Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks论文理解
一、创新点和解决的问题
创新点
设计Region Proposal Networks【RPN】,利用CNN卷积操作后的特征图生成region proposals,代替了Selective Search、EdgeBoxes等方法,速度上提升明显;
训练Region Proposal Networks与检测网络【Fast R-CNN】共享卷积层,大幅提高网络的检测速度。
解决的问题
继Fast R-CNN后,在CPU上实现的区域建议算法Selective Search【2s/image】、EdgeBoxes【0.2s/image】等成了物体检测速度提升上的最大瓶颈。
二、整体框架
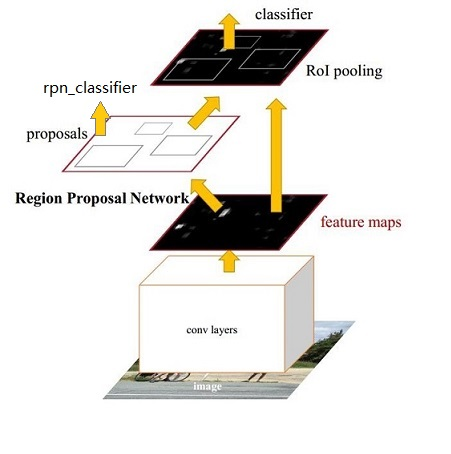
我们先整体的介绍下上图中各层主要的功能:
1)、Conv layers提取特征图:
作为一种CNN网络目标检测方法,Faster RCNN首先使用一组基础的conv+relu+pooling层提取input image的feature maps,该feature maps会用于后续的RPN层和全连接层
2)、RPN(Region Proposal Networks):
RPN网络主要用于生成region proposals,首先生成一堆Anchor box,对其进行裁剪过滤后通过softmax判断anchors属于前景(foreground)或者后景(background),即是物体or不是物体,所以这是一个二分类;同时,另一分支bounding box regression修正anchor box,形成较精确的proposal(注:这里的较精确是相对于后面全连接层的再一次box regression而言)
3)、Roi Pooling:
该层利用RPN生成的proposals和VGG16最后一层得到的feature map,得到固定大小的proposal feature map,进入到后面可利用全连接操作来进行目标识别和定位
4)、Classifier:
会将Roi Pooling层形成固定大小的feature map进行全连接操作,利用Softmax进行具体类别的分类,同时,利用L1 Loss完成bounding box regression回归操作获得物体的精确位置.
三、网络结构
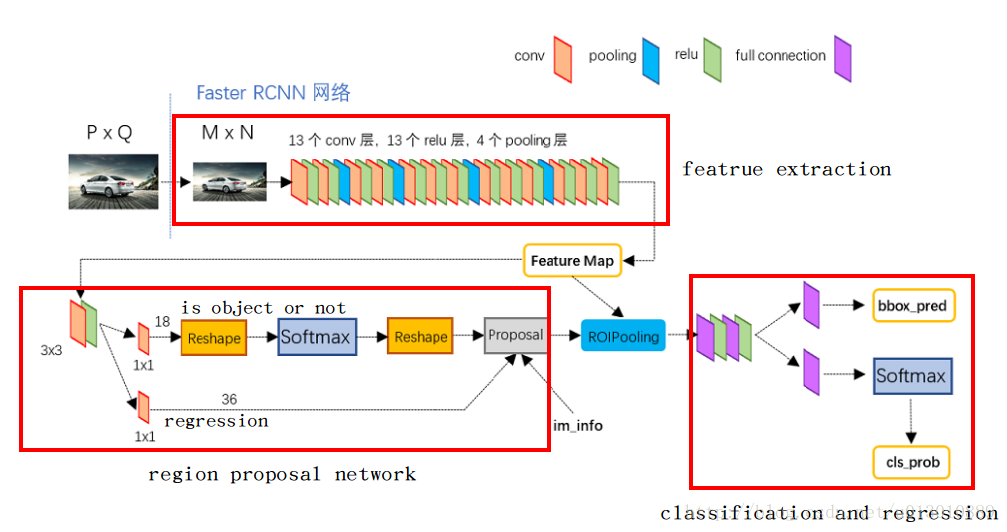
现在,通过上图开始逐层分析
1)、Conv layers
Faster RCNN首先是支持输入任意大小的图片的,比如上图中输入的P*Q,进入网络之前对图片进行了规整化尺度的设定,如可设定图像短边不超过600,图像长边不超过1000,我们可以假定M*N=1000*600(如果图片少于该尺寸,可以边缘补0,即图像会有黑色边缘)
① 13个conv层:kernel_size=3,pad=1,stride=1;
卷积公式: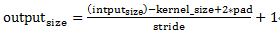
