BP神经网络测试MNIST记录
约定:
所有的初始化权值范围,如下,就是说更换激活函数的情况,没有过大的调整初始权重。
if(randomMode==1):
numpy.random.seed(seedWih)
self.wih = numpy.random.rand(self.hNodes, self.iNodes)-0.5
numpy.random.seed(seedWho)
self.who = numpy.random.rand(self.oNodes, self.hNodes)-0.5
else:
numpy.random.seed(seedWih)
self.wih = numpy.random.normal (0.0, pow(self.hNodes,-0.5), (self.hNodes, self.iNodes))
numpy.random.seed(seedWho)
self.who = numpy.random.normal (0.0, pow(self.oNodes,-0.5), (self.oNodes, self.hNodes))
证明神经网络具有学习能力的方案:
为了减少测试时间,
将MNIST_100迭代训练较多次。
然后将其作为测试数据。如果出现了过拟合状态,承认通过训练其具有学习能力。可以进行下述测试:
参数含义:
输入层节点/隐层结点/输出层节点/学习率/初始化权重的分布方案/输入层和隐层的初始化种子/输出层和隐层的初始化种子/使用的激活函数
激活函数为:softmax:
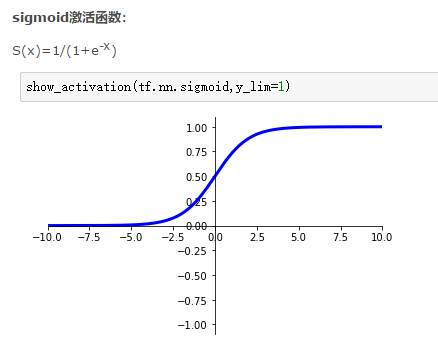
训练1代,达到95.17%的测试识别率。参数为:784/100/10/0.1、rand、4、5、softmax.
训练2代,达到96.16%的测试识别率。参数为:784/100/10/0.1、rand、4、5、softmax.
训练3代,达到96.52%的测试识别率。参数为:784/100/10/0.1、rand、4、5、softmax.
训练4代,达到96.43%的测试识别率。参数为:784/100/10/0.1、rand、4、5、softmax.
训练5代,达到96.56%的测试识别率。参数为:784/100/10/0.1、rand、4、5、softmax.
训练6代,达到96.41%的测试识别率。参数为:784/100/10/0.1、rand、4、5、softmax.
调试参数如下:
inputs = numpy.asfarray( all_values [1:])/255.0*0.99+0.01
targets = numpy.zeros(self.nN.oNodes) + 0.01
targets[int (all_values[0])] = 0.99
fx1=numpy.exp(-final_inputs)/((1+numpy.exp(-final_inputs))*(1+numpy.exp(-final_inputs)))
fx2=numpy.exp(-hidden_inputs)/((1+numpy.exp(-hidden_inputs))*(1+numpy.exp(-hidden_inputs)))
self.who += self.lr * numpy.dot((output_errors * fx1),numpy.transpose(hidden_outputs))
self.wih += self.lr * numpy.dot((hidden_errors * fx2),numpy.transpose(inputs))
激活函数为:softsign:
一点说明:
为什么学习率取值这样
sigmoid*2-1
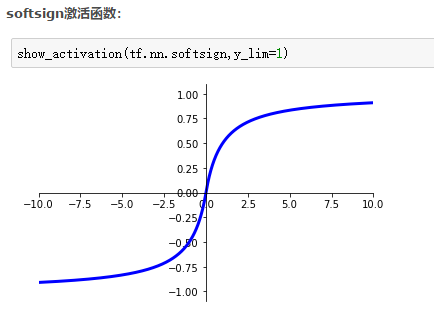
训练5代,达到65.58%的测试识别率。参数为:784/80/10/0.05、normal、4、5、softsign.
训练10代,达到74.39%的测试识别率。参数为:784/80/10/0.05、normal、4、5、softsign.
训练15代,达到76.49%的测试识别率。参数为:784/80/10/0.05、normal、4、5、softsign.
训练20代,达到83.34%的测试识别率。参数为:784/80/10/0.05、normal、4、5、softsign.
