python接口自动化-token参数关联登录(二)
原文地址https://www.cnblogs.com/yoyoketang/p/9098096.html
原文地址https://www.cnblogs.com/yoyoketang/p/6886610.html
原文地址https://www.cnblogs.com/yoyoketang/
原文地址https://www.cnblogs.com/yoyoketang/p/7259993.html
前言
登录网站的时候,经常会遇到传token参数,token关联并不难,难的是找出服务器第一次返回token的值所在的位置,取出来后就可以动态关联了
登录拉勾网
1.先找到登录首页https://passport.lagou.com/login/login.html,输入账号和密码登录,抓包看详情
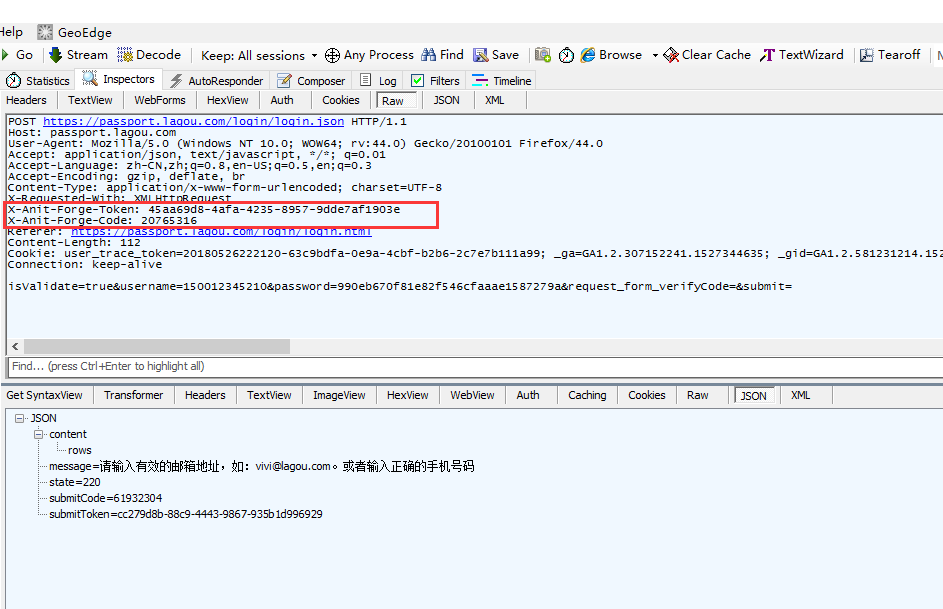
2.再重新登录一次抓包看的时候,头部有两个参数是动态的,token和code值每次都会不一样,只能用一次
X-Anit-Forge-Token: 45aa69d8-4afa-4235-8957-9dde7af1903e
X-Anit-Forge-Code: 20765316找到token生成的位置
1.打开登录首页https://passport.lagou.com/login/login.html,直接按F5刷新(只做刷新动作,不输入账号和密码),然后从返回的页面找到token生成的位置
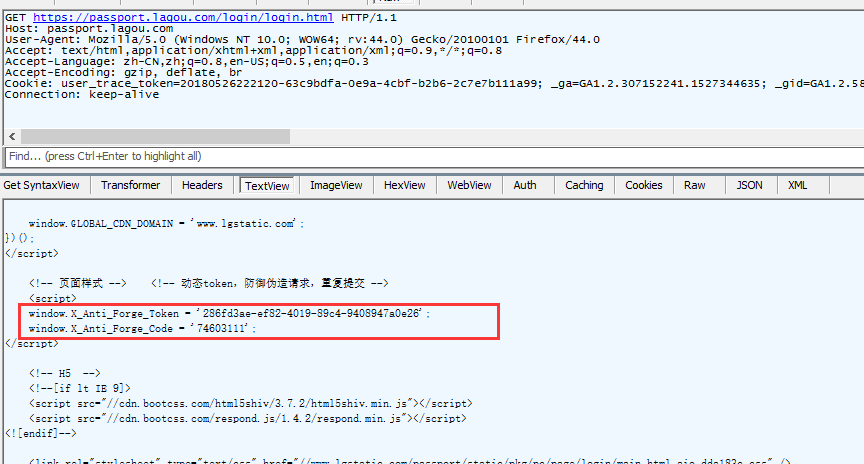
</script>
<!-- 页面样式 --> <!-- 动态token,防御伪造请求,重复提交 -->
<script>
window.X_Anti_Forge_Token = '286fd3ae-ef82-4019-89c4-9408947a0e26';
window.X_Anti_Forge_Code = '74603111';
</script>
前端的代码,注释内容暴露了token位置,嘿嘿!
