python3 kmp 字符串匹配
先声明,本人菜鸟一个,写博客是为了记录学习的过程,以及自己的理解和心得,可能有的地方写的不好,希望大神指出。。。
抛出问题
给定一个文本串test_str(被匹配的字符串)和模式串pat_str(需要从文本串中匹配的字符串),从文本串test_str中找出模式串pat_str第一次出现的位置,没有的话返回 -1
暴力方式
在说kmp之前,我们先来讲下“暴力方式“,也就是说我们最原始的方法。
text_str = 'asdabcdace'
pat_str = 'abcdace' def str_match(text_str,pat_str):
for i in range(0,len(text_str)):
j = 1
while j < len(pat_str):
if text_str[i:i+j] != pat_str[0:j]: #从text_str第i个字符开始,看匹配是否成功
break #匹配失败,直接跳出循环,i+1,继续从第一个字符匹配
j += 1 #匹配成功就继续匹配下一个字符,知道pat_str每个字符都匹配完
if j == len(pat_str):
return i
return -1 print(str_match(text_str,pat_str))
之所以称之为暴力解法,就是因为每次匹配失败之后就将模式串,向后移动一位,从头开始匹配,一直循环下去。造成时间复杂度高,kmp也就是优化这个地方,每一次匹配失败,下次移动的距离next值
KMP
如果让我完全给你讲懂kmp算法可能不太容易,我只能大致粗略的将下它的一步步实现。我认为就一个重点,
如何求出模式串每个字符对应的next值
因为可能,每一次匹配失败的长度的字符不一样,也就对应每次移动的距离不一样,那我们如何求每个字符对应的next值,这就引出了另一个概念
最大前缀和最大后缀
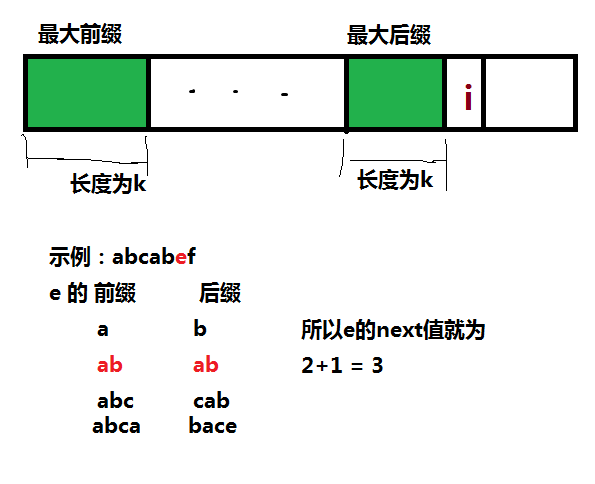
假定最大前缀=最大后缀,长度为k 那么第i位字符,对应的next值就为k+1,一次循环就能求出每个字符的next值
代码实现
#求字符串的next值
text_str = 'asdabcdace'
pat_str = 'abcdace' #得到字符对应的next值
def str_next(s):
#前两个字符默认等于1
next = [1,1]
for x in range(2,len(s)):
next.append(str_max_prx(s,x,next[x-1]-1) + 1)
return next
#参数 s字符串,匹配进行到的位置,下次开始匹配的位置
def str_max_prx(s,x,last_value):
next = 0
for i in range(last_value,x):
if s[0:i] == s[x-i:x]:
next = i
return next
def str_match(s,m):
next = str_next(s)
i=0
s_len = len(s)
m_len = len(m)
while i <= m_len:
flag = True #标志位,用来判断是否匹配成功
index = 1
while index <= s_len:
if m[i:i + index] != s[0:index]:
i = i + next[index]
flag = False
break
else:
index += 1
if flag:
break
if i >= m_len:
i = -1
return i
res = str_match(pat_str,text_str)
print(res)
代码就是这样,很多东西可能还需要自己理解。我记个笔记,为之后方便查找,希望对你能有帮助。
python3 kmp 字符串匹配的更多相关文章
- {Reship}{KMP字符串匹配}
关于KMP字符串匹配的介绍和归纳,作者的思路非常清晰,推荐看一下 http://blog.csdn.net/v_july_v/article/details/7041827
- 洛谷P3375 - 【模板】KMP字符串匹配
原题链接 Description 模板题啦~ Code //[模板]KMP字符串匹配 #include <cstdio> #include <cstring> int cons ...