所以,conv层不会改变图片大小(即:输入的图片大小=输出的图片大小)
② 13个relu层:激活函数,不改变图片大小
③ 4个pooling层:kernel_size=2,stride=2;pooling层会让输出图片是输入图片的1/2
经过Conv layers,图片大小变成(M/16)*(N/16),即:60*40(1000/16≈60,600/16≈40);则,Feature Map就是60*40*512-d(注:VGG16是512-d,ZF是256-d),表示特征图的大小为60*40,数量为512
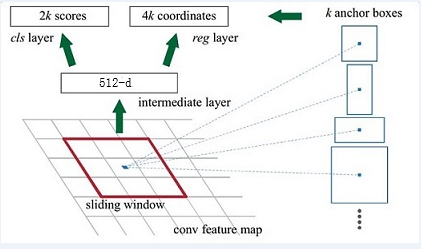
2)、RPN(Region Proposal Networks):
为了进一步更清楚的看懂RPN的工作原理,将Caffe版本下的网络图贴出来,对照网络图进行讲解会更清楚
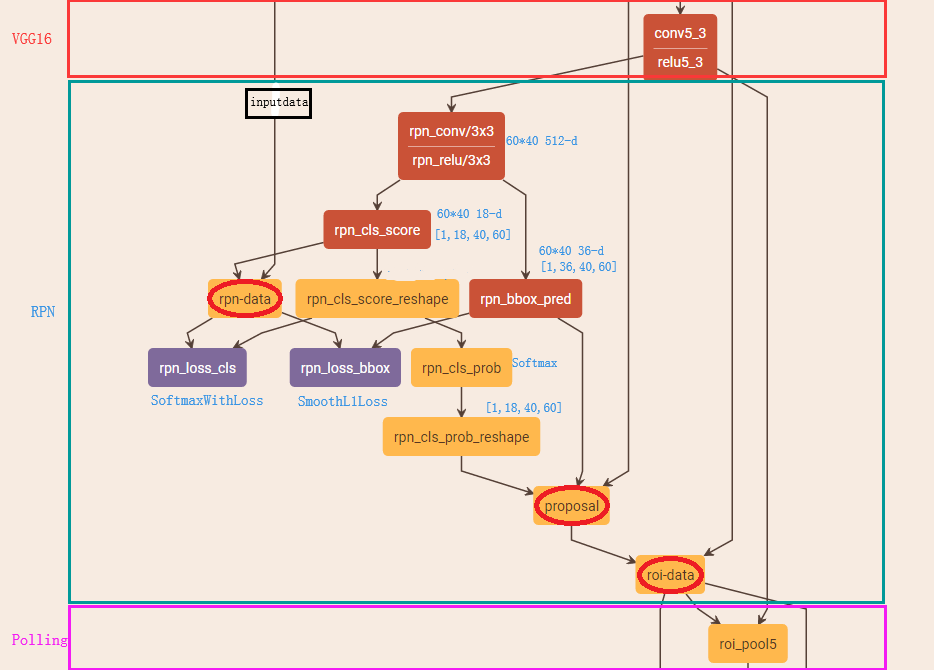
(2.1) rpn_cls、 rpn_bbox
Feature Map进入RPN后,先经过一次3*3的卷积,同样,特征图大小依然是60*40,数量512,这样做的目的应该是进一步集中特征信息,接着看到两个全卷积,即kernel_size=1*1,p=0,stride=1;
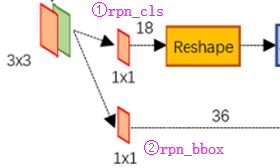
如上图中标识:
① rpn_cls:60*40*512-d ⊕ 1*1*512*18 ==> 60*40*9*2
逐像素对其9个Anchor box进行二分类
② rpn_bbox:60*40*512-d ⊕ 1*1*512*36==>60*40*9*4
逐像素得到其9个Anchor box四个坐标信息(其实是偏移量,后面介绍)
如下图所示:
(2.2)、Anchors的生成规则
前面提到经过Conv layers后,图片大小变成了原来的1/16,令feat_stride=16,在生成Anchors时,我们先定义一个base_anchor,大小为16*16的box(因为特征图(60*40)上的一个点,可以对应到原图(1000*600)上一个16*16大小的区域),源码中转化为[0,0,15,15]的数组,参数ratios=[0.5, 1, 2]scales=[8, 16, 32]
先看[0,0,15,15],面积保持不变,长、宽比分别为[0.5, 1, 2]是产生的Anchors box
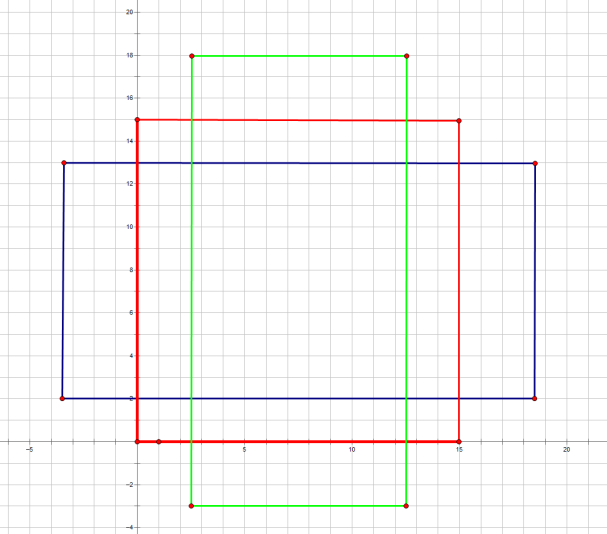
如果经过scales变化,即长、宽分别均为 (16*8=128)、(16*16=256)、(16*32=512),对应anchor box如图
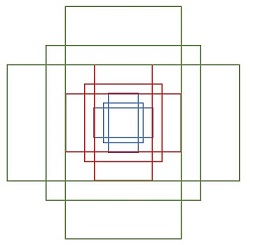
综合以上两种变换,最后生成9个Anchor box
特征图大小为60*40,所以会一共生成60*40*9=21600个Anchor box
源码中,通过width:(0~60)*16,height(0~40)*16建立shift偏移量数组,再和base_ancho基准坐标数组累加,得到特征图上所有像素对应的Anchors的坐标值,是一个[216000,4]的数组
