面试无忧之Zookeeper总结心得
为什么需要分布式系统
l 单机系统已经无法满足业务需要
l 高性能硬件价格昂贵
分布式系统带来哪些问题
l 集群中节点数据一致性问题
l 集群产生分区
l 负载问题
l 幂等性问题
l 可用性问题
l Session问题
分布式PAC设计原则
一个经典的分布式系统理论。CAP理论告诉我们:一个分布式系统不可能同时满足一致性(C:Consistency)、可用性(A:Availability)和分区容错性(P:Partition tolerance)这三个基本需求,最多只能同时满足其中两项。
1、一致性
在分布式环境下,一致性是指数据在多个副本之间能否保持一致的特性。在一致性的需求下,当一个系统在数据一致的状态下执行更新操作后,应该保证系统的数据仍然处于一致的状态。
对于一个将数据副本分布在不同分布式节点上的系统来说,如果对第一个节点的数据进 行了更新操作并且更新成功后,却没有使得第二个节点上的数据得到相应的更新,于是在对第二个节点的数据进行读取操作时,获取的依然是老数据(或称为脏数 据),这就是典型的分布式数据不一致的情况。在分布式系统中,如果能够做到针对一个数据项的更新操作执行成功后,所有的用户都可以读取到其最新的值,那么 这样的系统就被认为具有强一致性
2、可用性
可用性是指系统提供的服务必须一直处于可用的状态,对于用户的每一个操作请求总是能够在有限的时间内返回结果。这里的重点是"有限时间内"和"返回结果"。
"有限时间内"是指,对于用户的一个操作请求,系统必须能够在指定的时间内返回对 应的处理结果,如果超过了这个时间范围,那么系统就被认为是不可用的。另外,"有限的时间内"是指系统设计之初就设计好的运行指标,通常不同系统之间有很 大的不同,无论如何,对于用户请求,系统必须存在一个合理的响应时间,否则用户便会对系统感到失望。
"返回结果"是可用性的另一个非常重要的指标,它要求系统在完成对用户请求的处理后,返回一个正常的响应结果。正常的响应结果通常能够明确地反映出队请求的处理结果,即成功或失败,而不是一个让用户感到困惑的返回结果。
3、分区容错性
分区容错性约束了一个分布式系统具有如下特性:分布式系统在遇到任何网络分区故障的时候,仍然需要能够保证对外提供满足一致性和可用性的服务,除非是整个网络环境都发生了故障。
网络分区是指在分布式系统中,不同的节点分布在不同的子网络(机房或异地网络) 中,由于一些特殊的原因导致这些子网络出现网络不连通的状况,但各个子网络的内部网络是正常的,从而导致整个系统的网络环境被切分成了若干个孤立的区域。 需要注意的是,组成一个分布式系统的每个节点的加入与退出都可以看作是一个特殊的网络分区。
既然一个分布式系统无法同时满足一致性、可用性、分区容错性三个特点,所以我们就需要抛弃一样:
Paxos如何解决分布式一致问题
Paxos的基本思路:
假设有一个社团,其中有团员、议员(决议小组成员)两个角色
团员可以向议员申请提案来修改社团制度
议员坐在一起,拿出自己收到的提案,对每个提案进行投票表决,超过半数通过即可生效
为了秩序,规定每个提案都有编号ID,按顺序自增
每个议员都有一个社团制度笔记本,上面记着所有社团制度,和最近处理的提案编号,初始为0
投票通过的规则:
新提案ID 是否大于 议员本中的ID,是议员举手赞同
如果举手人数大于议员人数的半数,即让新提案生效
例如:
刚开始,每个议员本子上的ID都为0,现在有一个议员拿出一个提案:团费降为100元,这个提案的ID自增为1
每个议员都和自己ID对比,一看 1>0,举手赞同,同时修改自己本中的ID为1
发出提案的议员一看超过半数同意,就宣布:1号提案生效
然后所有议员都修改自己笔记本中的团费为100元
以后任何一个团员咨询任何一个议员:"团费是多少?",议员可以直接打开笔记本查看,并回答:团费为100元
可能会有极端的情况,就是多个议员一起发出了提案,就是并发的情况
例如
刚开始,每个议员本子上的编号都为0,现在有两个议员(A和B)同时发出了提案,那么根据自增规则,这两个提案的编号都为1,但只会有一个被先处理
假设A的提案在B的上面,议员们先处理A提案并通过了,这时,议员们的本子上的ID已经变为了1,接下来处理B的提案,由于它的ID是1,不大于议员本子上的ID,B提案就被拒绝了,B议员需要重新发起提案