- Luogu 3375 【模板】KMP字符串匹配(KMP算法)
Luogu 3375 [模板]KMP字符串匹配(KMP算法) Description 如题,给出两个字符串s1和s2,其中s2为s1的子串,求出s2在s1中所有出现的位置. 为了减少骗分的情况,接下来 ...
- 洛谷P3375 [模板]KMP字符串匹配
To 洛谷.3375 KMP字符串匹配 题目描述 如题,给出两个字符串s1和s2,其中s2为s1的子串,求出s2在s1中所有出现的位置. 为了减少骗分的情况,接下来还要输出子串的前缀数组next.如果 ...
- P3375 【模板】KMP字符串匹配
P3375 [模板]KMP字符串匹配 https://www.luogu.org/problemnew/show/P3375 题目描述 如题,给出两个字符串s1和s2,其中s2为s1的子串,求出s2在 ...
- 洛谷—— P3375 【模板】KMP字符串匹配
P3375 [模板]KMP字符串匹配 题目描述 如题,给出两个字符串s1和s2,其中s2为s1的子串,求出s2在s1中所有出现的位置. 为了减少骗分的情况,接下来还要输出子串的前缀数组next. (如 ...
- P3375 模板 KMP字符串匹配
P3375 [模板]KMP字符串匹配 来一道模板题,直接上代码. #include <bits/stdc++.h> using namespace std; typedef long lo ...
- KMP字符串匹配 模板 洛谷 P3375
KMP字符串匹配 模板 洛谷 P3375 题意 如题,给出两个字符串s1和s2,其中s2为s1的子串,求出s2在s1中所有出现的位置. 为了减少骗分的情况,接下来还要输出子串的前缀数组next.(如果 ...
- KMP字符串匹配学习
KMP字符串匹配学习 牛逼啊 SYC大佬的博客
随机推荐
- python if __name__=='__main__'的理解
定义一个模块叫module.py: def main(): print "we are in %s" %__name__ if __name__=='__main__': main ...
- 【未解决】对于使用Windows的IDEA进行编译的文件,但无法在Linux系统中统计代码行数的疑问
在我学习使用Windows的IDEA的过程中,将代码文件转移到Linux虚拟机当中,但无法在Linux系统中统计代码行数. 注意:拷贝进虚拟机的文件均能编译运行. 具体过程如下: root@yogil ...
- 关于vuex和Promise reject 或.catch 的报错处理。
在我们开发过程中,经常会使用vuex来管理接口请求和返回数据. 在vue组件页面使用computed来读取vuex中state的数据. getTaskList({ commit }, payload) ...
- 莫烦tensorflow(7)-mnist
import tensorflow as tffrom tensorflow.examples.tutorials.mnist import input_data#number 1 to 10 dat ...
- 关于surface gradient
[转载请注明出处]http://www.cnblogs.com/mashiqi 2017/06/16 函数定义及前后文详见<Inverse Acoustic and Electromagneti ...
- OpenCV实现彩色图像轮廓 换背景颜色
转摘请注明:https://i.cnblogs.com/EditPosts.aspx?opt=1 有时候我们需要不一样颜色的证件照,下面就用OpenCV来实现证件照的蓝底.红底等换颜色: 代码如下: ...
- postgresql安装与启动(mac os)
转自https://blog.csdn.net/kmust20093211/article/details/44359053 --------数据库的安装与创建----------- 安装 brew ...
- WebSocket是什么原理?为什么可以实现持久连接?
作者:Ovear 链接:https://www.zhihu.com/question/20215561/answer/40316953来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载 ...
- VS2015 使用 Visual Studio Emulator For Android 调试无法命中断点的解决办法?
源解决方案是英文版的,地址:https://dzone.com/articles/fix-for-could-not-connect-to-the-debugger-while-de 问题现象: 1. ...
- 创建一个dynamics 365 CRM online plugin (二) - fields检查
Golden Rules 1. Platform only passes Entity attributes to Plugin that has change of data. 2. If the ...