(2.3)rpn-data
这一层主要是为特征图60*40上的每个像素生成9个Anchor box,并且对生成的Anchor box进行过滤和标记,参照源码,过滤和标记规则如下:
① 去除掉超过1000*600这原图的边界的anchor box
② 如果anchor box与ground truth的IoU值最大,标记为正样本,label=1
③ 如果anchor box与ground truth的IoU>0.7,标记为正样本,label=1
④ 如果anchor box与ground truth的IoU<0.3,标记为负样本,label=0
剩下的既不是正样本也不是负样本,不用于最终训练,label=-1
除了对anchor box进行标记外,另一件事情就是计算anchor box与ground truth之间的偏移量
令:ground truth:标定的框也对应一个中心点位置坐标x*,y*和宽高w*,h*
anchor box: 中心点位置坐标x_a,y_a和宽高w_a,h_a
所以,偏移量:
△x=(x*-x_a)/w_a △y=(y*-y_a)/h_a
△w=log(w*/w_a) △h=log(h*/h_a)
通过ground truth box与预测的anchor box之间的差异来进行学习,从而是RPN网络中的权重能够学习到预测box的能力
(2.4)rpn_loss_cls、rpn_loss_bbox、rpn_cls_prob
‘rpn_loss_cls’、‘rpn_loss_bbox’是分别对应softmax,smooth L1计算损失函数,‘rpn_cls_prob’计算概率值(可用于下一层的nms非最大值抑制操作)
(2.5)proposal
源码中,会重新生成60*40*9个anchor box,然后累加上训练好的△x, △y, △w, △h,从而得到了相较于之前更加准确的预测框region proposal,进一步对预测框进行越界剔除和使用nms非最大值抑制,剔除掉重叠的框;比如,设定IoU为0.7的阈值,即仅保留覆盖率不超过0.7的局部最大分数的box(粗筛)。最后留下大约2000个anchor,然后再取前N个box(比如300个);这样,进入到下一层ROI Pooling时region proposal大约只有300个
(2.6)roi_data
为了避免定义上的误解,我们将经过‘proposal’后的预测框称为region proposal(其实,RPN层的任务其实已经完成,roi_data属于为下一层准备数据)
主要作用:
① RPN层只是来确定region proposal是否是物体(是/否),这里根据region proposal和ground truth box的最大重叠指定具体的标签(就不再是二分类问题了,参数中指定的是81类)
② 计算region proposal与ground truth boxes的偏移量,计算方法和之前的偏移量计算公式相同
经过这一步后的数据输入到ROI Pooling层进行进一步的分类和定位.
