大数据之路Week10_day04 (Hbase的二级索引,二级索引的本质就是建立各列值与行键之间的映射关系)
二级索引的本质就是建立各列值与行键之间的映射关系
HBASE是在hadoop之上构建非关系型,面向列存储的开源分布式结构化数据存储系统。
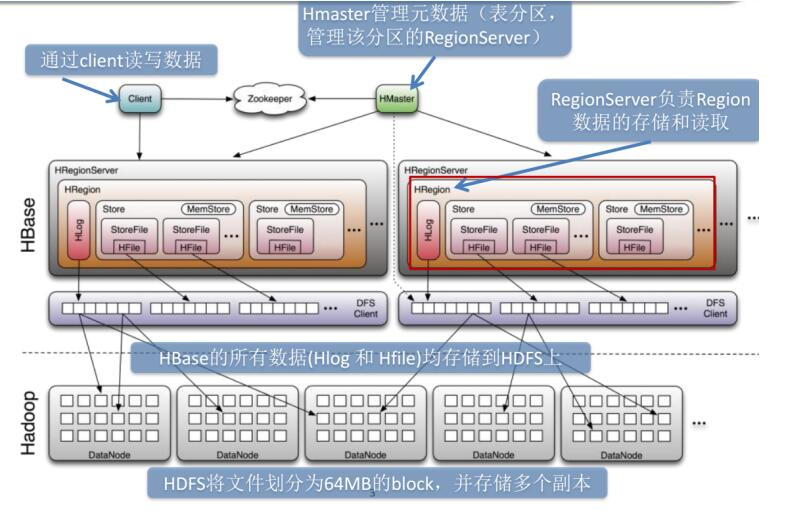
Hbase的局限性:
HBase本身只提供基于行键和全表扫描的查询,而行键索引单一,对于多维度的查询困难。
所以我们引进一个二级索引的概念
常见的二级索引:
HBase的一级索引就是rowkey,我们只能通过rowkey进行检索。如果我们相对hbase里面列族的列列进行一些组合查询,就需要采用HBase的二级索引方案来进行多条件的查询。
1. MapReduce方案
2. ITHBASE(Indexed-Transanctional HBase)方案
3. IHBASE(Index HBase)方案
4. Hbase Coprocessor(协处理器)方案
5. Solr+hbase方案
6. CCIndex(complementalclustering index)方案
二级索引的种类
1、创建单列索引
2、同时创建多个单列索引
3、创建联合索引(最多同时支持3个列)
4、只根据rowkey创建索引
单表建立二级索引
1.首先disable ‘表名’
2.然后修改表 alter 'LogTable',METHOD=>'table_att','coprocessor'=>'hdfs:///写好的Hbase协处理器(coprocessor)的jar包名|类的绝对路径名|1001' 3. enable '表名'
二级索引的设计思路

二级索引的本质就是建立各列值与行键之间的映射关系
如上图1,当要对F:C1这列建立索引时,只需要建立F:C1各列值到其对应行键的映射关系,如C11->RK1等,这样就完成了对F:C1列值的二级索引的构建,当要查询符合F:C1=C11对应的F:C2的列值时(即根据C1=C11来查询C2的值,图1青色部分)
其查询步骤如下:
1. 根据C1=C11到索引数据中查找其对应的RK,查询得到其对应的RK=RK1
2. 得到RK1后就自然能根据RK1来查询C2的值了 这是构建二级索引大概思路,其他组合查询的联合索引的建立也类似。
Mapreduce的方式创建二级索引
使用整合MapReduce的方式创建hbase索引。主要的流程如下:
1.1扫描输入表,使用hbase继承类TableMapper
1.2获取rowkey和指定字段名称和字段值
1.3创建Put实例, value=” “, rowkey=班级,column=学号
1.4使用IdentityTableReducer将数据写入索引表
实例:
1、在hbase中创建索引表 student_index
create 'student_index','info'
2、编写mapreduce代码
package com.wyh.Hbase_MR; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job; import java.io.IOException; /**
* 建立索引表
*
*/ public class HbaseToIndex { /**
* Map段 将读取到的数据,设置班级+学号当作key
*/
public static class IndexMap extends TableMapper<Text,NullWritable>{
@Override
protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException { String id = Bytes.toString(key.get());
String clazz = Bytes.toString(value.getValue("info".getBytes(), "clazz".getBytes())); String key1 = id+"_"+clazz;
context.write(new Text(key1),NullWritable.get()); }
} /**
* Reduce段 获取Map传过来的key
*/
public static class IndexReduce extends TableReducer<Text,NullWritable,NullWritable>{
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
String[] split = key.toString().split("_");
String id = split[0];
String clazz = split[1]; Put put = new Put(clazz.getBytes());
put.add("info".getBytes(),id.getBytes(),"".getBytes()); context.write(NullWritable.get(),put);
}
} public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum","master:2181,node1:2181,node2:2181"); Job job = Job.getInstance(conf);
job.setJobName("HbaseToIndex");
job.setJarByClass(HbaseToIndex.class); Scan scan = new Scan();
scan.addFamily("info".getBytes()); TableMapReduceUtil.initTableMapperJob("students",scan,IndexMap.class,Text.class,NullWritable.class,job);
TableMapReduceUtil.initTableReducerJob("student_index",IndexReduce.class,job); job.waitForCompletion(true); }
}
3、打成jar包上传到hadoop中运行
hadoop jar hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar com.wyh.Hbase_MR.HbaseToIndex
4、编写查询代码,测试结果
package com.wyh.Hbase_MR; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import org.junit.After;
import org.junit.Before;
import org.junit.Test; import java.io.IOException;
import java.util.ArrayList;
import java.util.List; public class OpIndex {
private Configuration conf;
private HConnection connection;
