物体检测之FPN及Mask R-CNN
对比目前科研届普遍喜欢把问题搞复杂,通过复杂的算法尽量把审稿人搞蒙从而提高论文的接受率的思想,无论是著名的残差网络还是这篇Mask R-CNN,大神的论文尽量遵循著名的奥卡姆剃刀原理:即在所有能解决问题的算法中,选择最简单的那个。霍金在出版《时间简史》中说“书里每多一个数学公式,你的书将会少一半读者”。Mask R-CNN更是过分到一个数学公式都没有,而是通过对问题的透彻的分析,提出针对性非常强的解决方案,下面我们来一睹Mask R-CNN的真容。
动机
语义分割和物体检测是计算机视觉领域非常经典的两个重要应用。在语义分割领域,FCN[2]是代表性的算法;在物体检测领域,代表性的算法是Faster R-CNN[3]。很自然的会想到,结合FCN和Faster R-CNN不仅可以是模型同时具有物体检测和语义分割两个功能,还可以是两个功能互相辅助,共同提高模型精度,这便是Mask R-CNN的提出动机。Mask R-CNN的结构如图1
 图1:Mask R-CNN框架图
图1:Mask R-CNN框架图
如图1所示,Mask R-CNN分成两步:
- 使用RPN网络产生候选区域;
- 分类,bounding box,掩码预测的多任务损失。
在Fast R-CNN的解析文章中,我们介绍Fast R-CNN采用ROI池化来处理候选区域尺寸不同的问题。但是对于语义分割任务来说,一个非常重要的要求便是特征层和输入层像素的一对一,ROI池化显然不满足该要求。为了改进这个问题,作者仿照STN [4]中提出的双线性插值提出了ROIAlign,从而使Faster R-CNN的特征层也能进行语义分割。
下面我们结合代码详细解析Mask R-CNN,代码我使用的是基于TensorFlow和Keras实现的版本:https://github.com/matterport/Mask_RCNN。
Mask R-CNN详解
1. 骨干架构(FPN)
在第一章中,我们介绍过卷积网络的一个重要特征:深层网络容易响应语义特征,浅层网络容易响应图像特征。但是到了物体检测领域,这个特征便成了一个重要的问题,高层网络虽然能响应语义特征,但是由于Feature Map的尺寸较小,含有的几何信息并不多,不利于物体检测;浅层网络虽然包含比较多的几何信息,但是图像的语义特征并不多,不利于图像的分类,这个问题在小尺寸物体检测上更为显著和,这也就是为什么物体检测算法普遍对小物体检测效果不好的最重要原因之一。很自然地可以想到,使用合并了的深层和浅层特征来同时满足分类和检测的需求。
Mask R-CNN的骨干框架使用的是该团队在CVPR2017的另外一篇文章FPN[5]。FPN使用的是图像金字塔的思想以解决物体检测场景中小尺寸物体检测困难的问题,传统的图像金字塔方法(图2.a)采用输入多尺度图像的方式构建多尺度的特征,该方法的最大问题便是识别时间为单幅图的k倍,其中k是缩放的尺寸个数。Faster R-CNN等方法为了提升检测速度,使用了单尺度的Feature Map(图2.b),但单尺度的特征图限制了模型的检测能力,尤其是训练集中覆盖率极低的样本(例如较大和较小样本)。不同于Faster R-CNN只使用最顶层的Feature Map,SSD[6]利用卷积网络的层次结构,从VGG的第conv4_3开始,通过网络的不同层得到了多尺度的Feature Map(图2.c),该方法虽然能提高精度且基本上没有增加测试时间,但没有使用更加低层的Feature Map,然而这些低层次的特征对于检测小物体是非常有帮助的。
针对上面这些问题,FPN采用了SSD的金字塔内Feature Map的形式。与SSD不同的是,FPN不仅使用了VGG中层次深的Feature Map,并且浅层的Feature Map也被应用到FPN中。并通过自底向上(bottom-up),自顶向下(top-down)以及横向连接(lateral connection)将这些Feature Map高效的整合起来,在提升精度的同时并没有大幅增加检测时间(图2.d)。
通过将Faster R-CNN的RPN和Fast R-CNN的骨干框架换成FPN,Faster R-CNN的平均精度从51.7%提升到56.9%。
 图2:金字塔特征的几种形式。
图2:金字塔特征的几种形式。
FPN的代码出现在./mrcnn/model.py中,核心代码如下:
# Build the shared convolutional layers.
# Bottom-up Layers
# Returns a list of the last layers of each stage, 5 in total.
# Don't create the thead (stage 5), so we pick the 4th item in the list.
if callable(config.BACKBONE):
_, C2, C3, C4, C5 = config.BACKBONE(input_image, stage5=True, train_bn=config.TRAIN_BN)
else:
_, C2, C3, C4, C5 = resnet_graph(input_image, config.BACKBONE, stage5=True, train_bn=config.TRAIN_BN)
# Top-down Layers
# TODO: add assert to varify feature map sizes match what's in config
P5 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c5p5')(C5)
P4 = KL.Add(name="fpn_p4add")([
KL.UpSampling2D(size=(2, 2), name="fpn_p5upsampled")(P5),
KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c4p4')(C4)])
P3 = KL.Add(name="fpn_p3add")([
KL.UpSampling2D(size=(2, 2), name="fpn_p4upsampled")(P4),
KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c3p3')(C3)])
P2 = KL.Add(name="fpn_p2add")([
KL.UpSampling2D(size=(2, 2), name="fpn_p3upsampled")(P3),
KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c2p2')(C2)])
# Attach 3x3 conv to all P layers to get the final feature maps.
P2 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p2")(P2)
P3 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p3")(P3)
P4 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p4")(P4)
P5 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p5")(P5)
# P6 is used for the 5th anchor scale in RPN. Generated by
# subsampling from P5 with stride of 2.
P6 = KL.MaxPooling2D(pool_size=(1, 1), strides=2, name="fpn_p6")(P5)
# Note that P6 is used in RPN, but not in the classifier heads.
rpn_feature_maps = [P2, P3, P4, P5, P6]
mrcnn_feature_maps = [P2, P3, P4, P5]1.1 自底向上路径
自底向上方法反映在上面代码的第6行或者第8行,自底向上即是卷积网络的前向过程,在Mask R-CNN中,用户可以根据配置文件选择使用ResNet-50或者ResNet-101。代码中的resnet_graph就是一个残差块网络,其返回值C2,C3,C4,C5,是每次池化之后得到的Feature Map,该函数也实现在./mrcnn/model.py中(代码片段2)。需要注意的是在残差网络中,C2,C3,C4,C5经过的降采样次数分别是2,3,4,5即分别对应原图中的步长分别是4,8,16,32。
def resnet_graph(input_image, architecture, stage5=False, train_bn=True):
"""Build a ResNet graph.