2.接下来从返回的html里面解析出token和code两个参数的值
# coding:utf-8
import requests
import re
from bs4 import BeautifulSoup # 作者:上海-悠悠 QQ交流群:512200893 def getTokenCode(s):
'''
要从登录页面提取token,code, 然后在头信息里面添加
<!-- 页面样式 --><!-- 动态token,防御伪造请求,重复提交 -->
<script type="text/javascript">
window.X_Anti_Forge_Token = 'dde4db4a-888e-47ca-8277-0c6da6a8fc19';
window.X_Anti_Forge_Code = '61142241';
</script>
'''
url = 'https://passport.lagou.com/login/login.html'
h = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0",
}
# 更新session的headers
s.headers.update(h)
data = s.get(url, verify=False)
soup = BeautifulSoup(data.content, "html.parser", from_encoding='utf-8')
tokenCode = {}
try:
t = soup.find_all('script')[1].get_text()
print(t)
tokenCode['X_Anti_Forge_Token'] = re.findall(r"Token = '(.+?)'", t)[0]
tokenCode['X_Anti_Forge_Code'] = re.findall(r"Code = '(.+?)'", t)[0]
except:
print("获取token和code失败")
tokenCode['X_Anti_Forge_Token'] = ""
tokenCode['X_Anti_Forge_Code'] = ""
return tokenCode
模拟登陆
1.登陆的时候这里密码参数虽然加密了,但是是固定的加密方式,所以直接复制抓包的加密后字符串就行了
# coding:utf-8
import requests
import re
from bs4 import BeautifulSoup # 作者:上海-悠悠 QQ交流群:512200893 def login(s, gtoken, user, psw):
'''
function:登录拉勾网网站
:param s: 传s = requests.session()
:param gtoken: 上一函数getTokenCode返回的tokenCode
:param user: 账号
:param psw: 密码
:return: 返回json
'''
url2 = 'https://passport.lagou.com/login/login.json'
h2 = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"X-Requested-With": "XMLHttpRequest",
"X-Anit-Forge-Token": gtoken['X_Anti_Forge_Token'],
"X-Anit-Forge-Code": gtoken['X_Anti_Forge_Code'],
"Referer": "https://passport.lagou.com/login/login.html",
} # 更新s的头部
s.headers.update(h2) body = {
"isValidate":'true',
"username": user,
"password": psw,
"request_form_verifyCode": "",
"submit": ""
}
r2 = s.post(url2 , data=body, verify=False)
print(r2.text)
return r2.json()
密码加密
1.这里密码是md5加密的(百度看了其它大神的博客,才知道的)
# coding:utf-8
import requests
import re
from bs4 import BeautifulSoup
import hashlib def encryptPwd(passwd):
# 作者:上海-悠悠 QQ交流群:512200893
# 对密码进行了md5双重加密
passwd = hashlib.md5(passwd.encode('utf-8')).hexdigest()
# veennike 这个值是在js文件找到的一个写死的值
passwd = 'veenike'+passwd+'veenike'
passwd = hashlib.md5(passwd.encode('utf-8')).hexdigest()
return passwd
if __name__ == "__main__":
# 测试密码123456
print(encryptPwd(""))
输出结果:
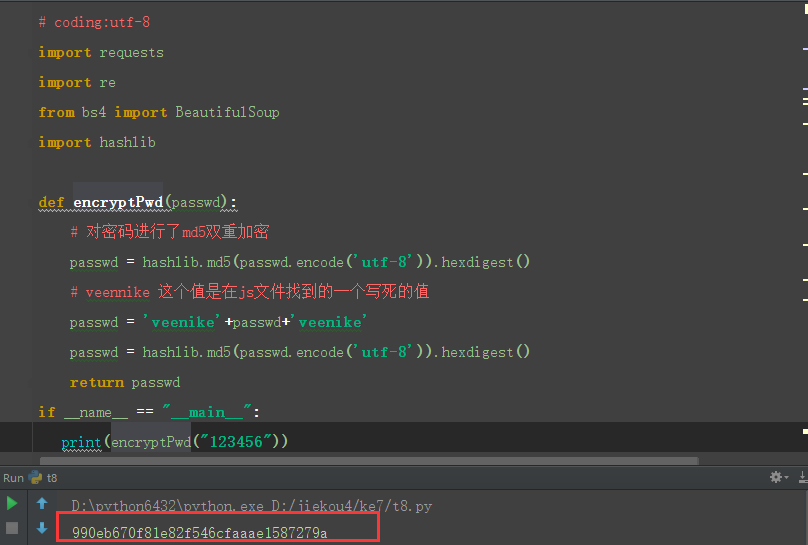
2.跟抓包的数据对比,发现是一样的,说明加密成功
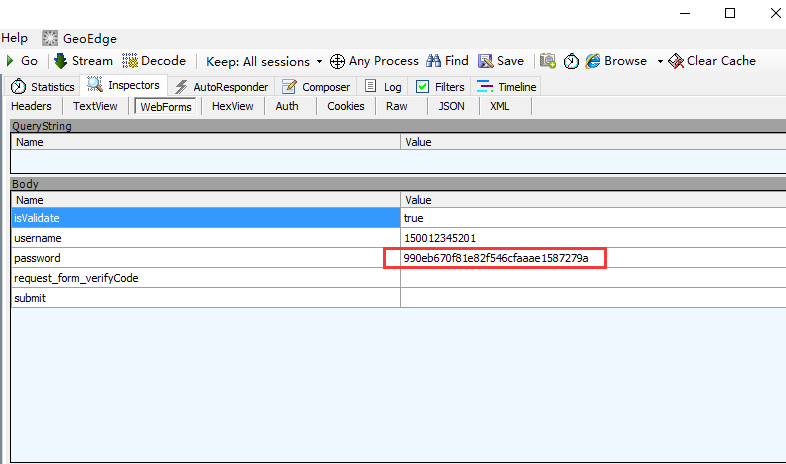
参考代码:
# coding:utf-8
import requests
import re
from bs4 import BeautifulSoup