训练25代,达到91.8%的测试识别率。参数为:784/80/10/0.05、normal、4、5、softsign.
训练30代,达到92.43%的测试识别率。参数为:784/80/10/0.05、normal、4、5、softsign.
训练35代,达到92.54%的测试识别率。参数为:784/80/10/0.05、normal、4、5、softsign.
调试参数如下:
inputs = numpy.asfarray( all_values [1:])/255.0*0.5
targets = numpy.zeros(self.nN.oNodes) -0.99
targets[int (all_values[0])] = 0.99
fx1=numpy.exp(-final_inputs)/((1+numpy.exp(-final_inputs))*(1+numpy.exp(-final_inputs)))
fx2=numpy.exp(-hidden_inputs)/((1+numpy.exp(-hidden_inputs))*(1+numpy.exp(-hidden_inputs)))
self.who += self.lr * numpy.dot((output_errors * fx1),numpy.transpose(hidden_outputs))
self.wih += self.lr * numpy.dot((hidden_errors * fx2),numpy.transpose(inputs))
激活函数为:tanh:
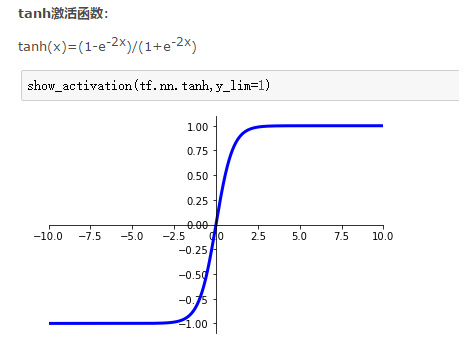
训练1代,达到93.57%的测试识别率。参数为:784/80/10/0.05、normal、4、5、tanh.
训练2代,达到94.44%的测试识别率。参数为:784/80/10/0.05、normal、4、5、tanh.
训练3代,达到94.73%的测试识别率。参数为:784/80/10/0.05、normal、4、5、tanh.
训练4代,达到94.47%的测试识别率。参数为:784/80/10/0.05、normal、4、5、tanh.
训练5代,达到95.05%的测试识别率。参数为:784/80/10/0.05、normal、4、5、tanh.
训练6代,达到95.33%的测试识别率。参数为:784/80/10/0.05、normal、4、5、tanh.
训练7代,达到94.86%的测试识别率。参数为:784/80/10/0.05、normal、4、5、tanh.
调试参数如下:
inputs = numpy.asfarray( all_values [1:])/255.0*0.5
targets = numpy.zeros(self.nN.oNodes) -0.99
targets[int (all_values[0])] = 0.99
fx1=numpy.exp(-2*final_inputs)/((1+numpy.exp(-2*final_inputs))*(1+numpy.exp(-2*final_inputs)))
fx2=numpy.exp(-2*hidden_inputs)/((1+numpy.exp(-2*hidden_inputs))*(1+numpy.exp(-2*hidden_inputs)))
self.who += self.lr * numpy.dot((output_errors * fx1),numpy.transpose(hidden_outputs))
self.wih += self.lr * numpy.dot((hidden_errors * fx2),numpy.transpose(inputs))
激活函数为:relu:
部分说明:
关于学习率。过大的学习率导致学习能力丢失,如0.1的学习率在这里过大。
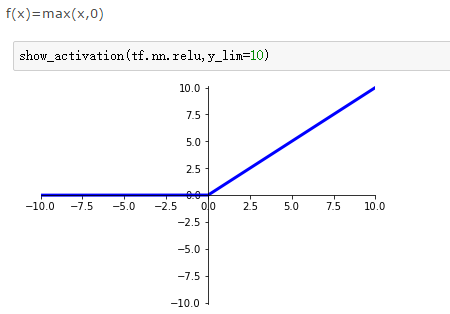
训练1代,达到95.34%的测试识别率。参数为:784/100/10/0.001、rand、4、5、relu.
训练2代,达到96.12%的测试识别率。参数为:784/100/10/0.001、rand、4、5、relu.
训练3代,达到96.65%的测试识别率。参数为:784/100/10/0.001、rand、4、5、relu.