architecture: Can be resnet50 or resnet101
stage5: Boolean. If False, stage5 of the network is not created
train_bn: Boolean. Train or freeze Batch Norm layres
"""
assert architecture in ["resnet50", "resnet101"]
# Stage 1
x = KL.ZeroPadding2D((3, 3))(input_image)
x = KL.Conv2D(64, (7, 7), strides=(2, 2), name='conv1', use_bias=True)(x)
x = BatchNorm(name='bn_conv1')(x, training=train_bn)
x = KL.Activation('relu')(x)
C1 = x = KL.MaxPooling2D((3, 3), strides=(2, 2), padding="same")(x)
# Stage 2
x = conv_block(x, 3, [64, 64, 256], stage=2, block='a', strides=(1, 1), train_bn=train_bn)
x = identity_block(x, 3, [64, 64, 256], stage=2, block='b', train_bn=train_bn)
C2 = x = identity_block(x, 3, [64, 64, 256], stage=2, block='c', train_bn=train_bn)
# Stage 3
x = conv_block(x, 3, [128, 128, 512], stage=3, block='a', train_bn=train_bn)
x = identity_block(x, 3, [128, 128, 512], stage=3, block='b', train_bn=train_bn)
x = identity_block(x, 3, [128, 128, 512], stage=3, block='c', train_bn=train_bn)
C3 = x = identity_block(x, 3, [128, 128, 512], stage=3, block='d', train_bn=train_bn)
# Stage 4
x = conv_block(x, 3, [256, 256, 1024], stage=4, block='a', train_bn=train_bn)
block_count = {"resnet50": 5, "resnet101": 22}[architecture]
for i in range(block_count):
x = identity_block(x, 3, [256, 256, 1024], stage=4, block=chr(98 + i), train_bn=train_bn)
C4 = x
# Stage 5
if stage5:
x = conv_block(x, 3, [512, 512, 2048], stage=5, block='a', train_bn=train_bn)
x = identity_block(x, 3, [512, 512, 2048], stage=5, block='b', train_bn=train_bn)
C5 = x = identity_block(x, 3, [512, 512, 2048], stage=5, block='c', train_bn=train_bn)
else:
C5 = None
return [C1, C2, C3, C4, C5]这里之所以没有使用C1,是考虑到由于C1的尺寸过大,训练过程中会消耗很多的显存。
1.2 自顶向下路径和横向连接
通过自底向上路径,FPN得到了四组Feature Map。浅层的Feature Map如C2含有更多的纹理信息,而深层的Feature Map如C5含有更多的语义信息。为了将这四组倾向不同特征的Feature Map组合起来,FPN使用了自顶向下及横向连接的策略,图3。
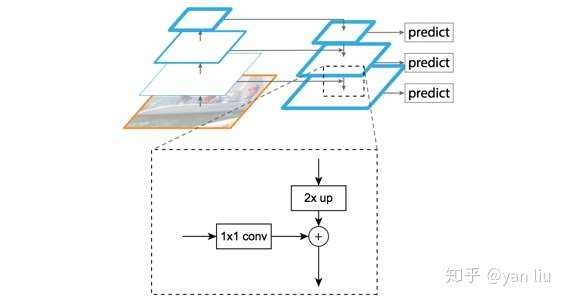 图3:FPN的自顶向上路径和横向连接
图3:FPN的自顶向上路径和横向连接
残差网络得到的C1-C5由于经历了不同的降采样次数,所以得到的Feature Map的尺寸也不同。为了提升计算效率,首先FPN使用 进行了降维,得到P5,然后使用双线性插值进行上采样,将P5上采样到和C4相同的尺寸。
之后,FPN也使用 卷积对P4进行了降维,由于降维并不改变尺寸大小,所以P5和P4具有相同的尺寸,FPN直接把P5单位加到P4得到了更新后的P4。基于同样的策略,我们使用P4更新P3,P3更新P2。这整个过程是从网络的顶层向下层开始更新的,所以叫做自顶向下路径。
FPN使用单位加的操作来更新特征,这种单位加操作叫做横向连接。由于使用了单位加,所以P2,P3,P4,P5应该具有相同数量的Feature Map(源码中该值为256),所以FPN使用了 卷积进行降维。
在更新完Feature Map之后,FPN在P2,P3,P4,P5之后均接了一个 卷积操作(代码片段1第22-25行),该卷积操作是为了减轻上采样的混叠效应(aliasing effect)。
2. 两步走策略
