[MapReduce_8] MapReduce 中的自定义分区实现
0. 说明
设置分区数量 && 编写自定义分区代码
1. 设置分区数量
分区(Partition)
分区决定了指定的 Key 进入到哪个 Reduce 中
分区目的:把相同的 Key 发送给同一个 Reduce
默认 hash 分区,算法
// 返回的分区号
(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks
设置分区数
job.setNumReduceTasks(3);
2. 代码编写
在 [MapReduce_1] 运行 Word Count 示例程序 代码基础之上进行以下操作
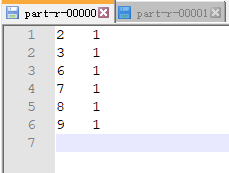
实现将文本中的数字存放在分区0,数字之外的内容放置到分区1
【2.1 编写 MyPartition.java】
package hadoop.mr.partition; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner; /**
* MapReduce 自定义分区
*/
public class MyPartition extends Partitioner<Text, IntWritable> {
/**
* 自定义分区将数字放在0号分区,其余放在1号分区
*/
@Override
public int getPartition(Text key, IntWritable value, int numPartitions) {
try {
Integer.parseInt(key.toString());
return 0;
} catch (Exception e) {
return 1;
}
}
}
【2.2 修改 WCApp.java】

【2.3 最终结果】

[MapReduce_8] MapReduce 中的自定义分区实现的更多相关文章
- [大牛翻译系列]Hadoop(1)MapReduce 连接:重分区连接(Repartition join)
4.1 连接(Join) 连接是关系运算,可以用于合并关系(relation).对于数据库中的表连接操作,可能已经广为人知了.在MapReduce中,连接可以用于合并两个或多个数据集.例如,用户基本信 ...
- Hadoop mapreduce自定义分区HashPartitioner
本文发表于本人博客. 在上一篇文章我写了个简单的WordCount程序,也大致了解了下关于mapreduce运行原来,其中说到还可以自定义分区.排序.分组这些,那今天我就接上一次的代码继续完善实现自定 ...
- 在hadoop作业中自定义分区和归约
当遇到有特殊的业务需求时,需要对hadoop的作业进行分区处理 那么我们可以通过自定义的分区类来实现 还是通过单词计数的例子,JMapper和JReducer的代码不变,只是在JSubmit中改变了设 ...
- Hadoop学习之路(6)MapReduce自定义分区实现
MapReduce自带的分区器是HashPartitioner 原理:先对map输出的key求hash值,再模上reduce task个数,根据结果,决定此输出kv对,被匹配的reduce任务取走. ...
- 【Hadoop】MapReduce自定义分区Partition输出各运营商的手机号码
MapReduce和自定义Partition MobileDriver主类 package Partition; import org.apache.hadoop.io.NullWritable; i ...
- MapReduce之自定义分区器Partitioner
@ 目录 问题引出 默认Partitioner分区 自定义Partitioner步骤 Partition分区案例实操 分区总结 问题引出 要求将统计结果按照条件输出到不同文件中(分区). 比如:将统计 ...
- Hadoop学习笔记—11.MapReduce中的排序和分组
一.写在之前的 1.1 回顾Map阶段四大步骤 首先,我们回顾一下在MapReduce中,排序和分组在哪里被执行: 从上图中可以清楚地看出,在Step1.4也就是第四步中,需要对不同分区中的数据进行排 ...
- MapReduce中的Join算法
在关系型数据库中Join是非常常见的操作,各种优化手段已经到了极致.在海量数据的环境下,不可避免的也会碰到这种类型的需求,例如在数据分析时需要从不同的数据源中获取数据.不同于传统的单机模式,在分布式存 ...
- [MapReduce_7] MapReduce 中的排序
0. 说明 部分排序 && 全排序 && 采样 && 二次排序 1. 介绍 sort 是根据 Key 进行排序 [部分排序] 在每个分区中,分别进行排序 ...
随机推荐
- Xshell连接ESXI方法
第一步.ESXI打开ssh功能按住F2进入设置如下图: 第二步.输入密码 第三步.选择Troubleshooting Options 回车 第四步.选择Enable SSH 这里只介绍了一种方式打开E ...
- Spring Session - 使用Redis存储HttpSession例子
目的 使用Redis存储管理HttpSession: 添加pom.xml 该工程基于Spring Boot,同时我们将使用Spring IO Platform来维护依赖版本号: 引入的依赖有sprin ...
- python虚拟环境 | virtualenv 的简单使用 (图文)
一.创建virtualenv虚拟环境 mkvirtualenv -p 版本号 虚拟名 mkvirtualenv -p python3 env_1 python3:版本号 env_1: 虚拟环境名称 创 ...
- SpringCloud Eureka服务注册及发现——服务端/客户端/消费者搭建
Eureka 是 Netflix 出品的用于实现服务注册和发现的工具. Spring Cloud 集成了 Eureka,并提供了开箱即用的支持.其中, Eureka 又可细分为 Eureka Serv ...
- java ee期末项目相关
1.项目简介 本项目是对纸杯生产进行管理的的一个系统,从前端接收到订单,然后根据订单内容进行纸杯的生产.如下为该系统的总流程图: 1.项目系统架构图 3.系统用例图 4.ER图 主要的代码和相关文件见 ...
- BizTalk 新增/修改/删除 XmlDocument 名字空间的高效方法
新增一个名字空间 public class AddXmlNamespaceStream : XmlTranslatorStream { private String namespace_; priva ...
- CentOS 7 开启 SNMP 实现服务器性能监控
1.检测是否有 SNMP 服务 service snmpd status 2.若没有则安装 yum install -y net-snmp 3.编辑 SNMP 的配置文件,设置安全的验证方式 vi / ...
- [Luogu4986] 逃离
Description 给定次数为 \(n\) 的函数 \(A(x),B(x),C(x)\),求 \(A^2(x)+B^2(x)-C^2(x)\) 在 \([L,R]\) 的零点.\(n\leq 10 ...
- Spring之Bean的配置方式
在博客中为了演示容器Bean实例化时暴露出的几个接口,将UserBean配置在XML中,其实常见的Bean的配置有3种.1.基于xml配置Bean 2.使用注解定义Bean 3.基于java类提供Be ...
- js 计算快速统计中用到的日期
前言 最近在做统计报表模块,其中查询条件用到了快速查询,主要为了方便客户统计查询常用的几个日期纬度,比如本周.上周.本月.上月.昨日. 使用js计算,主要用到了js Date. getDate().g ...