https://my.oschina.net/uvwxyz/blog/182224
1.DHT简介
GlusterFS使用算法进行数据定位,集群中的任何服务器和客户端只需根据路径和文件名就可以对数据进行定位和读写访问。换句话说,GlusterFS不需要将元数据与数据进行分离,因为文件定位可独立并行化进行。GlusterFS中数据访问流程如下:
1) 计算hash值,输入参数为文件路径和文件名;
2) 根据hash值在集群中选择子卷(存储服务器),进行文件定位;
3) 对所选择的子卷进行数据访问。
2.DHT源码流程分析
2.1正常流程
2.1.1创建目录
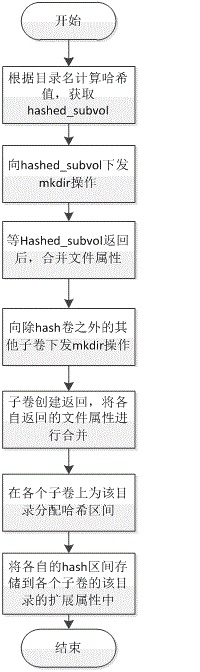
创建目录的主要步骤有:
1) 根据目录名计算哈希值,由其哈希值所在的hash区间确定hashed卷。
2) 向hashed卷下发mkdir操作。
3) 待hashed卷返回后,再向除hashed卷之外的所有子卷下发mkdir操作。
4) 待所有子卷均返回后,合并目录属性。
5) 为每个子卷在该目录上分配hash区间。
6) 将各自的hash区间写入子卷上该目录的扩展属性中。
7) 创建目录结束。
其流程如下图所示:
2.1.2创建文件
创建文件的主要步骤有:
1) 根据文件名计算hash值,根据父目录hash分布获取其hashed卷。
2) 若hashed卷空间,inode数目等没有超过上限,则直接在hashed卷创建该文件。
3) 若hashed卷空间,inode数目等超过了上限,则在子卷中选择一个最优的作为其avail卷。
4) 在hashed卷上创建DHTLINKFILE,其扩展属性中记录着avail卷的名字。
5) 在avail卷上创建该文件。
6) 创建文件结束。
其流程如下图所示:
2.1.3打开文件
Open文件的主要步骤有:
1) 向其cached卷下发open操作(在open前会调用lookup获取其cached卷)。
2) 若open成功,则将文件fd等信息返回,open操作完成(如果失败且返回的错误码是不存在,也会直接返回)。
3) 若open失败后会重新获取dst_node(因为有可能处于数据迁移第二阶段)。
4) 向重新获取dst_node在此下发open。
5) 若失败,返回错误码。
6) 若成功,将fd等返回上层,open操作完成。
其流程如下图所示:
2.1.4读取文件
读取文件的主要流程有:
1) 向cached卷下发read操作。
2) 若读取成功且该文件未处于数据迁移第二阶段,则将读取数据返回,此次读取结束。
3) 若读取成功但该文件处于数据迁移第二阶段,则会重新获取目标卷,再次下发read操作。
4) 若失败且错误码是ENOENT,则直接返回错误码。
5) 若失败或该文件处于数据迁移第二阶段,则会重新获取目标卷,再次下发read操作。
6) 第二次读取,若成功则将数据返回,若读取失败,将错误码返回。
7) 此次读取操作结束。
其流程如下图所示:

2.1.5写入文件
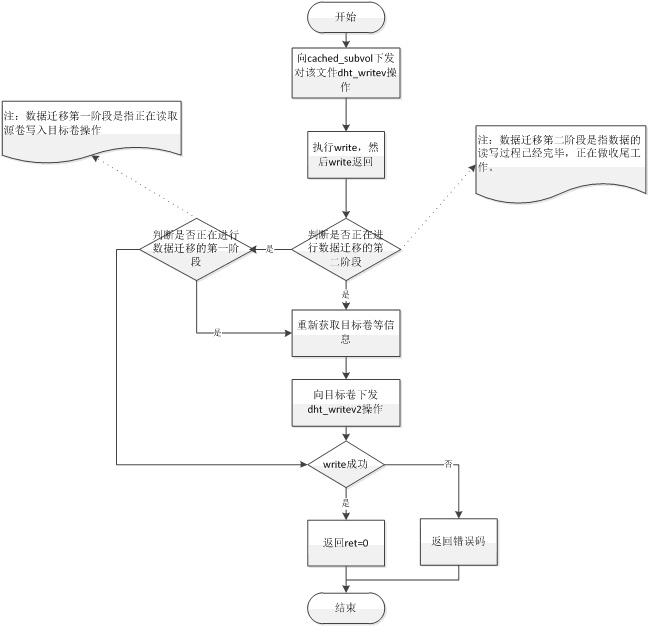
向文件写入数据的主要流程有:
1) 向cached卷下发write命令。
2) 待返回,若正处于数据迁移第二阶段,重新获取目标卷等信息,再次下发write命令。
3) 若正处于数据迁移第一阶段,重新获取目标卷等信息,在次下发write命令。
