CS229 7.2 应用机器学习方法的技巧,准确率,召回率与 F值
建立模型
当使用机器学习的方法来解决问题时,比如垃圾邮件分类等,一般的步骤是这样的:
1)从一个简单的算法入手这样可以很快的实现这个算法,并且可以在交叉验证集上进行测试;
2)画学习曲线以决定是否更多的数据,更多的特征或者其他方式会有所帮助;
3)人工检查那些算法预测错误的例子(在交叉验证集上),看看能否找到一些产生错误的原因。
评估模型
首先,引入一个概念,非对称性分类。考虑癌症预测问题,y=1 代表癌症,y=0 代表没有癌症,对于一个数据集,我们建立logistic 回归模型,经过以上建模的步骤,得到一个优化的模型,错误率仅为1%,这貌似是一个很好的结果,但考虑数据集若仅有0.05%的正例(y=1),那么我们直接预测所有y=0,我们得到的模型的错误率仅为0.5%,这便是非对称分类的问题,这样的问题仅考虑错误率是有风险的。
下面引入一种标准的衡量方法:Precision/Recall(精确度和召回率),这种度量最早出现在信息检索问题中的,如下:
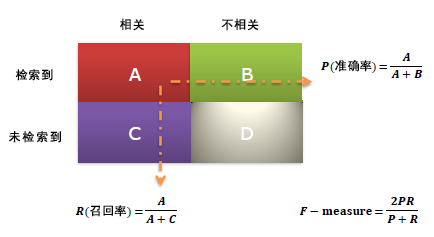
在机器学习的模型中,也可以用这种评估方法,具体如下:

其中:
True Positive (真正例, TP)被模型预测为正的正样本;可以称作判断为真的正确率
True Negative(真负例 , TN)被模型预测为负的负样本 ;可以称作判断为假的正确率
False Positive (假正例, FP)被模型预测为正的负样本;可以称作误报率
False Negative(假负例 , FN)被模型预测为负的正样本;可以称作漏报率
现在需要考虑权衡Precision/Recall:
以logistic 回归为例:
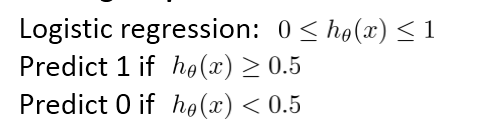
假设我们非常有把握时才预测病人得癌症(y=1), 这个时候,我们常常将阈值设置的很高,FP变小,FN增大,这会导致高精确度,低召回率(Higher precision, lower recall);
假设我们不希望将太多的癌症例子错分(避免假负例,本身得了癌症,确被分类为没有得癌症), 这个时候,阈值就可以设置的低一些,FP变大,FN变小,这又会导致高召回率,低精确度(Higher recall, lower precision);

以上的描述可以用如下的PR曲线来描述,一般准确率提高,召回率会下降:
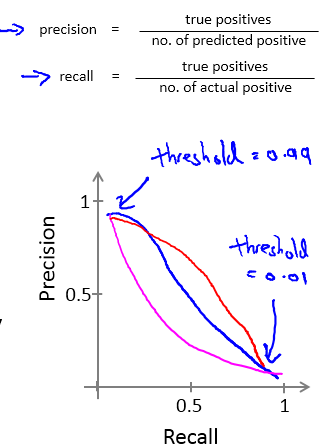
关于如何权衡准确率与召回率:
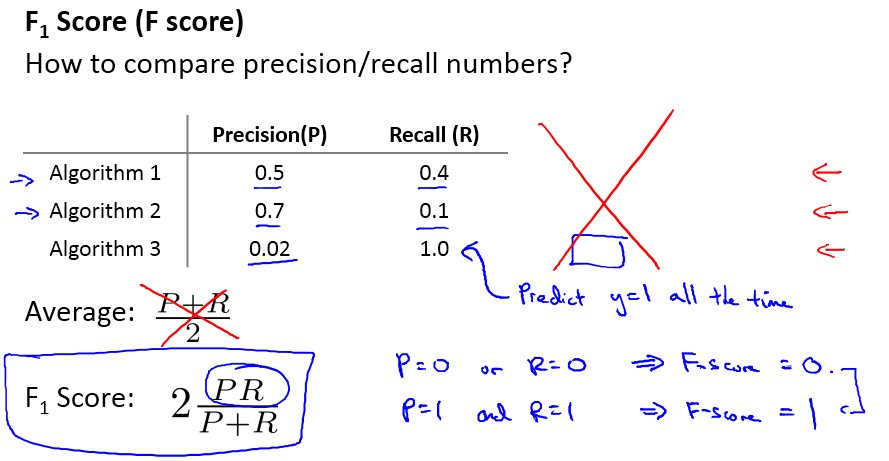
如果是做搜索,那就是保证召回的情况下提升准确率;如果做疾病监测、反垃圾,则是保准确率的条件下,提升召回。在两者都要求高的情况下,可以用F1来衡量。
CS229 7.2 应用机器学习方法的技巧,准确率,召回率与 F值的更多相关文章
- (七)7.2 应用机器学习方法的技巧,准确率,召回率与 F值
建立模型 当使用机器学习的方法来解决问题时,比如垃圾邮件分类等,一般的步骤是这样的: 1)从一个简单的算法入手这样可以很快的实现这个算法,并且可以在交叉验证集上进行测试: 2)画学习曲线以决定是否更多 ...