import urllib3
import hashlib
urllib3.disable_warnings() # 作者:上海-悠悠 QQ交流群:512200893 class LoginLgw(): def __init__(self, s):
self.s = s def getTokenCode(self):
'''
要从登录页面提取token,code, 然后在头信息里面添加
<!-- 页面样式 --><!-- 动态token,防御伪造请求,重复提交 -->
<script type="text/javascript">
window.X_Anti_Forge_Token = 'dde4db4a-888e-47ca-8277-0c6da6a8fc19';
window.X_Anti_Forge_Code = '61142241';
</script>
'''
url = 'https://passport.lagou.com/login/login.html'
h = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0",
}
# 更新session的headers
self.s.headers.update(h)
data = self.s.get(url, verify=False)
soup = BeautifulSoup(data.content, "html.parser", from_encoding='utf-8')
tokenCode = {}
try:
t = soup.find_all('script')[1].get_text()
print(t)
tokenCode['X_Anti_Forge_Token'] = re.findall(r"Token = '(.+?)'", t)[0]
tokenCode['X_Anti_Forge_Code'] = re.findall(r"Code = '(.+?)'", t)[0]
return tokenCode
except:
print("获取token和code失败")
tokenCode['X_Anti_Forge_Token'] = ""
tokenCode['X_Anti_Forge_Code'] = ""
return tokenCode def encryptPwd(self,passwd):
# 对密码进行了md5双重加密
passwd = hashlib.md5(passwd.encode('utf-8')).hexdigest()
# veennike 这个值是在js文件找到的一个写死的值
passwd = 'veenike'+passwd+'veenike'
passwd = hashlib.md5(passwd.encode('utf-8')).hexdigest()
return passwd def login(self, user, psw):
'''
function:登录拉勾网网站
:param user: 账号
:param psw: 密码
:return: 返回json
'''
gtoken = self.getTokenCode()
print(gtoken)
print(gtoken['X_Anti_Forge_Token'])
print(gtoken['X_Anti_Forge_Code'])
url2 = 'https://passport.lagou.com/login/login.json'
h2 = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"X-Requested-With": "XMLHttpRequest",
"X-Anit-Forge-Token": gtoken['X_Anti_Forge_Token'],
"X-Anit-Forge-Code": gtoken['X_Anti_Forge_Code'],
"Referer": "https://passport.lagou.com/login/login.html",
} # 更新s的头部
self.s.headers.update(h2)
passwd = self.encryptPwd(psw) body = {
"isValidate":'true',
"username": user,
"password": passwd,
"request_form_verifyCode": "",
"submit": ""
}
r2 = self.s.post(url2 , data=body, verify=False)
try:
print(r2.text)
return r2.json()
except:
print("登录异常信息:%s" % r2.text)
return None if __name__ == "__main__":
s = requests.session()
lgw = LoginLgw(s)
lgw.login("", "")
python接口自动化-token参数关联登录(二)的更多相关文章
- python接口自动化-token参数关联登录(登录拉勾网)
前言 登录网站的时候,经常会遇到传token参数,token关联并不难,难的是找出服务器第一次返回token的值所在的位置,取出来后就可以动态关联了 登录拉勾网 1.先找到登录首页https://pa ...
- python接口自动化23-token参数关联登录(登录拉勾网)
前言 登录网站的时候,经常会遇到传token参数,token关联并不难,难的是找出服务器第一次返回token的值所在的位置,取出来后就可以动态关联了 登录拉勾网 1.先找到登录首页https://pa ...