Mask R-CNN采用了和Faster R-CNN相同的两步走策略,即先使用RPN提取候选区域,关于RPN的详细介绍,可以参考Faster R-CNN一文。不同于Faster R-CNN中使用分类和回归的多任务回归,Mask R-CNN在其基础上并行添加了一个用于语义分割的Mask损失函数,所以Mask R-CNN的损失函数可以表示为下式。
上式中, 表示bounding box的分类损失值,
表示bounding box的回归损失值,
表示mask部分的损失值,图4。在这份源码中,作者使用了近似联合训练(Approximate Joint Training),所以损失函数会由也会加上RPN的分类和回归loss。这一部分代码在
./mrcnn/model.py的2004-2025行。 和
的计算方式与Faster R-CNN相同,下面我们重点讨论
。
 图4:Mask R-CNN的损失函数
图4:Mask R-CNN的损失函数
在进行掩码预测时,FCN的分割和预测是同时进行的,即要预测每个像素属于哪一类。而Mask R-CNN将分类和语义分割任务进行了解耦,即每个类单独的预测一个位置掩码,这种解耦提升了语义分割的效果,从图5上来看,提升效果还是很明显的。
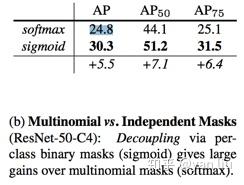 图5:Mask R-CNN解耦分类和分割的精度提升
图5:Mask R-CNN解耦分类和分割的精度提升
所以Mask R-CNN基于FCN将ROI区域映射成为一个 (FCN是
)的特征层,例如他图4中的
。由于每个候选区域的分割是一个二分类任务,所以
使用的是二值交叉熵(
binary_crossentropy)损失函数,对应的代码为(1182-1184行)
loss = K.switch(tf.size(y_true) > 0,
K.binary_crossentropy(target=y_true, output=y_pred),
tf.constant(0.0))顾名思义,二值交叉熵即用于二分类的交叉熵损失函数,该损失一般配合 激活函数使用(第1006行)。
3. RoIAlign
ROIAlign的提出是为了解决Faster R-CNN中RoI Pooling的区域不匹配的问题,下面我们来举例说明什么是区域不匹配。ROI Pooling的区域不匹配问题是由于ROI Pooling过程中的取整操作产生的(图6),我们知道ROI Pooling是Faster R-CNN中必不可少的一步,因为其会产生长度固定的特征向量,有了长度固定的特征向量才能进行softmax计算分类损失。
如下图,输入是一张 的图片,经过一个有5次降采样的卷机网络,得到大小为
的Feature Map。图中的ROI区域大小是
,经过网络之后对应的区域为
,由于无法整除,ROI Pooling采用向下取整的方式,进而得到ROI区域的Feature Map的大小为
,这就造成了第一次区域不匹配。
RoI Pooling的下一步是对Feature Map分bin,加入我们需要一个 的bin,每个bin的大小为
,由于不能整除,ROI同样采用了向下取整的方式,从而每个bin的大小为
,即整个RoI区域的Feature Map的尺寸为
。第二次区域不匹配问题因此产生。
对比ROI Pooling之前的Feature Map,ROI Pooling分别在横向和纵向产生了4.75和1.625的误差,对于物体分类或者物体检测场景来说,这几个像素的位移或许对结果影响不大,但是语义分割任务通常要精确到每个像素点,因此ROI Pooling是不能应用到Mask R-CNN中的。
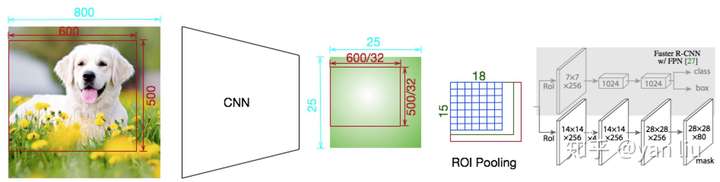 图6:ROI Pooling的区域不匹配问题
图6:ROI Pooling的区域不匹配问题
为了解决这个问题,作者提出了RoIAlign。RoIAlign并没有取整的过程,可以全程使用浮点数操作,步骤如下:
- 计算RoI区域的边长,边长不取整;
- 将ROI区域均匀分成
个bin,每个bin的大小不取整;
- 每个bin的值为其最邻近的Feature Map的四个值通过双线性插值得到;
- 使用Max Pooling或者Average Pooling得到长度固定的特征向量。
RoIAlign操作通过tf.image.crop_and_resize一个函数便可以实现,在./mrcnn/model.py的第421-423行。由于Mask R-CNN使用了FPN作为骨干架构,所以使用了循环保存每次Pooling之后的Feature Map。
tf.image.crop_and_resize(feature_maps[i], level_boxes, box_indices, self.pool_shape, method="bilinear")总结
Mask R-CNN是一个很多state-of-the-art算法的合成体,并非常巧妙的设计了这些模块的合成接口:
- 使用残差网络作为卷积结构;
- 使用FPN作为骨干架构;
- 使用Faster R-CNN的物体检测流程:RPN+Fast R-CNN;
- 增加FCN用于语义分割。
Mask R-CNN设计的主要接口有:
- 将FCN和Faster R-CNN合并,通过构建一个三任务的损失函数来优化模型;
- 使用RoIAlign优化了RoI Pooling,解决了Faster R-CNN在语义分割中的区域不匹配问题。
Reference
[1] He K, Gkioxari G, Dollár P, et al. Mask r-cnn[C]//Computer Vision (ICCV), 2017 IEEE International Conference on. IEEE, 2017: 2980-2988.