剩下的就是Fast R-CNN了。
参考:
https://www.cnblogs.com/wangyong/p/8513563.html
https://blog.csdn.net/WoPawn/article/details/52223282
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks论文理解的更多相关文章
- Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks(理解)
0 - 背景 R-CNN中检测步骤分成很多步骤,fast-RCNN便基于此进行改进,将region proposals的特征提取融合成共享卷积层问题,但是,fast-RCNN仍然采用了selectiv ...
- 中文版 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 摘要 最先进的目标检测网络依靠区域提出算法 ...
- 深度学习论文翻译解析(十三):Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
论文标题:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 标题翻译:基于区域提议(Regi ...
- [论文理解] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 简介 Faster R-CNN是很经典的t ...
- 目标检测(四)Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
作者:Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun SPPnet.Fast R-CNN等目标检测算法已经大幅降低了目标检测网络的运行时间. ...
- 论文阅读笔记二十七:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks(CVPR 2016)
论文源址:https://arxiv.org/abs/1506.01497 tensorflow代码:https://github.com/endernewton/tf-faster-rcnn 室友对 ...
- Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
将 RCN 中下面 3 个独立模块整合在一起,减少计算量: CNN:提取图像特征 SVM:目标分类识别 Regression 模型:定位 不对每个候选区域独立通过 CN 提取特征,将整个图像通过 CN ...
- 【CV论文阅读】Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
由RCNN到FAST RCNN一个很重要的进步是实现了多任务的训练,但是仍然使用Selective Search算法来获得ROI,而FASTER RCNN就是把获得ROI的步骤使用一个深度网络RPN来 ...
- R-CNN(Rich feature hierarchies for accurate object detection and semantic segmentation)论文理解
论文地址:https://arxiv.org/pdf/1311.2524.pdf 翻译请移步: https://www.cnblogs.com/xiaotongtt/p/6691103.html ht ...
随机推荐
- cocos代码研究(6)有限时间动作类(FiniteTimeAction)学习笔记
理论部分 有限时间动作类继承自Action类,被 ActionInstant(即时动作) , 以及 ActionInterval(持续动作) 继承. 即时动作是会立即被执行的动作,被 CallFunc ...
- Trove系列(三)—Trove的功能管理功能介绍
Trove的功能管理功能Trove的功能管理功能包括给各种不同的版本的 datastore 安装不同的 功能. 本管理功能只适用于激活/去活全系统的功能.唯一例外的是数据存储功能列表功能,该功能对所有 ...
- EditPlus 5.1.2066 中文版(1月30日修正)
之前有一些网友反馈汉化版的 EditPlus 中翻页键无法正常工作.经过调查,发现是翻译工具的问题. 因此,我用新的工具重新翻译了 EditPlus.翻页键在新中文版中应该可以正常工作了. 有需要的网 ...
- Zookeeper使用实例——服务节点管理
分布式处理中,总会存在多个服务节点同时工作,并且节点数量会随着网络规模的变化而动态增减,服务节点也有可能发生宕机与恢复.面对着动态增减的服务节点,我们如何保证客户请求被服务器正确处理呢.我们可以通过z ...
- java commons.lang3 ArrayUtils使用
java commons.lang3 ArrayUtils使用import org.apache.commons.lang3.ArrayUtils; /** *数组追加数组,不重复 */ public ...
- Python入门之面向对象编程(四)Python描述器详解
本文分为如下部分 引言——用@property批量使用的例子来引出描述器的功能 描述器的基本理论及简单实例 描述器的调用机制 描述器的细节 实例方法.静态方法和类方法的描述器原理 property装饰 ...
- java replaceAll之$替换
最近,在开发一个伪代码翻译工具的过程中,遇到个问题,我们在伪代码中使用spring EL的规则,将非变量限定在${"1"}中,解析后根据上下文的类型转换为相应的java类型.在规则 ...
- python函数总结
1.函数是一种子程序.程序员使用函数来减少代码重复,并用于组织或模块化程序.一旦定义了函数,它可以从程序中的许多不同位置被多次调用.参数允许函数具有可更改的部分.函数定义中出现的参数称之为形参,函数调 ...
- HTML语法分析
什么是HTML htyper text markup language 即超文本标记语言HTML是一个网页的主体部分,也是一个网页的基础.因为一个网页可以没有样式,可以没有交互,但是必须要有网页需要呈 ...
- LightOJ 1229 Treblecross(SG函数打表 + 遍历)题解
题意:给你一串含“.”和“X”的字串,每次一个玩家可以把‘."变成“X”,谁先弄到三个XXX就赢.假如先手必赢,输出所有能必赢的第一步,否则输出0. 思路:显然如果一个X周围两格有X那么肯定 ...