Hadoop学习之路(6)MapReduce自定义分区实现
MapReduce自带的分区器是HashPartitioner
原理:先对map输出的key求hash值,再模上reduce task个数,根据结果,决定此输出kv对,被匹配的reduce任务取走。
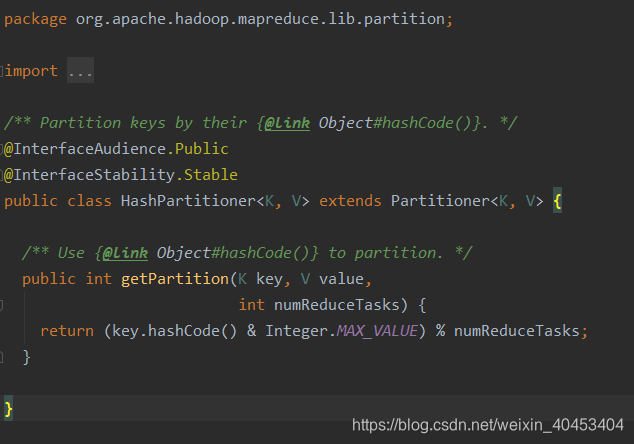
自定义分分区需要继承Partitioner,复写getpariton()方法
自定义分区类:
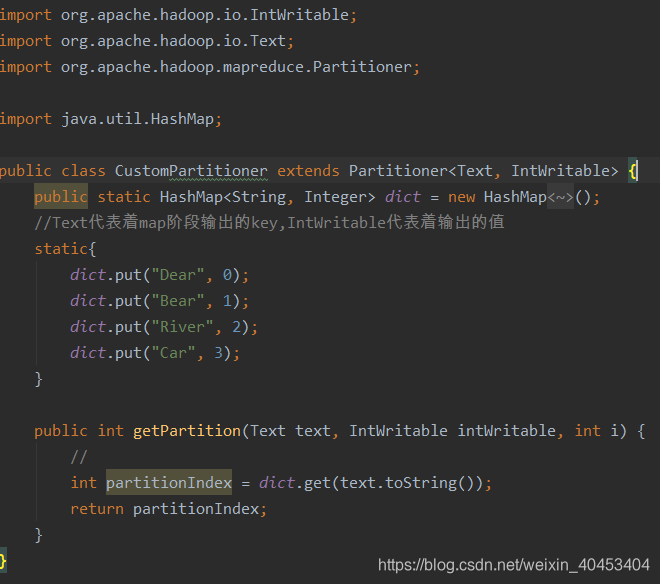
注意:map的输出是<K,V>键值对
其中int partitionIndex = dict.get(text.toString()),partitionIndex是获取K的值
附:被计算的的文本
Dear Dear Bear Bear River Car Dear Dear Bear Rive
Dear Dear Bear Bear River Car Dear Dear Bear Rive
需要在main函数中设置,指定自定义分区类
自定义分区类:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
import java.util.HashMap;
public class CustomPartitioner extends Partitioner<Text, IntWritable> {
public static HashMap<String, Integer> dict = new HashMap<String, Integer>();
//Text代表着map阶段输出的key,IntWritable代表着输出的值
static{
dict.put("Dear", 0);
dict.put("Bear", 1);
dict.put("River", 2);
dict.put("Car", 3);
}
public int getPartition(Text text, IntWritable intWritable, int i) {
//
int partitionIndex = dict.get(text.toString());
return partitionIndex;
}
}
注意:map的输出结果是键值对<K,V>,int partitionIndex = dict.get(text.toString());中的partitionIndex是map输出键值对中的键的值,也就是K的值。
Maper类:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMap extends Mapper<LongWritable, Text, Text, IntWritable> {
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] words = value.toString().split("\t");
for (String word : words) {
// 每个单词出现1次,作为中间结果输出
context.write(new Text(word), new IntWritable(1));
}
}
}
Reducer类:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMap extends Mapper<LongWritable, Text, Text, IntWritable> {
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] words = value.toString().split("\t");
for (String word : words) {
// 每个单词出现1次,作为中间结果输出
context.write(new Text(word), new IntWritable(1));
}
}
}