[2] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR, 2015. 1, 3, 6
[3] S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. In NIPS, 2015. 1, 2, 3, 4, 7
[4] M. Jaderberg, K. Simonyan, A. Zisserman, and K. Kavukcuoglu. Spatial transformer networks. In NIPS, 2015. 4
[5] T.-Y. Lin, P. Dollar, R. Girshick, K. He, B. Hariharan, and ´ S. Belongie. Feature pyramid networks for object detection. In CVPR, 2017. 2, 4, 5, 7
[6] Liu W, Anguelov D, Erhan D, et al. Ssd: Single shot multibox detector[C]//European conference on computer vision. Springer, Cham, 2016: 21-37.
附录A: 双线性插值
双线性插值即在二维空间上按维度分别进行线性插值。
线性插值:已知在直线上两点 ,
,则在
区间内任意一点
满足等式
即已知 的情况下,
的计算方式为:
双线性插值:双线性插值即在二维空间的每个维度分别进行线性插值,如图8
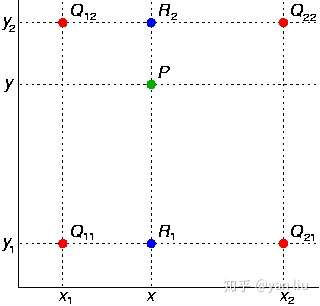 图8:双线性插值
图8:双线性插值
已知二维空间中4点 ,
,
,
,我们要求的是空间中一点中
的值
。
首先在 轴上进行线性插值据得到
和
:
在根据 和
在
轴上进行线性插值
物体检测之FPN及Mask R-CNN的更多相关文章
- 多目标检测分类 RCNN到Mask R-CNN
最近做目标检测需要用到Mask R-CNN,之前研究过CNN,R-CNN:通过论文的阅读以及下边三篇博客大概弄懂了Mask R-CNN神经网络.想要改进还得努力啊... 目标检测的经典网络结构,顺序大 ...
- Detectron系统实现了最先进的物体检测算法https://github.com/facebookresearch/Detectron
,包括Mask R-CNN. 它是用Python编写的,支持Caffe2深度学习框架. 不久前,FAIR才开源了语音识别的工具wav2letter,戳这里看大数据文摘介绍<快讯 | Facebo ...
- 物体检测丨Faster R-CNN详解
这篇文章把Faster R-CNN的原理和实现阐述得非常清楚,于是我在读的时候顺便把他翻译成了中文,如果有错误的地方请大家指出. 原文:http://www.telesens.co/2018/03/1 ...
- cs231n---语义分割 物体定位 物体检测 物体分割
1 语义分割 语义分割是对图像中每个像素作分类,不区分物体,只关心像素.如下: (1)完全的卷积网络架构 处理语义分割问题可以使用下面的模型: 其中我们经过多个卷积层处理,最终输出体的维度是C*H*W ...
