Kafka集群监控工具之二--Kafka Eagle
基于kafka:
kafka_2.11-0.11.0.0.tgz
kafka-eagle-bin-1.2.1.tar.gz
1.下载解压
tar -zxvf kafka-eagle-bin-1.2.1.tar.gz -C /home/cluster
2.配置
vim /home/cluster/kafka-eagle/conf/system-config.properties
#zookeeper集群别名 可以多个
kafka.eagle.zk.cluster.alias=cluster1,cluster2
#zookeeper集群ip端口清单
cluster1.zk.list=tdn1:2181,tdn2:2181,tdn3:2181
cluster2.zk.list=xdn1:2181,xdn2:2181,xdn3:2181
#zookeeper客户端zkCli最大个数
kafka.zk.limit.size=25
#kafka.eagle管控台访问端口 访问http://ip:8048/ke/
kafka.eagle.webui.port=8048
######################################
# 如果你的offsets存储在Kafka中,这里就配置
# 属性值为kafka,如果是在Zookeeper中,可以
# 注释该属性。一般情况下,Offsets的也和你消
# 费者API有关系,如果你使用的Kafka版本为0.10.x
# 以后的版本,但是,你的消费API使用的是0.8.2.x
# 时的API,此时消费者依然是在Zookeeper中
######################################
cluster1.kafka.eagle.offset.storage=kafka
######################################
# 如果你的集群一个是新版本(0.10.x以上),
# 一个是老版本(0.8或0.9),可以这样设置,
# 如果都是新版本,那么可以将值都设置成kafka
######################################
cluster2.kafka.eagle.offset.storage=zookeeper
######################################
# 是否启动监控图表,默认是不启动的
######################################
kafka.eagle.metrics.charts=false
######################################
# 在使用Kafka SQL查询主题时,如果遇到错误,
# 可以尝试开启这个属性,默认情况下,不开启
######################################
kafka.eagle.sql.fix.error=false
######################################
# 告警邮件配置,添加你的邮件信息,最好是163
######################################
kafka.eagle.mail.enable=true
kafka.eagle.mail.sa=xxx
kafka.eagle.mail.username=xxx@163.com
kafka.eagle.mail.password=password
kafka.eagle.mail.server.host=smtp.163.com
kafka.eagle.mail.server.port=25
######################################
# 设置告警用户,多个用户以英文逗号分隔
######################################
kafka.eagle.alert.users=smartloli.org@gmail.com
######################################
# 超级管理员删除主题的Token
######################################
kafka.eagle.topic.token=keadmin
######################################
# 如果启动Kafka SASL协议,开启该属性
######################################
kafka.eagle.sasl.enable=false
kafka.eagle.sasl.protocol=SASL_PLAINTEXT
kafka.eagle.sasl.mechanism=PLAIN
#kafka.eagle使用的DB信息
kafka.eagle.driver=org.sqlite.JDBC
kafka.eagle.url=jdbc:sqlite:/hadoop/kafka-eagle/db/ke.db
kafka.eagle.username=root
kafka.eagle.password=smartloli
3.启动关闭
[cluster@PCS101 bin]$
#启动
/home/cluster/kafka-eagle/bin/ke.sh start
#关闭
/home/cluster/kafka-eagle/bin/ke.sh stop
#重启
/home/cluster/kafka-eagle/bin/ke.sh restart
#查看状态
/home/cluster/kafka-eagle/bin/ke.sh status
#查看连接状态
/home/cluster/kafka-eagle/bin/ke.sh stats
启动日志:
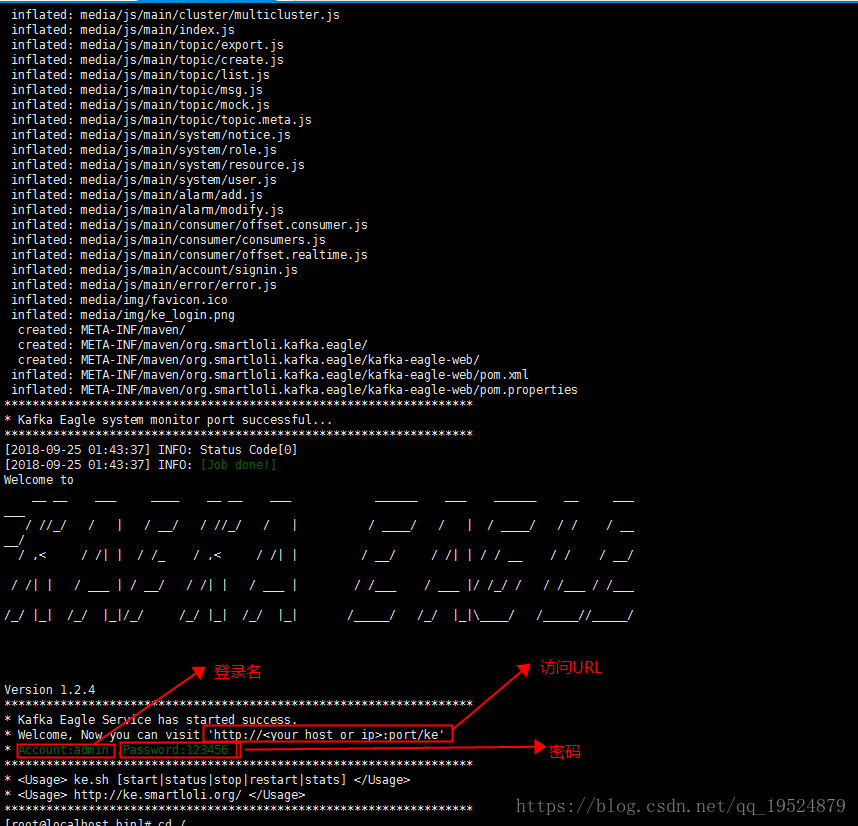
参考:
Kafka Eagle配置文件:https://ke.smartloli.org/2.Install/2.Installing.html
Kafka Eagle 下载地址:http://download.smartloli.org/
或者 https://github.com/smartloli/kafka-eagle
Kafka Eagle 使用文档:https://ke.smartloli.org/
Kafka监控系统Kafka Eagle剖析:https://www.cnblogs.com/smartloli/p/9371904.html
Kafka集群监控工具之二--Kafka Eagle的更多相关文章
- 《Apache kafka实战》读书笔记-kafka集群监控工具
<Apache kafka实战>读书笔记-kafka集群监控工具 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 如官网所述,Kafka使用基于yammer metric ...