上面就是Paxos的基本思路,对照ZooKeeper,对应关系就是:
团员 -client
议员 -server
议员的笔记本 -server中的数据
提案 -变更数据的请求
提案编号 -zxid(ZooKeeper Transaction Id)
提案生效 -执行变更数据的操作
ZooKeeper中还有一个leader的概念,就是把发起提案的权利收紧了,以前是每个议员都可以发起提案,现在有了leader,大家就不要七嘴八舌了,先把提案都交给leader,由leader一个个发起提案
Paxos算法就是通过投票、全局编号机制,使同一时刻只有一个写操作被批准,同时并发的写操作要去争取选票,只有获得过半数选票的写操作才会被批准,所以永远只会有一个写操作得到批准,其他的写操作竞争失败只好再发起一轮投票
zookeeper特性介绍
一致性保证:
更新请求顺序进行,来自同一个client的更新请求按其发送顺序依次执行
数据更新原子性,一次数据更新要么成功,要么失败
全局唯一数据视图,client无论连接到哪个server,数据视图都是一致的
实时性,在一定事件范围内,client能读到最新数据
zookeeper选举流程
1.选举线程由当前Server发起选举的线程担任,其主要功能是对投票结果进行统计,并选出推荐的Server;
2.选举线程首先向所有Server发起一次询问(包括自己);
3.选举线程收到回复后,验证是否是自己发起的询问(验证zxid是否一致),然后获取对方的id(myid),并存储到当前询问对象列表中,最后获取对方提议的leader相关信息(id,zxid),并将这些信息存储到当次选举的投票记录表中;
4.收到所有Server回复以后,就计算出zxid最大的那个Server,并将这个Server相关信息设置成下一次要投票的Server;
5.线程将当前zxid最大的Server设置为当前Server要推荐的Leader,如果此时获胜的Server获得n/2 + 1的Server票数,设置当前推荐的leader为获胜的Server,将根据获胜的Server相关信息设置自己的状态,否则,继续这个过程,直到leader被选举出来
zookeeper读写流程
写流程
客户端连接到集群中某一个节点
客户端发送写请求
服务端连接节点,把该写请求转发给leader
leader处理写请求,一半以上的从节点也写成功,返回给客户端成功。
读流程
客户端连接到集群中某一节点
读请求,直接返回。
zookeeper存储策略
持久化存储是基于内存快照(snapshot)和事务日志(txlog)来存储。
snapshot和txlog的存储目录定义在zoo.cfg中,txlog存储磁盘和snapshot存储磁盘分开,避免io争夺。
txlog的刷盘阈值是1000。txlog是生成snapshot之后生成。
snapshot的保存数量和清理时间间隔配置在zoo.cfg中。
zookeeper 使用concurrenthashmap进行存储。锁的粒度是segment,减少锁竞争,segment里对应一个hashtable 的若干桶.
所以时间复杂度都是 O(1)
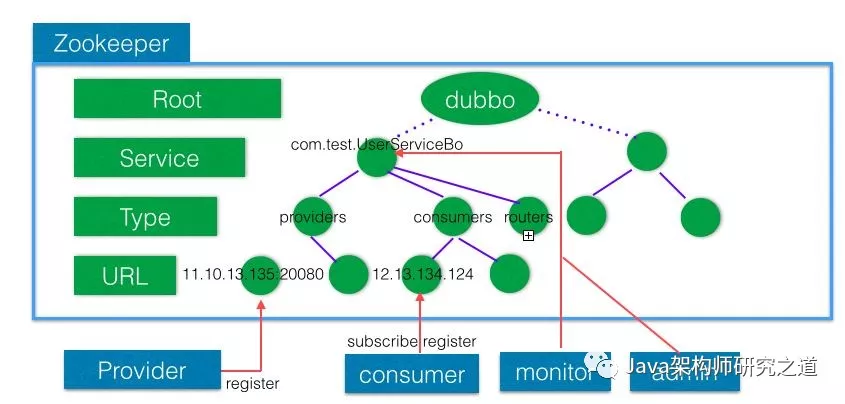
zookeeper应用场景
数据发布与订阅
发布与订阅即所谓的配置管理,顾名思义就是将数据发布到zk节点上,供订阅者动态获取数据,实现配置信息的集中式管理和动态更新。例如全局的配置信息,地址列表等就非常适合使用。
1. 索引信息和集群中机器节点状态存放在zk的一些指定节点,供各个客户端订阅使用。
2. 系统日志(经过处理后的)存储,这些日志通常2-3天后被清除。
3. 应用中用到的一些配置信息集中管理,在应用启动的时候主动来获取一次,并且在节点上注册一个Watcher,以后每次配置有更新,实时通知到应用,获取最新配置信息。
4. 业务逻辑中需要用到的一些全局变量,比如一些消息中间件的消息队列通常有个offset,这个offset存放在zk上,这样集群中每个发送者都能知道当前的发送进度。
5. 系统中有些信息需要动态获取,并且还会存在人工手动去修改这个信息。以前通常是暴露出接口,例如JMX接口,有了zk后,只要将这些信息存放到zk节点上即可。
分布通知/协调
