[MapReduce_8] MapReduce 中的自定义分区实现
0. 说明
设置分区数量 && 编写自定义分区代码
1. 设置分区数量
分区(Partition)
分区决定了指定的 Key 进入到哪个 Reduce 中
分区目的:把相同的 Key 发送给同一个 Reduce
默认 hash 分区,算法
// 返回的分区号
(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks
设置分区数
job.setNumReduceTasks(3);
2. 代码编写
在 [MapReduce_1] 运行 Word Count 示例程序 代码基础之上进行以下操作
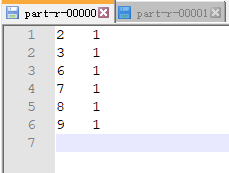
实现将文本中的数字存放在分区0,数字之外的内容放置到分区1
【2.1 编写 MyPartition.java】
package hadoop.mr.partition; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner; /**
* MapReduce 自定义分区
*/
public class MyPartition extends Partitioner<Text, IntWritable> {
/**
* 自定义分区将数字放在0号分区,其余放在1号分区
*/
@Override
public int getPartition(Text key, IntWritable value, int numPartitions) {
try {
Integer.parseInt(key.toString());
return 0;
} catch (Exception e) {
return 1;
}
}
}
【2.2 修改 WCApp.java】

【2.3 最终结果】

[MapReduce_8] MapReduce 中的自定义分区实现的更多相关文章
- [大牛翻译系列]Hadoop(1)MapReduce 连接:重分区连接(Repartition join)
4.1 连接(Join) 连接是关系运算,可以用于合并关系(relation).对于数据库中的表连接操作,可能已经广为人知了.在MapReduce中,连接可以用于合并两个或多个数据集.例如,用户基本信 ...
- Hadoop mapreduce自定义分区HashPartitioner
本文发表于本人博客. 在上一篇文章我写了个简单的WordCount程序,也大致了解了下关于mapreduce运行原来,其中说到还可以自定义分区.排序.分组这些,那今天我就接上一次的代码继续完善实现自定 ...
- 在hadoop作业中自定义分区和归约
当遇到有特殊的业务需求时,需要对hadoop的作业进行分区处理 那么我们可以通过自定义的分区类来实现 还是通过单词计数的例子,JMapper和JReducer的代码不变,只是在JSubmit中改变了设 ...
- Hadoop学习之路(6)MapReduce自定义分区实现
MapReduce自带的分区器是HashPartitioner 原理:先对map输出的key求hash值,再模上reduce task个数,根据结果,决定此输出kv对,被匹配的reduce任务取走. ...
- 【Hadoop】MapReduce自定义分区Partition输出各运营商的手机号码
MapReduce和自定义Partition MobileDriver主类 package Partition; import org.apache.hadoop.io.NullWritable; i ...
- MapReduce之自定义分区器Partitioner
@ 目录 问题引出 默认Partitioner分区 自定义Partitioner步骤 Partition分区案例实操 分区总结 问题引出 要求将统计结果按照条件输出到不同文件中(分区). 比如:将统计 ...
- Hadoop学习笔记—11.MapReduce中的排序和分组
一.写在之前的 1.1 回顾Map阶段四大步骤 首先,我们回顾一下在MapReduce中,排序和分组在哪里被执行: 从上图中可以清楚地看出,在Step1.4也就是第四步中,需要对不同分区中的数据进行排 ...
- MapReduce中的Join算法
在关系型数据库中Join是非常常见的操作,各种优化手段已经到了极致.在海量数据的环境下,不可避免的也会碰到这种类型的需求,例如在数据分析时需要从不同的数据源中获取数据.不同于传统的单机模式,在分布式存 ...
- [MapReduce_7] MapReduce 中的排序
0. 说明 部分排序 && 全排序 && 采样 && 二次排序 1. 介绍 sort 是根据 Key 进行排序 [部分排序] 在每个分区中,分别进行排序 ...
随机推荐
- 4 spring 创建对象的三种方式
方式1. 通过构造方法创建 1.1 无参构造创建:默认情况. 1.2 有参构造创建:需要明确配置 1.2.1 需要在类中提供有参构造方法 1.2.2 在 ...
- SQL 必知必会·笔记<18>管理事务处理
事务处理是一种机制,用来管理必须成批执行的SQL操作,保证数据库不包含不完整的操作结果.利用事务处理,可以保证一组操作不会中途停止,它们要 么完全执行,要么完全不执行(除非明确指示).如果没有错误发生 ...
- xhr.withCredentials发送跨域请求凭证
一.前言 今天遇到一个坑,浏览器请求数据的时候gg了.浏览器报错如下图: 因为请求头部设置了credentis mode is 'include', 从上面可以看出是Access-Control-Al ...
- [HAOI 2016]找相同字符
Description 题库链接 给定两个只含小写字母字符串 \(s_1,s_2\) ,求出在两个字符串中各取出一个子串使得这两个子串相同的方案数.两个方案不同当且仅当这两个子串中有一个位置不同. \ ...
- httpd配置文件httpd.conf规则说明和一些基本指令
apache httpd系列文章:http://www.cnblogs.com/f-ck-need-u/p/7576137.html 本文主要介绍的是httpd的配置文件,包括一些最基本的指令.配置规 ...
- SpringMVC4+Hibernate5+SQLServer 2014 整合(包括增删改查分页)
前言 前面整合完了SpringMVC+MyBatis,自然也少不了SpringMVC+Hibernate,严格来说Hibernate才是我们真正想要的ORM框架么.只记得最初学习hibernate时, ...
- python元祖操作和内置方法
1 元祖:元祖可以理解为一个不可变的列表 2 用途:用于存放多个值,当存放的多个值只有读的需求而没有改的需求时用元祖最合适 3 定义:在()内用逗号分隔开多个任意类型的值.注意:当只有一个元素的时候, ...
- 探秘 Java 热部署二(Java agent premain)
# 前言 在前文 探秘 Java 热部署 中,我们通过在死循环中重复加载 ClassLoader 和 Class 文件实现了热部署的功能,但我们也指出了缺点-----不够灵活.需要手动修改文件等操作. ...
- JAVAEmail工具错误java.lang.ClassNotFoundException: javax.activation.DataSource
JDK9以上或JDK6以下使用mail.jar包不加JAF的activation.jar包会抛出该错误!JDK6以上不需要加该jar包: 参考原文 https://stackoverflow.com/ ...
- Python入门到精通学习书籍推荐!
1.Python基础教程(第2版 修订版)<Python基础教程(第2版修订版)>包括Python程序设计的方方面面,内容涉及的范围较广,既能为初学者夯实基础,又能帮助程序员提升技能,适合 ...