- 机器学习方法(七):Kmeans聚类K值如何选,以及数据重抽样方法Bootstrapping
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术感兴趣的同学加入.我的博客写一些自己用得到东西,并分享给 ...
- Stanford机器学习---第六讲. 怎样选择机器学习方法、系统
原文:http://blog.csdn.net/abcjennifer/article/details/7797502 本栏目(Machine learning)包括单参数的线性回归.多参数的线性回归 ...
- 美团网基于机器学习方法的POI品类推荐算法
美团网基于机器学习方法的POI品类推荐算法 前言 在美团商家数据中心(MDC),有超过100w的已校准审核的POI数据(我们一般将商家标示为POI,POI基础信息包括:门店名称.品类.电话.地址.坐标 ...
- 关于”机器学习方法“,"深度学习方法"系列
"机器学习/深度学习方法"系列,我本着开放与共享(open and share)的精神撰写,目的是让很多其它的人了解机器学习的概念,理解其原理,学会应用.如今网上各种技术类文章非常 ...
- R语言进行机器学习方法及实例(一)
版权声明:本文为博主原创文章,转载请注明出处 机器学习的研究领域是发明计算机算法,把数据转变为智能行为.机器学习和数据挖掘的区别可能是机器学习侧重于执行一个已知的任务,而数据发掘是在大数据中寻找有 ...
- 机器学习方法、距离度量、K_Means
特征向量 1.特征向量:以人为例,每个元素可能就对应这人的某些方面,这就是特征,例如:身高.年龄.性别.国际....2.特征工程:目的就是将现有数据中可作为信号的特征与那些仅是噪声的特征区分开来:当数 ...
- 不平衡数据下的机器学习方法简介 imbalanced time series classification
imbalanced time series classification http://www.vipzhuanli.com/pat/books/201510229367.5/2.html?page ...
- 基于CRF工具的机器学习方法命名实体识别的过
[转自百度文库] 基于CRF工具的机器学习方法命名实体识别的过程 | 浏览:226 | 更新:2014-04-11 09:32 这里只讲基本过程,不涉及具体实现,我也是初学者,想给其他初学者一些帮助, ...
随机推荐
- Windows2008R2系统运行时间超过497天的bug
早上接到客户电话,说一台测试服务器tomcat服务无法访问,登录服务器查看tomcat连接数据库故障. 使用plsql develop工具登录,提示 ora-12560 TNS:protocol ad ...
- VS2010生成安装包制作步骤 (转)
阅读目录 VS2010生成安装包制作步骤 回到目录 VS2010生成安装包制作步骤 在VS2010中文旗舰版本中生成winForm安装包,可以复制你电脑中的开发环境,避免你忘记了一下配置然后在别的 ...
- 洛谷 2234 [HNOI2002]营业额统计——treap(入门)
题目:https://www.luogu.org/problemnew/show/P2234 学习了一下 treap 的写法. 学习材料:https://blog.csdn.net/litble/ar ...
- apache的MultipartEntityBuilder文件上传
本文讲解多文件上传方法,不比较上传有几种方法和效率,而是定向分析apache的httpmime包的MultipartEntityBuilder类,源码包:httpmime-4.5.2.jar 一.常用 ...
- Typescript学习总结之泛型
泛型: 参数化的类型,一般用来限制结合的内容 class Student { constructor(public name: string) { } say() { console.log(this ...
- 自然语言处理工具python调用hanlp中文实体识别
Hanlp作为一款重要的中文分词工具,在GitHub的用户量已经非常之高,应该可以看得出来大家对于hanlp这款分词工具还是很认可的.本篇继续分享一篇关于hanlp的使用实例即Python调用hanl ...
- SPI初识
SPI初识 1.信息来源 2.需要了解的是SPI(x1,x2,x4)
- PHP优化思路
想起来记录一下自己对PHP的优化思路 针对Nginx和 PHP-FPM进行优化 首先应该分为代码层面.配置层面.架构层面 代码层面 参见了https://segmentfault.com/a/1190 ...
- mac系统 Xcode打包ionic项目(iOS)
一.环境搭建 1. 安装Node.js,使用node -v 查询版本号: 2. 安装ionic: $ sudo npm install -g cordova(可以指定版本,如cordova@7.0.1 ...
- msp430及stm32中基本的C编程知识
为什么我使用P1OUT ^= 0x01;和P1OUT = 0x01 ^是异或计算符号 所以 每次运算都是反转的.而不不加这个运算符就是一直保持1的状态. p1out|=bit6的意思p1out的值如果 ...