- zookeeper+kafka集群安装之二
zookeeper+kafka集群安装之二 此为上一篇文章的续篇, kafka安装需要依赖zookeeper, 本文与上一篇文章都是真正分布式安装配置, 可以直接用于生产环境. zookeeper安装 ...
- Kafka集群安装部署、Kafka生产者、Kafka消费者
Storm上游数据源之Kakfa 目标: 理解Storm消费的数据来源.理解JMS规范.理解Kafka核心组件.掌握Kakfa生产者API.掌握Kafka消费者API.对流式计算的生态环境有深入的了解 ...
- kafka集群的错误处理--kafka一个节点挂了,导致消费失败
今天由于kafka集群搭建时的配置不当,由于一台主消费者挂掉(服务器崩了,需要维修),导致了所有新版消费者(新版的offset存储在kafka)都无法拉取消息. 由于是线上问题,所以是绝对不能影响用户 ...
- kafka集群监控工具之三--kafka Offset Monitor
1.介绍 一般情况下,功能简单的kafka项目 使用运维命令+kafka Offset Monitor 就足够用了. 2.使用2.1 部署 github下载jar包 KafkaOffsetMonit ...
- Kafka集群的安装和使用
Kafka是一种高吞吐量的分布式发布订阅的消息队列系统,原本开发自LinkedIn,用作LinkedIn的活动流(ActivityStream)和运营数据处理管道(Pipeline)的基础.现在它已被 ...
- zookeeper kafka集群
一.部署zookeeper集群 三台机器上执行相同的操作 mkdir -p /data/zookeeper cd zookeeper-3.4.6 cp zoo_sample.cfg zoo.cfg [ ...
- 即将上线的Kafka 集群(用CM部署的)无法使用“--bootstrap-server”进行消费,怎么破?
即将上线的Kafka 集群(用CM部署的)无法使用“--bootstrap-server”进行消费,怎么破? 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.报错:org.a ...
- 【kafka学习之三】kafka集群运维
kafka集群维护一.kafka集群启停#启动kafka/home/cluster/kafka211/bin/kafka-server-start.sh -daemon /home/cluster/k ...
随机推荐
- JavaScript—倒计时
当前时间-倒计时下载 效果: 代码: <!doctype html> <html> <head> <meta http-equiv="Content ...
- MassTransit
http://stackoverflow.com/questions/15485317/newbie-is-a-consumer-queue-necessary-in-order-for-publis ...
- 【BZOJ2331】[SCOI2011]地板 插头DP
[BZOJ2331][SCOI2011]地板 Description lxhgww的小名叫“小L”,这是因为他总是很喜欢L型的东西.小L家的客厅是一个的矩形,现在他想用L型的地板来铺满整个客厅,客厅里 ...
- [工具] CintaNotes
CintaNotes是一款非常轻巧实用的笔记软件,可看作EverNote轻量级替代品.CintaNotes只需1个exe,体积仅1MB,却拥有 EverNote易于收集.实时搜索.条状排列.tag分类 ...
- 在python pydev中使用todo标注任务
在做自动化测试时,有部分代码因需求未定或界面需要更改,代码不做修改或更新,这里就需要用到TODO功能. 在PyCharm中TODO功能很详细,但在pydev中怎么用呢.看了文档后,截图如下: 1.设置 ...
- MVC @RenderBody、@RenderSection、@RenderPage、@Html.RenderPartial、@Html.RenderAction
1.@RenderBody() 作用和母版页中的服务器控件类似,当创建基于此布局页面的视图时,视图的内容会和布局页面合并,而新创建视图的内容会通过布局页面的@RenderBody()方法呈现在标签之间 ...
- numpy生成随机数组
python想要生成随机数的话用使用random库很方便,不过如果想生成随机数组的话,还是用numpy更好更强大一点. 生成长度为10,在[0,1)之间平均分布的随机数组: rarray=numpy. ...
- python模块路径
Python会在以下路径中搜索它想要寻找的模块: 1. 程序所在的文件夹 2. 标准库的安装路径 3. 操作系统环境变量PYTHONPATH所包含的路径 将自定义库的路径添加到Python的库路径中去 ...
- pandas常用
#python中的pandas库主要有DataFrame和Series类(面向对象的的语言更愿意叫类) DataFrame也就是#数据框(主要是借鉴R里面的data.frame),Series也就是序 ...
- python3之装饰器修复技术@wraps
普通函数 def f(): """ 这是一个用来测试装饰器修复技术的函数 """ print("哈哈哈") if __n ...