训练4代,达到96.8%的测试识别率。参数为:784/100/10/0.001、rand、4、5、relu.
训练5代,达到96.95%的测试识别率。参数为:784/100/10/0.001、rand、4、5、relu.
训练6代,达到97.08%的测试识别率。参数为:784/100/10/0.001、rand、4、5、relu.
训练7代,达到97.32%的测试识别率。参数为:784/100/10/0.001、rand、4、5、relu.
训练8代,达到97.23%的测试识别率。参数为:784/100/10/0.001、rand、4、5、relu.
调试参数如下:
inputs = numpy.asfarray( all_values [1:])/255.0*0.99+0.01
targets = numpy.zeros(self.nN.oNodes) + 0.01
targets[int (all_values[0])] = 10
final_inputs[final_inputs>0]=1
hidden_inputs[hidden_inputs>0]=1
final_inputs[final_inputs<0]=0
hidden_inputs[hidden_inputs<0]=0
fx1=final_inputs;fx2=hidden_inputs
self.who += self.lr * numpy.dot((output_errors * fx1),numpy.transpose(hidden_outputs))
self.wih += self.lr * numpy.dot((hidden_errors * fx2),numpy.transpose(inputs))
激活函数为:softplus:
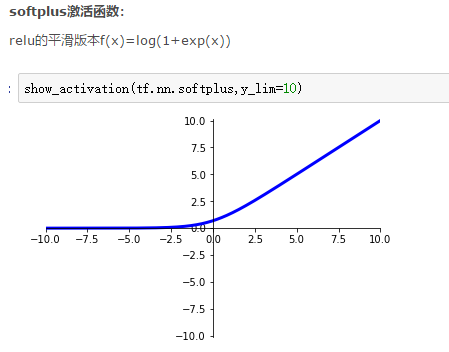
训练1代,达到95.62%的测试识别率。参数为:784/100/10/0.001、rand、4、5、softplus.
训练2代,达到96.47%的测试识别率。参数为:784/100/10/0.001、rand、4、5、softplus.
训练3代,达到96.85%的测试识别率。参数为:784/100/10/0.001、rand、4、5、softplus.
训练4代,达到97.06%的测试识别率。参数为:784/100/10/0.001、rand、4、5、softplus.
训练5代,达到97.18%的测试识别率。参数为:784/100/10/0.001、rand、4、5、softplus.
训练6代,达到97.29%的测试识别率。参数为:784/100/10/0.001、rand、4、5、softplus.
训练7代,达到97.34%的测试识别率。参数为:784/100/10/0.001、rand、4、5、softplus.
训练8代,达到97.39%的测试识别率。参数为:784/100/10/0.001、rand、4、5、softplus.
训练9代,达到97.5%的测试识别率。参数为:784/100/10/0.001、rand、4、5、softplus.
训练10代,达到97.54%的测试识别率。参数为:784/100/10/0.001、rand、4、5、softplus.
训练11代,达到97.61%的测试识别率。参数为:784/100/10/0.001、rand、4、5、softplus.
训练12代,达到97.6%的测试识别率。参数为:784/100/10/0.001、rand、4、5、softplus.
调试参数如下:
inputs = numpy.asfarray( all_values [1:])/255.0*0.99+0.01
targets = numpy.zeros(self.nN.oNodes) + 0.01
targets[int (all_values[0])] = 10
fx1=numpy.exp(final_inputs)/(1+numpy.exp(final_inputs))
fx2=numpy.exp(hidden_inputs)/(1+numpy.exp(hidden_inputs))
self.who += self.lr * numpy.dot((output_errors * fx1),numpy.transpose(hidden_outputs))
self.wih += self.lr * numpy.dot((hidden_errors * fx2),numpy.transpose(inputs))
BP神经网络测试MNIST记录的更多相关文章
- 机器学习入门-BP神经网络模型及梯度下降法-2017年9月5日14:58:16
BP(Back Propagation)网络是1985年由Rumelhart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一. B ...
- bp神经网络模型推导与c语言实现(转载)
转载出处:http://www.cnblogs.com/jzhlin/archive/2012/07/28/bp.html BP 神经网络中的 BP 为 Back Propagation 的简写,最 ...
