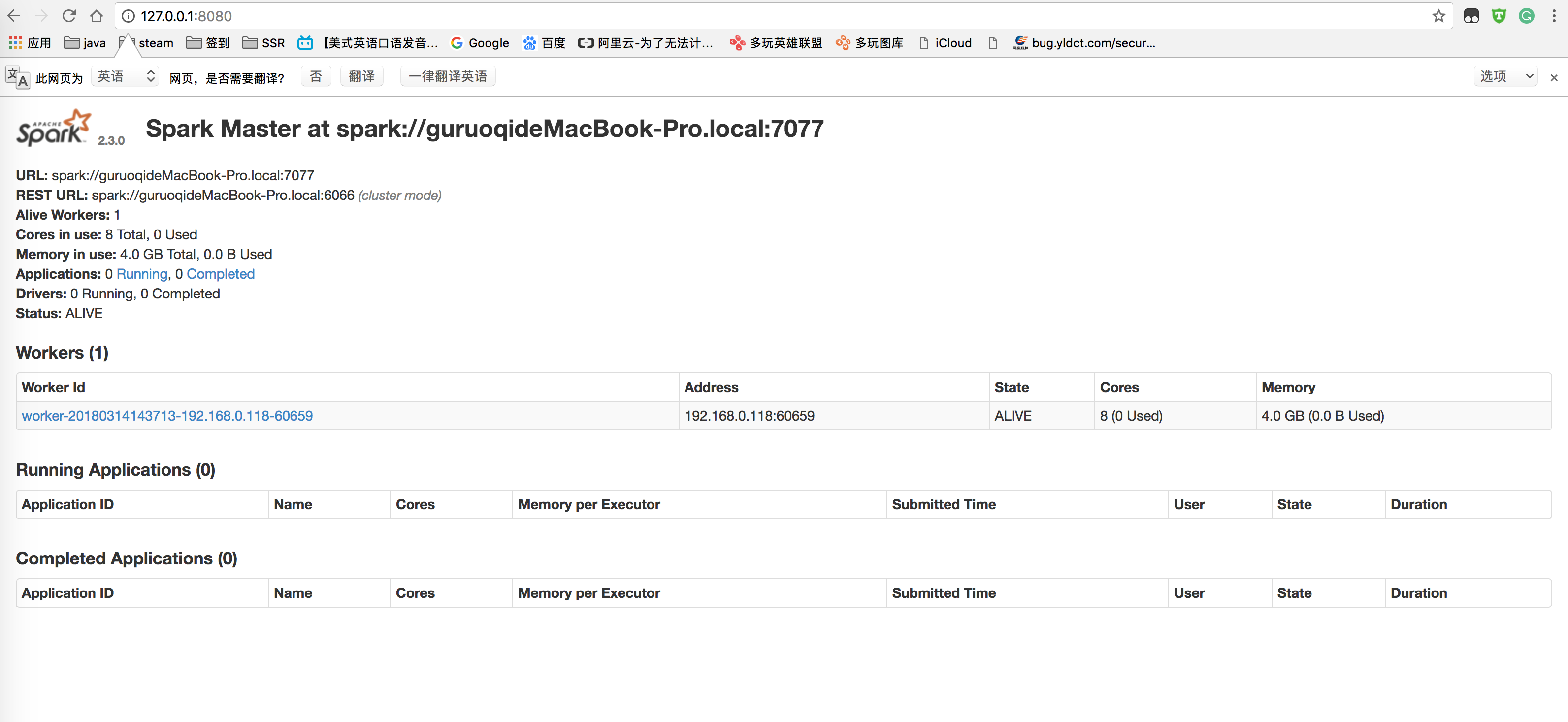
在浏览器输入以下网址即可看到打开的页面:
127.0.0.1:8080
关闭Spark的话还是在 /Library/Spark/spark-2.3.0-bin-hadoop2.7/sbin 目录下,输入
./stop-all.sh
Mac配置Scala和Spark最详细过程的更多相关文章
- idea配置scala编写spark wordcount程序
1.创建scala maven项目 选择骨架的时候为org.scala-tools.archetypes:scala-aechetype-simple 1.2 2.导入包,进入spark官网Docum ...