4) 将返回值等返回给上层(若有第二次write,将第二次write的返回值等返回给上层)。
写入数据的流程如下图所示:
2.1.6读取目录
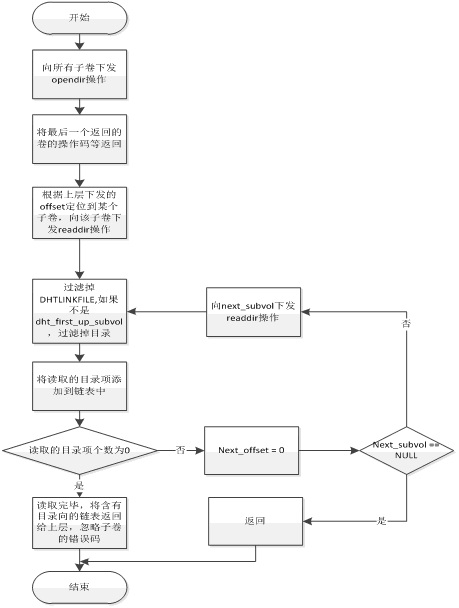
读取目录项主要流程有:
1) 向所有子卷下发opendir操作。
2) 只将最后一个返回的返回值返回。
3) 根据上层readdir中offset定位到某个子卷,向该子卷下发readdir操作。
4) 将该子卷读取的目录项进行过滤(过滤DHTLINKFILE,若不是first_up_subvol,也将目录过滤掉),将读取的目录项返回。
5) 若该子卷读取的目录项过滤后个数为0且next_offset != 0,说明该subvol尚未读完,则继续向该subvol下发readdir操作。
6) 若该子卷读取的目录项过滤后个数为0但next_offset == 0,说明该subvol已经读完,则向next_subvol下发readdir操作。
7) 如果next_subvol不为空,则next_subvol下发readdir操作返回后,重复执行步骤4)的操作。
8) 如果next_subvol为空,说明该目录内的所有项以读取完毕。
注:上述中若count = 0但next_offset != 0,说明此次读取的目录项中均为目录和DHTLINKFILE,全部被过滤掉,所以count = 0。
读取目录的流程如图所示:
2.1.7lookup
Lookup操作的主要流程有:
1) 根据name获取其hash卷。
2) 若不是第一次查询且是目录,则向所有子卷下发lookup操作,比对与inode中的信息是否一致,若不一致则更新。
3) 若不是第一次查询但不是目录,则向cached下发lookup操作,若不存在,则需调用dht_lookup_everywhere.,找到后为其创建DHTLINKFILE。
4) 若是第一次查询且是目录,则会向其hashed卷下发lookup操作,然后再向其它子卷下发lookup操作,合并后返回。
5) 若是第一次查询但不是目录,则会向其hashed卷下发lookup操作,若返回的是DHT_LINKFILE,则还有向其cached卷下发lookup操作,将其属性返回。
Lookup操作的流程如下图所示:
2.2特殊处理
2.2.1添加卷后lookup
添加卷后lookup的主要流程有:
1) 执行添加卷命令后,将会重新初始化。
2) lookup目录时,待各个子卷将目录信息返回后,都会调用dht_layout_merge(),将各个子xlator指针,返回值等添加到layout中。
3) 然后调用dht_layout_normalize时,新添加的list.err(start=stop=0,在检测是否有空洞和重叠时已按hash区间排序,所以新添加的卷没有空洞和重叠)会被置为ENOENT。
4) 所以dht_layout_normalize返回!=0,然后进入目录修复。
5) 会调用dht_selfheal_dir_mkdir在新添加的卷上创建该目录setattr(该目录没有分布区间信息,所以不需要setxattr)。
6) 最后调用dht_selfheal_dir_finish结束。
注:再次lookup时,在dht_layout_normalize中因为layout->list.err < 0(err ==-1),所有该函数返回0(第一次该函数会返回ret>0),不会触发目录修复动作。
