kafka集群监控工具之三--kafka Offset Monitor
1.介绍

一般情况下,功能简单的kafka项目 使用运维命令+kafka Offset Monitor 就足够用了。
2、使用
2.1 部署
github下载jar包 KafkaOffsetMonitor-assembly-0.2.0.jar 地址:https://github.com/quantifind/KafkaOffsetMonitor/releases 注意github版本需要翻墙下载google文件
可以下载百度网盘:https://pan.baidu.com/s/1ntzIUPN 这是大牛已经整好了的
2.2 启动 refresh-刷新时间 retain-驻留时间
步骤一:创建1个目录kafka-offset-console
[cluster@PCS101 ~]$ mkdir kafka-offset-console
[cluster@PCS101 ~]$ mkdir kafka-offset-console/logs
[cluster@PCS101 ~]$ ls kafka-offset-console
步骤二:将jar包上传到kafka-offset-console目录下
[cluster@PCS101 kafka-offset-console]$ ls
KafkaOffsetMonitor-assembly-0.2..jar logs
步骤三:创建一个启动脚本
#!/bin/bash
java -Xms512M -Xmx512M -Xss1024K -XX:PermSize=256m -XX:MaxPermSize=512m -cp KafkaOffsetMonitor-assembly-0.2..jar \
com.quantifind.kafka.offsetapp.OffsetGetterWeb \
--zk 134.32.123.101:,134.32.123.102:,134.32.123.103: \
--port \
--refresh .seconds \
--retain .days >logs/stdout.log >logs/stderr.log &
启动查看日志:
[cluster@PCS101 kafka-offset-console]$ sh ./startkoc.sh
[cluster@PCS101 logs]$ tail -50f stdout.log
serving resources from: jar:file:/home/cluster/kafka-offset-console/KafkaOffsetMonitor-assembly-0.2..jar!/offsetapp
访问:http://134.32.123.101:8086/
Lag标识未消费消息数量。
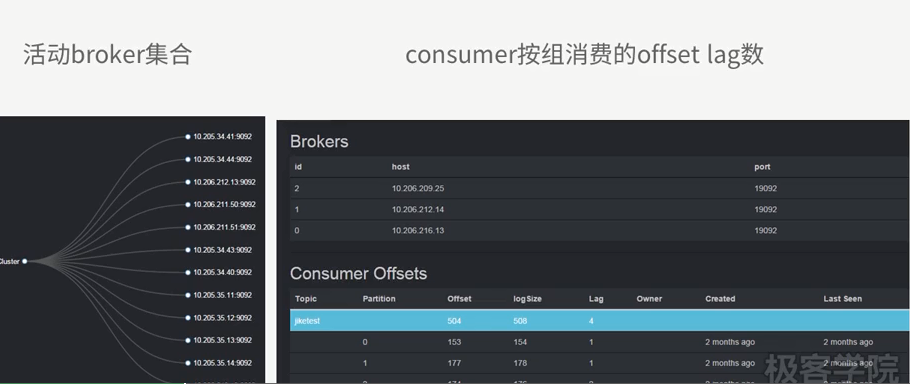
topic:创建时topic名称
partition:分区编号
offset:表示该parition已经消费了多少条message
logSize:表示该partition已经写了多少条message
Lag:表示有多少条message没有被消费。
Owner:表示消费者
Created:该partition创建时间
Last Seen:消费状态刷新最新时间。
参考:
https://www.cnblogs.com/smartloli/p/4562551.html
https://www.cnblogs.com/yinchengzhe/p/5123515.html
https://www.cnblogs.com/dadonggg/p/8242682.html
https://blog.csdn.net/lizhitao/article/details/27199863
kafka集群监控工具之三--kafka Offset Monitor的更多相关文章
- 《Apache kafka实战》读书笔记-kafka集群监控工具
<Apache kafka实战>读书笔记-kafka集群监控工具 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 如官网所述,Kafka使用基于yammer metric ...
- Zookeeper、Kafka集群与Filebeat+Kafka+ELK架构
Zookeeper.Kafka集群与Filebeat+Kafka+ELK架构 目录 Zookeeper.Kafka集群与Filebeat+Kafka+ELK架构 一.Zookeeper 1. Zook ...