main函数:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountMain {
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
if (args.length != 2 || args == null) {
System.out.println("please input Path!");
System.exit(0);
}
Configuration configuration = new Configuration();
configuration.set("mapreduce.job.jar","/home/bruce/project/kkbhdp01/target/com.kaikeba.hadoop-1.0-SNAPSHOT.jar");
Job job = Job.getInstance(configuration, WordCountMain.class.getSimpleName());
// 打jar包
job.setJarByClass(WordCountMain.class);
// 通过job设置输入/输出格式
//job.setInputFormatClass(TextInputFormat.class);
//job.setOutputFormatClass(TextOutputFormat.class);
// 设置输入/输出路径
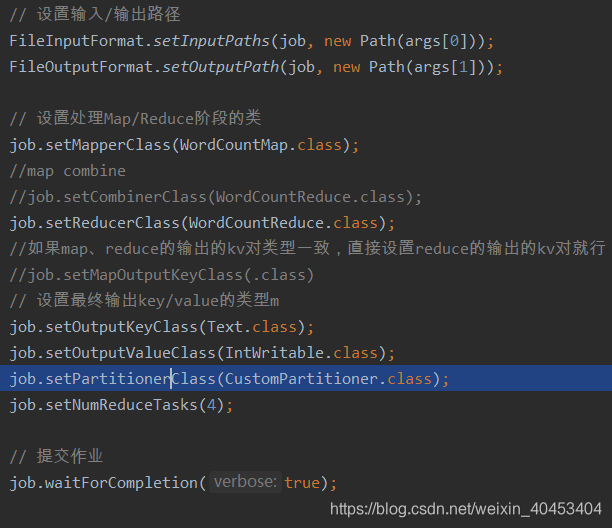
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 设置处理Map/Reduce阶段的类
job.setMapperClass(WordCountMap.class);
//map combine
//job.setCombinerClass(WordCountReduce.class);
job.setReducerClass(WordCountReduce.class);
//如果map、reduce的输出的kv对类型一致,直接设置reduce的输出的kv对就行;如果不一样,需要分别设置map, reduce的输出的kv类型
//job.setMapOutputKeyClass(.class)
// 设置最终输出key/value的类型m
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setPartitionerClass(CustomPartitioner.class);
job.setNumReduceTasks(4);
// 提交作业
job.waitForCompletion(true);
}
}
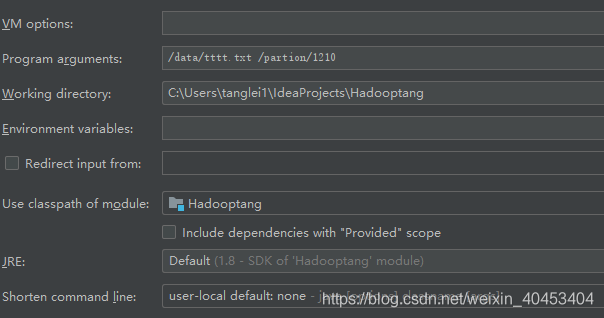
main函数参数设置:
Hadoop学习之路(6)MapReduce自定义分区实现的更多相关文章
- Hadoop学习之路(7)MapReduce自定义排序
本文测试文本: tom 20 8000 nancy 22 8000 ketty 22 9000 stone 19 10000 green 19 11000 white 39 29000 socrate ...
- Hadoop学习之路(5)Mapreduce程序完成wordcount
程序使用的测试文本数据: Dear River Dear River Bear Spark Car Dear Car Bear Car Dear Car River Car Spark Spark D ...
- 阿里封神谈hadoop学习之路
阿里封神谈hadoop学习之路 封神 2016-04-14 16:03:51 浏览3283 评论3 发表于: 阿里云E-MapReduce >> 开源大数据周刊 hadoop 学生 s ...
- 《Hadoop学习之路》学习实践
(实践机器:blog-bench) 本文用作博文<Hadoop学习之路>实践过程中遇到的问题记录. 本文所学习的博文为博主“扎心了,老铁” 博文记录.参考链接https://www.cnb ...