ZooKeeper 中特有watcher注册与异步通知机制,能够很好的实现分布式环境下不同系统之间的通知与协调,实现对数据变更的实时处理。使用方法通常是不同系统都对 ZK上同一个znode进行注册,监听znode的变化(包括znode本身内容及子节点的),其中一个系统update了znode,那么另一个系统能 够收到通知,并作出相应处理。
1. 另一种心跳检测机制:检测系统和被检测系统之间并不直接关联起来,而是通过zk上某个节点关联,大大减少系统耦合。
2. 另一种系统调度模式:某系统有控制台和推送系统两部分组成,控制台的职责是控制推送系统进行相应的推送工作。管理人员在控制台作的一些操作,实际上是修改 了ZK上某些节点的状态,而zk就把这些变化通知给他们注册Watcher的客户端,即推送系统,于是,作出相应的推送任务。
3. 另一种工作汇报模式:一些类似于任务分发系统,子任务启动后,到zk来注册一个临时节点,并且定时将自己的进度进行汇报(将进度写回这个临时节点),这样任务管理者就能够实时知道任务进度。
总之,使用zookeeper来进行分布式通知和协调能够大大降低系统之间的耦合。
分布式锁
分布式锁,这个主要得益于ZooKeeper为我们保证了数据的强一致性,即用户只要完全相信每时每刻,zk集群中任意节点(一个zk server)上的相同znode的数据是一定是相同的。锁服务可以分为两类,一个是保持独占,另一个是控制时序。
保持独占,就是所有试图来获取这个锁的客户端,最终只有一个可以成功获得这把锁。通常的做法是把zk上的一个znode看作是一把锁,通过create znode的方式来实现。所有客户端都去创建 /distribute_lock 节点,最终成功创建的那个客户端也即拥有了这把锁。
控制时序,就是所有视图来获取这个锁的客户端,最终都是会被安排执行,只是有个全局时序了。做法和上面基本类似,只是这里 /distribute_lock 已经预先存在,客户端在它下面创建临时有序节点(这个可以通过节点的属性控制:CreateMode.EPHEMERAL_SEQUENTIAL来指定)。Zk的父节点(/distribute_lock)维持一份sequence,保证子节点创建的时序性,从而也形成了每个客户端的全局时序。
集群管理
1. 集群机器监控:这通常用于那种对集群中机器状态,机器在线率有较高要求的场景,能够快速对集群中机器变化作出响应。这样的场景中,往往有一个监控系统,实时检测集群机器是否存活。过去的做法通常是:监控系统通过某种手段(比如ping)定时检测每个机器,或者每个机器自己定时向监控系统汇报“我还活着”。 这种做法可行,但是存在两个比较明显的问题:1. 集群中机器有变动的时候,牵连修改的东西比较多。2. 有一定的延时。
利用ZooKeeper有两个特性,就可以实时另一种集群机器存活性监控系统:a. 客户端在节点 x 上注册一个Watcher,那么如果 x 的子节点变化了,会通知该客户端。b. 创建EPHEMERAL类型的节点,一旦客户端和服务器的会话结束或过期,那么该节点就会消失。
2. Master选举则是zookeeper中最为经典的使用场景了。
在分布式环境中,相同的业务应用分布在不同的机器上,有些业务逻辑(例如一些耗时的计算,网络I/O处理),往往只需要让整个集群中的某一台机器进行执行, 其余机器可以共享这个结果,这样可以大大减少重复劳动,提高性能,于是这个master选举便是这种场景下的碰到的主要问题。
利用ZooKeeper的强一致性,能够保证在分布式高并发情况下节点创建的全局唯一性,即:同时有多个客户端请求创建 /currentMaster 节点,最终一定只有一个客户端请求能够创建成功。
zookeeper虚拟机安装
略
面试无忧之Zookeeper总结心得的更多相关文章
- 面试官:Zookeeper是什么,它有什么特性与使用场景?
哈喽!大家好,我是小奇,一位不靠谱的程序员 小奇打算以轻松幽默的对话方式来分享一些技术,如果你觉得通过小奇的文章学到了东西,那就给小奇一个赞吧 文章持续更新 一.前言 作为一名Java程序员,Zook ...
- 企业面试之LeetCode刷题心得
谈起刷LeetCode的心得,想要先扯点别的,说实话我是比较自虐的人,大学时候本专业从来不好好上,一直觊觎着别人的专业,因为自己文科生,总觉得没有项技术在身出门找工作都没有底气,然后看什么炫学什么,简 ...