- 利用modelarts和物体检测方式识别验证码
近来有朋友让老山帮忙识别验证码.在github上查看了下,目前开源社区中主要流行以下几种验证码识别方式: tesseract-ocr模块: 这是HP实验室开发由Google 维护的开源 OCR引擎,内 ...
- 快速上手百度大脑EasyDL专业版·物体检测模型(附代码)
作者:才能我浪费991. 简介:1.1. 什么是EasyDL专业版EasyDL专业版是EasyDL在2019年10月下旬全新推出的针对AI初学者或者AI专业工程师的企业用户及开发者推出的A ...
- 『计算机视觉』物体检测之RefineDet系列
Two Stage 的精度优势 二阶段的分类:二步法的第一步在分类时,正负样本是极不平衡的,导致分类器训练比较困难,这也是一步法效果不如二步法的原因之一,也是focal loss的motivation ...
- 转-------基于R-CNN的物体检测
基于R-CNN的物体检测 原文地址:http://blog.csdn.net/hjimce/article/details/50187029 作者:hjimce 一.相关理论 本篇博文主要讲解2014 ...
- 深度学习笔记之基于R-CNN的物体检测
不多说,直接上干货! 基于R-CNN的物体检测 原文地址:http://blog.csdn.net/hjimce/article/details/50187029 作者:hjimce 一.相关理论 本 ...
随机推荐
- chrome浏览器好用的插件
1.Chrome批量保存所有选项卡网址 + 批量打开复制网址小插件 批量保存所有选项卡网址插件:Copy All Urls 经常搜索一些东西,下班时无法处理完所有网页内容,比如做笔记什么的,又不舍得关 ...
- [转]xargs详解
为什么要用xargs,问题的来源 在工作中经常会接触到xargs命令,特别是在别人写的脚本里面也经常会遇到,但是却很容易与管道搞混淆,本篇会详细讲解到底什么是xargs命令,为什么要用xargs命令以 ...
- Mongo导出mongoexport和导入mongoimport介绍
最近爬取mobike和ofo单车数据,需要存储在csv文件中,因为设计的程序没有写存储csv文件的方法,为了偷懒所以就继续存储到了MongoDB中.恰好MongoDB支持导出的数据可以是csv文件和j ...
- 洛谷 2234 [HNOI2002]营业额统计——treap(入门)
题目:https://www.luogu.org/problemnew/show/P2234 学习了一下 treap 的写法. 学习材料:https://blog.csdn.net/litble/ar ...
- JAVAFX开发桌面应用
javafx中文版文档: http://www.yiibai.com/javafx/ JavaFX之FXController详解 JavaFx系列教程 含打包部署 javafx之两种局部界面的呈现方式 ...
- jQuery实现商品详情 详细参数页面切换
利用index实现: <!DOCTYPE html> <html lang="en"> <head> <meta charset=&quo ...
- 黄聪:JQUERY的datatables插件,Date range filter时间段筛选功能
需配合moment插件实现:http://momentjs.com/ 演示:http://live.datatables.net/zuciyawi/1/edit HTML代码 <!DOCTYPE ...
- [蓝桥杯]ALGO-86.算法训练_矩阵乘法
问题描述 输入两个矩阵,分别是m*s,s*n大小.输出两个矩阵相乘的结果. 输入格式 第一行,空格隔开的三个正整数m,s,n(均不超过200). 接下来m行,每行s个空格隔开的整数,表示矩阵A(i,j ...
- Ubuntu 14.10 下编译Hadoop2.4.0
在http://www.aboutyun.com/thread-8130-1-1.html 这里看到到,安装过程遇到了上面说的问题,所以将此文转载过来,以备不时之需,感谢此作者. 问题导读: 1.如果 ...
- vc++post方式登录网站
以http://www.idc3389.com为例: 效果图: 使用Fiddler工具进行抓包,截图: 可以发现: 1.并没有使用cookie并没有用作用户身份识别,因为登录前后的cookie并没有发 ...