- Hadoop学习之路(十三)MapReduce的初识
MapReduce是什么 首先让我们来重温一下 hadoop 的四大组件: HDFS:分布式存储系统 MapReduce:分布式计算系统 YARN:hadoop 的资源调度系统 Common:以上三大 ...
- Hadoop mapreduce自定义分区HashPartitioner
本文发表于本人博客. 在上一篇文章我写了个简单的WordCount程序,也大致了解了下关于mapreduce运行原来,其中说到还可以自定义分区.排序.分组这些,那今天我就接上一次的代码继续完善实现自定 ...
- Hadoop 学习之路(三)—— 分布式计算框架 MapReduce
一.MapReduce概述 Hadoop MapReduce是一个分布式计算框架,用于编写批处理应用程序.编写好的程序可以提交到Hadoop集群上用于并行处理大规模的数据集. MapReduce作业通 ...
- 【Hadoop】MapReduce自定义分区Partition输出各运营商的手机号码
MapReduce和自定义Partition MobileDriver主类 package Partition; import org.apache.hadoop.io.NullWritable; i ...
- Hadoop学习之路(二十)MapReduce求TopN
前言 在Hadoop中,排序是MapReduce的灵魂,MapTask和ReduceTask均会对数据按Key排序,这个操作是MR框架的默认行为,不管你的业务逻辑上是否需要这一操作. 技术点 MapR ...
随机推荐
- HDU4195 Regular Convex Polygon (正多边形、外接圆)
题意: 给你正n边形上的三个点,问n最少为多少 思路: 三个点在多边形上,所以三个点的外接圆就是这个正多边形的外接圆,余弦定理求出每个角的弧度值,即该角所对边的圆周角,该边对应的圆心角为圆心角的二倍. ...
- HDU4192 Guess the Numbers(表达式计算、栈)
题意: 给你一个带括号.加减.乘的表达式,和n个数$(n\leq 5)$,问你带入这几个数可不可能等于n 思路: 先处理表达式:先将中缀式转化为逆波兰表达式 转换过程需要用到栈,具体过程如下:1)如果 ...
- css 浏览兼容问题及解决办法 (2)
1.div的垂直居中问题 vertical-align:middle; 将行距增加到和整个DIV一样高 line-height:200px; 然后插入文字,就垂直居中了.缺点是要控制内容不要换行 2. ...
- 3D点云配准算法简述
蝶恋花·槛菊愁烟兰泣露 槛菊愁烟兰泣露,罗幕轻寒,燕子双飞去. 明月不谙离恨苦,斜光到晓穿朱户. 昨夜西风凋碧树,独上高楼,望尽天涯路. 欲寄彩笺兼尺素.山长水阔知何处? --晏殊 导读: 3D点云 ...
- Vue项目使用vant框架
近期在开发h5端项目,用到vant框架,vant是一款基于Vue的移动UI组件,看了vant的官方文档(https://youzan.github.io/vant/#/zh-CN/)感觉不错,功能比较 ...
- k8s系列---Service之ExternalName用法
需求:需要两个不同的namespace之间的不同pod可以通过name的形式访问 实现方式: A:在其他pod内ping [svcname].[namespace] ping出来到结果就是svc的ip ...
- vsftp管理用户
[root@localhost vsftpd]# cat auto_createftp.py #!/usr/bin/env python #_*_coding:utf-8_*_ #date:20180 ...
- nginx官网版本说明
nginx软件下载:http://nginx.org/en/download.html Mainline version:Nginx 正在主力开发的版本Stable version:最新稳定版,生产环 ...
- python随用随学20200118-函数的高级特性
高阶函数 话说当年C语言和Java里好像都有这么个东西...忘了 一句话说就是函数名本身就是一个引用. 可以作为变量传递. 一个简单的例子: def power_demo(x): return x* ...
- Go语言SQL注入和防注入
Go语言SQL注入和防注入 一.SQL注入是什么 SQL注入是一种注入攻击手段,通过执行恶意SQL语句,进而将任意SQL代码插入数据库查询,从而使攻击者完全控制Web应用程序后台的数据库服务器.攻击者 ...