2.2.2后端手动添加文件
在后端手动添加文件后,再执行ls操作,其主要流程有:
1) readdir时,其父目录会将该目录项返回给上层。
2) 然后对该文件进行lookup。
3) 若通过hashed_subvol直接定位到了该文件,则将该文件属性返回给上层。
4) 若没有,则会lookup_everywhere,找到该文件,然后将该文件作为其cached_subvol,并创建hashed_subvol到cached_subvol的链接文件。
2.2.3后端手动添加目录
后端手动添加目录后,执行ls操作,其主要流程有:
1) 若该新添加的目录不是位于first_up_subvol,则该目录向在其父目录readdir时会被过滤,即在挂载点不会看到你新添加的目录。
2) 若新添加的目录位于first_up_subvol,则在readdir父目录时会向将该目录项返回给上层。
3) 然后对该目录项进行lookup,在其hashed_subvol找到该目录的话,执行looku_directory(各个卷查找该目录)。若找不到,则会执行lookup_everywhere.
4) 在lookup_diectory后,若需要修复,则在各子卷创建该目录,并分配hash区间。
5) 在lookup_everywhere时,找到该目录,然后再执行looku_directory.
2.2.4修复目录layout
修复目layout的主要流程有:
1) 重新分配hash区间,hash区间按子卷个数划分,优先分配与原区间重叠最大的区间段。
2) 将重新分配的hash区间,存储到其扩展属性中。
2.2.5数据迁移
数据迁移的主要流程有:
1) 首先lookup该目录。
2) 遍历该目录下的DHT_LINKFIFE.
3) 如果该文件实际就是符号链接,则根据源文件信息在to上建立该符号链接,如果是设备文件,在to上mknode。然后将源文件unlink
4) 如果是普通文件,则在其hash卷上create该文件。
5) 然后打开源文件。
6) 检测是否含有空洞文件。
7) 进行读写。
8) 读写完毕后,move扩展属性。
9) unlink源文件,truncate,然后清楚标志位等。
10) 迁移该文件结束。
3.结束
- greenplum分布键的hash值计算分析
greenplum 数据分布策略 greenplum 是一个 MPP 架构的数据库,由一个 master 和多个 segment 组成(还可选配置一个 standby master),其数据会根据设置 ...
- Hadoop源代码分析
http://wenku.baidu.com/link?url=R-QoZXhc918qoO0BX6eXI9_uPU75whF62vFFUBIR-7c5XAYUVxDRX5Rs6QZR9hrBnUdM ...
- Hadoop源代码分析(完整版)
Hadoop源代码分析(一) 关键字: 分布式云计算 Google的核心竞争技术是它的计算平台.Google的大牛们用了下面5篇文章,介绍了它们的计算设施. GoogleCluster:http:// ...
- 转:RTMPDump源代码分析
0: 主要函数调用分析 rtmpdump 是一个用来处理 RTMP 流媒体的开源工具包,支持 rtmp://, rtmpt://, rtmpe://, rtmpte://, and rtmps://. ...