- python接口自动化7-参数关联
前言 我们用自动化发帖之后,要想接着对这篇帖子操作,那就需要用参数关联了,发帖之后会有一个帖子的id,获取到这个id,继续操作传这个帖子id就可以了 (博客园的登录机制已经变了,不能用账号和密码登录了 ...
- python接口自动化-Cookie_绕过验证码登录
前言 有些登录的接口会有验证码,例如:短信验证码,图形验证码等,这种登录的验证码参数可以从后台获取(或者最直接的可查数据库) 获取不到也没关系,可以通过添加Cookie的方式绕过验证码 前面在“pyt ...
- python接口自动化4-绕过验证码登录(cookie)
前言 有些登录的接口会有验证码:短信验证码,图形验证码等,这种登录的话验证码参数可以从后台获取的(或者查数据库最直接). 获取不到也没关系,可以通过添加cookie的方式绕过验证码. 一.抓登录coo ...
- python接口自动化26-参数关联和JSESSIONID(上个接口返回数据作为下个接口请求参数)
前言 参数关联是接口测试和性能测试最为重要的一个步骤,很多接口的请求参数是动态的,并且需要从上一个接口的返回值里面取出来,一般只能用一次就失效了. 最常见的案例就是网站的登录案例,很多网站的登录并不仅 ...
- python接口自动化7-参数关联【转载】
本篇转自博客:上海-悠悠 原文地址:http://www.cnblogs.com/yoyoketang/tag/python%E6%8E%A5%E5%8F%A3%E8%87%AA%E5%8A%A8%E ...
- python接口自动化4-绕过验证码登录(cookie)【转载】
本篇转自博客:上海-悠悠 原文地址:http://www.cnblogs.com/yoyoketang/tag/python%E6%8E%A5%E5%8F%A3%E8%87%AA%E5%8A%A8%E ...
- python接口自动化4-绕过验证码登录(cookie) (转载)
前言 有些登录的接口会有验证码:短信验证码,图形验证码等,这种登录的话验证码参数可以从后台获取的(或者查数据库最直接). 获取不到也没关系,可以通过添加cookie的方式绕过验证码. 一.抓登录coo ...
随机推荐
- 【Eclipse】一个简单的 RCP 应用 —— 显示Eclipse 的启动时间。
1 创建一个插件项目 1.1 File - New - Plug-in Project 注: 1 如果 New 下没有 Plug-in Project , 到 Other 里面去找. 2 如上截图的下 ...
- 使用virtualbox 配置 linux host-only虚拟主机连接外网(转载)
host-only 下的虚拟机之间可以互相访问,虚拟机和宿主机可以互相访问,但是虚拟机不能访问外网. 需要设置: 1.宿主机设置 先对宿主机(windows机器,我这里是win7系统)进行相关配置. ...
- vue Element动态设置el-menu导航当前选中项
1,npm install vuex --save 2,在src下新建vuex文件夹,新建store.js文件: store.js import Vue from 'vue' import Vuex ...
- Shell语法整理,持续维护
Shell shell条件表达式: CONDITIONAL EXPRESSIONSConditional expressions are used by the [[ compound command ...
- SIM900A基站定位调试笔记 -转
第1步:ATE1 握手并设置回显 第2步:AT+CGMR 查看SIM900的版本信号 第3步:AT+CSQ 查看信号质量 第4步:AT+CREG? 查看GSM是否注册成功 第5步:AT+CGREG? ...
- 【CF815D】Karen and Cards 单调栈+扫描线
[CF815D]Karen and Cards 题意:一张卡片有三个属性a,b,c,其上限分别为A,B,C,现在有n张卡片,定义一张卡片能打败另一张卡片当且仅当它的至少两项属性要严格大于另一张的对应属 ...
- 使用curl进行s3服务操作
最近使用curl对s3进行接口测试,本想写个总结文档,但没想到已有前辈写了,就直接搬过来做个记录吧,原文见: http://blog.csdn.net/ganggexiongqi/article/de ...
- 关于Jmeter3.0,你必须要知道的5点变化
2016.5.18日,Apache 发布了jmeter 3.0版本,本人第一时间上去查看并下载使用了,然后群里或同事都会问有什么样变化呢?正好在网上看到一遍关于3.0的文章,但是是英文的.这里翻译一下 ...
- Unity3D 面试三 ABCDE
说说AB两次面试: “金三银四” 三月份末又面试过两家:共和新路2989弄1号1001这家找了我半天,哇好漂亮的办公大楼!问了保安才知道,这个地址是小区地址.另一家也是创业公司面试我的自称是在腾讯做过 ...
- Django---路由如何配置
具体配置在项目配置文件夹下的 urls.py: from index import views urlpatterns = [ path('admin/', admin.site.urls), pat ...