- BP神经网络模型及梯度下降法
BP(Back Propagation)网络是1985年由Rumelhart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一. B ...
- BP神经网络模型与学习算法
一,什么是BP "BP(Back Propagation)网络是1986年由Rumelhart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,是目前应用最 ...
- BP神经网络模型及算法推导
一,什么是BP "BP(Back Propagation)网络是1986年由Rumelhart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,是目前应用最 ...
- Python实现bp神经网络识别MNIST数据集
title: "Python实现bp神经网络识别MNIST数据集" date: 2018-06-18T14:01:49+08:00 tags: [""] cat ...
- 粒子群优化算法对BP神经网络优化 Matlab实现
1.粒子群优化算法 粒子群算法(particle swarm optimization,PSO)由Kennedy和Eberhart在1995年提出,该算法模拟鸟集群飞行觅食的行为,鸟之间通过集体的协作 ...
- Matlab实现BP神经网络预测(附实例数据及代码)
BP神经网络介绍 神经网络是机器学习中一种常见的数学模型,通过构建类似于大脑神经突触联接的结构,来进行信息处理.在应用神经网络的过程中,处理信息的单元一般分为三类:输入单元.输出单元和隐含单元. 顾名 ...
- BP神经网络公式推导及实现(MNIST)
BP神经网络的基础介绍见:http://blog.csdn.net/fengbingchun/article/details/50274471,这里主要以公式推导为主. BP神经网络又称为误差反向传播 ...
随机推荐
- pta l2-14(列车调度)
题目链接:https://pintia.cn/problem-sets/994805046380707840/problems/994805063166312448 题意:给定n个数的重排列,求至少需 ...
- CentOS systemctl命令
systemctl命令是系统服务管理器指令,它实际上将 service 和 chkconfig 这两个命令组合到一起. 任务 旧指令 新指令 使某服务自动启动 chkconfig --level 3 ...
- PAT1020 (已知中序,后序遍历转前序遍历)
已知后序与中序输出前序(先序):后序:3, 4, 2, 6, 5, 1(左右根)中序:3, 2, 4, 1, 6, 5(左根右) 已知一棵二叉树,输出前,中,后时我们采用递归的方式.同样也应该利用递归 ...
- unity缓动插件DOTween Pro v0.9.680
DoTween Pro是一款unity插件,是unity中最好用的tween插件,比起Dotween的免费版要多很多功能,实现脚本和视觉脚本的新功能,支持包括移动,淡出,颜色,旋转,缩放,打孔,摇动, ...
- 游戏引擎架构,3d游戏引擎设计、Unreal引擎技术等五本PDF推荐
扫码时备注或说明中留下邮箱 付款后如未回复请至https://shop135452397.taobao.com/ 联系店主
- Codeforces Beta Round #46 (Div. 2)
Codeforces Beta Round #46 (Div. 2) http://codeforces.com/contest/49 A #include<bits/stdc++.h> ...
- 项目总结03:window.open()方法用于子窗口数据回调至父窗口,即子窗口操作父窗口
window.open()方法用于子窗口数据回调至父窗口,即子窗口操作父窗口 项目中经常遇到一个业务逻辑:在A窗口中打开B窗口,在B窗口中操作完以后关闭B窗口,同时自动刷新A窗口(或局部更新A窗口)( ...
- 再遇ibatisNet
11年在Mr刘的带领下第一次接触ibatisnet ,当时Mr刘很详细的很讲了xml里的写法还有配置文件之类的,但是随着时间越来越久远.很多东西都开始淡忘了. 如今,再次和它相遇,依然觉得很亲切,虽然 ...
- vue2.0一安装的插件详解
babel-runtime 对ES语法转义 fastclick 移动端300ms兼容 babel-polyfill 兼容Ie浏览器 //babel-polyfill引用 推荐采用webpack入口文 ...
- 扩展、委托、Lambda、linq
1.扩展 扩展是一个很有用的功能.如果你有一个类.不能修改,同时你又想给他加一个方法.这个过程就是扩展.扩展就是扩展方法. 例1: 类People public class People { publ ...