- 启动kafka集群,关闭kafka集群脚本
启动kafka集群,关闭kafka集群脚本 在$KAFKA_HOME/bin下新建如下脚本文件 start-kafka.sh #!/bin/bash BROKERS="mini41 mini ...
- 4 kafka集群部署及kafka生产者java客户端编程 + kafka消费者java客户端编程
本博文的主要内容有 kafka的单机模式部署 kafka的分布式模式部署 生产者java客户端编程 消费者java客户端编程 运行kafka ,需要依赖 zookeeper,你可以使用已有的 zo ...
- Kafka集群监控工具之二--Kafka Eagle
基于kafka: kafka_2.11-0.11.0.0.tgz kafka-eagle-bin-1.2.1.tar.gz 1.下载解压 tar -zxvf kafka-eagle-bin-1.2.1 ...
- 如何为Kafka集群选择合适的Partitions数量
转载:http://blog.csdn.net/odailidong/article/details/52571901 这是许多kafka使用者经常会问到的一个问题.本文的目的是介绍与本问题相关的一些 ...
- Kafka相关内容总结(Kafka集群搭建手记)
简介 Kafka is a distributed,partitioned,replicated commit logservice.它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是 ...
- zookeeper kafka集群
一.部署zookeeper集群 三台机器上执行相同的操作 mkdir -p /data/zookeeper cd zookeeper-3.4.6 cp zoo_sample.cfg zoo.cfg [ ...
- 如何为Kafka集群确定合适的分区数以及分区数过多带来的弊端
通过之前的文章<Kafka分区分配策略>和<Kafka高性能揭秘>,我们了解到:Kafka高吞吐量的原因之一就是通过partition将topic中的消息保存到Kafka集群中 ...
随机推荐
- Dockerfile创建镜像
Dockerfile是一个文本格式的配置文件,用户可以使用Dockerfile来快速创建自定义的镜像. Dockerfile由一行行命令语句组成,并且支持易#开头的注释行. 一般而言Dockerfil ...
- python基础-动态加载lazy_import(利用__import__)
看了一天动态加载,普遍有这么几种方法,总结一下,由简入深,本文仅对查到的栗子们做个引用……省去你们大把查资料的时间= = 主要思想:把模块(文件)名.类名.方法名当成了变量 然后利用__import_ ...
- vue--简单数据绑定
<template> <div id="app"> {{msg}} //绑定数据 {{obj.name}} //绑定对象 <p v-for=" ...
- python3之装饰器修复技术@wraps
普通函数 def f(): """ 这是一个用来测试装饰器修复技术的函数 """ print("哈哈哈") if __n ...
- camke中关于变量的一些知识
一.cmake变量引用的方式: 在cmake中,使用${}进行变量的引用.在IF等语句中,是直接使用变量名而不是通过${}取值 二.cmake自定义变量的方式: 主要有隐式定义和显式定义两种,前面举了 ...
- 0000python中文乱码解决方案
#!/usr/bin/env python # coding=utf-8
- Python爬虫框架Scrapy实例(四)下载中间件设置
还是豆瓣top250爬虫的例子,添加下载中间件,主要是设置动态Uesr-Agent和代理IP Scrapy代理IP.Uesr-Agent的切换都是通过DOWNLOADER_MIDDLEWARES进行控 ...
- css 计算属性 calc的使用
宽度等于父元素的宽度减去16像素 高度等于父元素的高度减去16像素 注意:100%和16px 与减号之间必须有空格,否则高度会失效!!!! .box{ width:calc(100% - 16px ...
- 洛谷P4344 脑洞治疗仪 [SHOI2015] 线段树+二分答案/分块
!!!一道巨恶心的数据结构题,做完当场爆炸:) 首先,如果你用位运算的时候不小心<<打成>>了,你就可以像我一样陷入疯狂的死循环改半个小时 然后,如果你改出来之后忘记把陷入死循 ...
- 64位windows 7下配置TortoiseGit(转)
原文:http://our2848884.blog.163.com/blog/static/146854834201152325233854/ 最近感觉自己电脑上的代码太乱了,东一块.西一块……于是决 ...