- 一位资深程序员面试Python工程师的岗位心得和历程【新手必须】
前言本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理.作者:程序员阿牛说一些面试的心得体会: 1.简历制作我做了两份简历,用两个手机 ...
- 面试官:Zookeeper集群怎么搭建?
哈喽!大家好,我是小奇,一位不靠谱的程序员 小奇打算以轻松幽默的对话方式来分享一些技术,如果你觉得通过小奇的文章学到了东西,那就给小奇一个赞吧 文章持续更新 一.前言 作为一名Java拧螺丝选手,不必 ...
- 面试官:Zookeeper怎么解决读写、双写并发不一致问题,以及共享锁的实现原理?
哈喽!大家好,我是小奇,一位不靠谱的程序员 小奇打算以轻松幽默的对话方式来分享一些技术,如果你觉得通过小奇的文章学到了东西,那就给小奇一个赞吧 文章持续更新 一.前言 今天清明假期,赶上北京玉渊潭公园 ...
- 手撕面试官系列(九):分布式限流面试专题 Nginx+zookeeper
Nginx专题 (面试题+答案领取方式见侧边栏) 1.请解释一下什么是 Nginx?2.请列举 Nginx 的一些特性.3.请列举 Nginx 和 Apache 之间的不同点4.请解释 Nginx 如 ...
- Zookeeper面试专题
Zookeeper面试专题 1. Zookeeper是什么框架 分布式的.开源的分布式应用程序协调服务,原本是Hadoop.HBase的一个重要组件.它为分布式应用提供一致性服务的软件,包括:配置维护 ...
- 一文看懂 ZooKeeper ,面试再也不用背八股(文末送PDF)
ZooKeeper知识点总结 一.ZooKeeper 的工作机制 二.ZooKeeper 中的 ZAB 协议 三.数据模型与监听器 四.ZooKeeper 的选举机制和流程 本文将以如下内容为主线讲解 ...
- 阿里Java架构师面试高频300题:集合+JVM+Redis+并发+算法+框架等
前言 在过2个月即将进入9月了,然而面对今年的大环境而言,跳槽成功的难度比往年高了很多,很明显的感受就是:对于今年的java开发朋友跳槽面试,无论一面还是二面,都开始考验一个Java程序员的技术功底和 ...
随机推荐
- 98.TCP通信传输文件
客户端 #define _CRT_SECURE_NO_WARNINGS #include<stdio.h> #include <stdlib.h> #include <s ...
- 1.1 Introduction中 Distribution官网剖析(博主推荐)
不多说,直接上干货! 一切来源于官网 http://kafka.apache.org/documentation/ Distribution 分布式(Distribution) The partiti ...
- 解决Win8/8.1无法正确识别USB3.0的问题
找一个USB3.0的移动硬盘到了手里竟然变成2.0的了!二了! 不能忍啊. 听说是快速启动的问题,但是开机速度快很诱人. 百度了其他解决方法,终于解决了. 下面摘录自: http://blog.csd ...
- .v 和 .sdf
DC输出的.v(网表?)和.sdf(储存的是延时的信息) 用于后仿真
- JSP语法基础(一)
一.JSP页面中的凝视 (1)HTML凝视 <!-- comment [ <%=expression %> ] --> 能在client显示的一种凝视,标记内的全部JSP脚本元 ...
- CSS笔记 - fgm练习 2-9 - 播放列表收缩展开
练习地址: http://www.fgm.cc/learn/lesson2/09.html <style> *{ margin: 0;padding: 0;font-size: 12px; ...
- Webpack学习手册
多端阅读<Webpack官方文档>: 在PC/MAC上查看:下载w3cschool客户端,进入客户端后通过搜索当前教程手册的名称并下载,就可以查看当前离线教程文档.下载Webpack官方文 ...
- 步步为营(十五)搜索(一)DFS 深度优先搜索
前方大坑预警! 先讲讲什么是搜索吧. 有一天你去一个果园摘梨子,果农告诉你.有一棵树上有一个金子做的梨子,找到就是你的,你该怎么找? 地图例如以下: S 0 0 0 0 0 0 0 0 0 0 0 0 ...
- 9.10 Binder系统_Java实现_hello服务
怎么做?2.1 定义接口: 写IHelloService.aidl文件, 上传, 编译, 得到IHelloService.java 里面有Stub : onTransact, 它会分辨收到数据然后调用 ...
- 中间件、服务器和Web服务器三者的区别
相信很多的Web安全初学者和我一样,对中间件和服务器的认识不够深刻,对两者的概念可能会有所混淆. 正好今天在学习的时候突然想到了这个问题,粗略百度了一下,似乎网上对这个问题的解释不多,那么就由我来为大 ...