- RTMPdump(libRTMP)源代码分析 4: 连接第一步——握手(Hand Shake)
===================================================== RTMPdump(libRTMP) 源代码分析系列文章: RTMPdump 源代码分析 1: ...
- LIRe 源代码分析 7:算法类[以颜色布局为例]
===================================================== LIRe源代码分析系列文章列表: LIRe 源代码分析 1:整体结构 LIRe 源代码分析 ...
- Cocos2d-x 源代码分析 : Scheduler(定时器) 源代码分析
源代码版本号 3.1r,转载请注明 我也最终不out了,開始看3.x的源代码了.此时此刻的心情仅仅能是wtf! !!!!!!! !.只是也最终告别CC时代了. cocos2d-x 源代码分析文件夹 h ...
- HBase源代码分析之HRegionServer上MemStore的flush处理流程(一)
在<HBase源代码分析之HRegion上MemStore的flsuh流程(一)>.<HBase源代码分析之HRegion上MemStore的flsuh流程(二)>等文中.我们 ...
- OpenStack_Swift源代码分析——Ring的rebalance算法源代码具体分析
1 Command类中的rebalnace方法 在上篇文章中解说了,创建Ring已经为Ring加入设备.在加入设备后须要对Ring进行平衡,平衡 swift-ring-builder object.b ...
随机推荐
- Texas Instruments matrix-gui-2.0 hacking -- run_script.php
<?php /* * Copyright (C) 2011 Texas Instruments Incorporated - http://www.ti.com/ * * * Redistrib ...
- 【opencv基础】detectMultiScale-output detection score
前言 使用FDDB数据库评估人脸检测的效果时,需要计算人脸区域的得分,具体问题请参考FDDB-FAQ. 实现过程 根据here和here的描述,可以使用cascade.detectMultiScale ...
- Softmax回归介绍
把输入值当成幂指数求值,再正则化这些结果值.这个幂运算表示,更大的证据对应更大的假设模型(hypothesis)里面的乘数权重值.反之,拥有更少的证据意味着在假设模型里面拥有更小的乘数系数.假设模型里 ...
- [LeetCode&Python] Problem 832. Flipping an Image
Given a binary matrix A, we want to flip the image horizontally, then invert it, and return the resu ...
- JPQL详解
JPA在说jpql之前必须要说一下什么是JPA,否则在后续学习的时候,你会弄混的.JPA是一种规范,什么是规范呢,规范就是一个钥匙可以开这把锁.一般对于规范来说我们都是用接口,如果有人要我们则实现我们 ...
- sql server CLR
1. 配置sql server 启用CLR 在SQL Server2005/2008里面,CLR默认是关闭的.可以使用如下SQL语句开启CLR. sp_configure 'show advanced ...
- 使用ioctl获取网卡统计信息
ethtool -S获取接口统计信息总共分三步: 1.获取统计项个数,使用SIOCETHTOOL+ETHTOOL_GSSET_INFO 2.(可选)获取统计项名字,使用SIOCETHTOOL+ETHT ...
- SQL Server系统表介绍与使用
关于SQL Server数据库的一切信息都保存在它的系统表格里.我怀疑你是否花过比较多的时间来检查系统表格,因为你总是忙于用户表格.但是,你可能需要偶尔做一点不同寻常的事,例如数据库所有的触发器.你可 ...
- ThinkPHP 5 中的 composer.json
本篇并不是揭 ThinkPHP 5 的问题. 只是通过 composer.json 来学习 compoer.json 元旦那天, ThinkPHP 5.1 正式发布,值得庆祝. 之后的第二天有人反馈 ...
- tomcat源码阅读之过滤器
一.Servlet过滤器: 1.介绍: Servlet过滤器本身并不生成请求和响应对象,它只提供过滤作用. Servlet过滤器能够在Servlet被调用之前检查Request对象,修改Request ...