- Spark shuffle详细过程
有许多场景下,我们需要进行跨服务器的数据整合,比如两个表之间,通过Id进行join操作,你必须确保所有具有相同id的数据整合到相同的块文件中.那么我们先说一下mapreduce的shuffle过程. ...
- idea配置scala和spark
1 下载idea 路径https://www.jetbrains.com/idea/download/#section=windows 2安装spark spark-2.1.0-bin-hadoo ...
- 使用maven配置scala Hadoop spark开发环境
1. 新建maven project 2. Group id : org.scala-tools.archetypes Artifact id : scala-archetype-simple Ver ...
- Mac配置Hadoop最详细过程
Mac配置Hadoop最详细过程 原文链接: http://www.cnblogs.com/blog5277/p/8565575.html 原文作者: 博客园-曲高终和寡 https://www.cn ...
- <spark入门><Intellj环境配置><scala>rk入门><Intellj环境配置><scala>
# 写在前面: 准备开始学spark,于是准备在IDE配一个spark的开发环境. 嫌这篇格式不好的看这里链接 用markdown写的,懒得调格式了,么么哒 # 相关配置: ## 关于系统 * mac ...
- Mac下 如何配置虚拟机软件Parallel Desktop--超详细
Mac下 如何配置虚拟机软件Pparallel Desktop--超详细 Mac 的双系统解决方案有两种,一种是使用Boot Camp分区安装独立的Windows,一种是通过安装Parallels D ...
- Redis主从配置详细过程
Redis的主从复制功能非常强大,一个master可以拥有多个slave,而一个slave又可以拥有多个slave,如此下去,形成了强大的多级服务器集群架构.下面楼主简单的进行一下配置. 1.上面安装 ...
- STM32F0xx_PWR低功耗配置详细过程
Ⅰ.概述 今天总结PWR部分知识,请看“STM32F0x128参考手册V8”第六章.提供的软件工程是关于电源管理中的停机模式,工程比较常见,但也是比较简单的一个实例,根据项目的不同还需要适当修改或者添 ...
随机推荐
- 对象copy的两种方式--序列化--clone
对象实现copy有多中方式,最土的方法就是直接new,然后塞值,不过这种方法是真的low,下面着重说说Object类中的clone() 和 序列化反序列化copy Object 中 clone的方法 ...
- 【RabbitMQ】工作模式介绍
一.前言 之前,笔者写过< CentOS 7.2 安装 RabbitMQ> 这篇文章,今天整理一下 RabbitMQ 相关的笔记便于以后复习. 二.模式介绍 在 RabbitMQ 官网上提 ...
- 苏宁基于Spark Streaming的实时日志分析系统实践 Spark Streaming 在数据平台日志解析功能的应用
https://mp.weixin.qq.com/s/KPTM02-ICt72_7ZdRZIHBA 苏宁基于Spark Streaming的实时日志分析系统实践 原创: AI+落地实践 AI前线 20 ...
- WordCount扩展与优化
合作者:201631062327,201631062128码云地址:https://gitee.com/LIUJIA6/WordCount3 一:项目说明 本次项目是在上次作业WorldCount的基 ...
- JDBC事务(二)转账示例
示例采用三层框架 web层: package cn.sasa.web; import java.io.IOException; import javax.servlet.ServletExceptio ...
- SQL Server (MSSQLSERVER) 服务由于下列服务特定错误而终止: %%17051
问题出现:今天在给客户调试项目的时候,发现无法连接SQL server数据库 解决过程:1.在cmd命令窗口输入services.msc,打开服务窗口,找到SQL Server (MSSQLSERVE ...
- 【LeetCode每天一题】Combinations(组合)
Given two integers n and k, return all possible combinations of k numbers out of 1 ... n. Example: I ...
- 53.CSS---CSS水平垂直居中常见方法总结
CSS水平垂直居中常见方法总结 1.元素水平居中 当然最好使的是: margin: 0 auto; 居中不好使的原因: 1.元素没有设置宽度,没有宽度怎么居中嘛! 2.设置了宽度依然不好使,你设置的是 ...
- 前端JS常见面试题(代码自撸)
题目一示例: 适用于子数组等长度及不等长度. let arr = [ [1,2,3], [5,6,7,8], [9,10,11,12,13] ] function arrayDiagonal(arr) ...
- GDScript 格式化字符串
GDScript offers a feature called format strings, which allows reusing text templates to succinctly c ...