private HBaseAdmin admin; /**
* 连接到Hbase
*/
@Before
public void Cline(){ try { conf = new Configuration();
conf.set("hbase.zookeeper.quorum","master:2181,node1:2181,node2:2181");
connection = HConnectionManager.createConnection(conf);
admin = new HBaseAdmin(conf);
System.out.println("建立连接成功。。。"+connection); } catch (IOException e) {
e.printStackTrace();
}
} /**
* 通过索引表进行查询数据
*/
@Test
public void scanData(){
try {
//创建一个集合存放查询到的学号
ArrayList<Get> gets = new ArrayList<>(); //获取到索引表
HTableInterface student_index = connection.getTable("student_index");
Get get = new Get("理科二班".getBytes());
Result result = student_index.get(get);
List<Cell> cells = result.listCells();
for (Cell cell : cells) {
String id = Bytes.toString(CellUtil.cloneQualifier(cell)); gets.add(new Get(id.getBytes()));
} //获取到学生表
HTableInterface students = connection.getTable("students"); Result[] results = students.get(gets); for (Result result1 : results) {
String id = Bytes.toString(result1.getRow());
String name = Bytes.toString(result1.getValue("info".getBytes(), "name".getBytes()));
String age = Bytes.toString(result1.getValue("info".getBytes(), "age".getBytes()));
String gender = Bytes.toString(result1.getValue("info".getBytes(), "gender".getBytes()));
String clazz = Bytes.toString(result1.getValue("info".getBytes(), "clazz".getBytes())); System.out.println(id+"\t"+name+"\t"+age+"\t"+gender+"\t"+clazz);
} } catch (IOException e) {
e.printStackTrace();
} } @After
public void Close(){
if(admin!=null){
try {
admin.close();
System.out.println("admin已经关闭。。。。");
} catch (IOException e) {
e.printStackTrace();
}
} if(connection!=null){
try {
connection.close();
System.out.println("connection已经关闭。。。。");
} catch (IOException e) {
e.printStackTrace();
}
} }
}
运行结果:

大数据之路Week10_day04 (Hbase的二级索引,二级索引的本质就是建立各列值与行键之间的映射关系)的更多相关文章
- 大数据学习系列之—HBASE
hadoop生态系统 zookeeper负责协调 hbase必须依赖zookeeper flume 日志工具 sqoop 负责 hdfs dbms 数据转换 数据到关系型数据库转换 大数据学习群119 ...
- MongoDB 大数据技术之mongodb中在嵌套子文档的文档上面建立索引
一.给collection objectid赋自定义的值 MongoDB Enterprise > db.testid.insert({_id:{imsi:"4567890123&qu ...
- 胖子哥的大数据之路(6)- NoSQL生态圈全景介绍
引言: NoSQL高级培训课程的基础理论篇的部分课件,是从一本英文原著中做的摘选,中文部分参考自互联网.给大家分享. 正文: The NoSQL Ecosystem 目录 The NoSQL Eco ...
- 大数据时代数据库-云HBase架构&生态&实践
业务的挑战 存储量量/并发计算增大 现如今大量的中小型公司并没有大规模的数据,如果一家公司的数据量超过100T,且能通过数据产生新的价值,基本可以说是大数据公司了 .起初,一个创业公司的基本思路就是首 ...
- 大数据核心知识点:Hbase、Spark、Hive、MapReduce概念理解,特点及机制
今天,上海尚学堂大数据培训班毕业的一位学生去参加易普软件公司面试,应聘的职位是大数据开发.面试官问了他10个问题,主要集中在Hbase.Spark.Hive和MapReduce上,基础概念.特点.应用 ...
- 大数据-05-Spark之读写HBase数据
本文主要来自于 http://dblab.xmu.edu.cn/blog/1316-2/ 谢谢原作者 准备工作一:创建一个HBase表 这里依然是以student表为例进行演示.这里假设你已经成功安装 ...
- 胖子哥的大数据之路(7)- 传统企业切入核心or外围
一.引言 昨天和一个做互联网大数据(零售行业)的朋友交流,关于大数据传统企业实施的切入点产生了争执,主要围绕两个问题进行了深入的探讨: 问题1:对于一个传统企业而言什么是核心业务,什么是外围业务? 问 ...
- 胖子哥的大数据之路(四)- VisualHBase功能需求框架
一.引言 大数据在结构化数据存储方面的应用需求越来越明确,但是大数据环境下辅助开发工具的不完善,给数据库管理人员和开发人员带来的不变难以言表,基于此创建了开源项目VisualHBase,同时创建了Vi ...
- 大数据之路week06--day07(Hadoop生态圈的介绍)
Hadoop 基本概念 一.Hadoop出现的前提环境 随着数据量的增大带来了以下的问题 (1)如何存储大量的数据? (2)怎么处理这些数据? (3)怎样的高效的分析这些数据? (4)在数据增长的情况 ...
- 大数据之路week04--day06(I/O流阶段一 之异常)
从这节开始,进入对I/O流的系统学习,I/O流在往后大数据的学习道路上尤为重要!!!极为重要,必须要提起重视,它与集合,多线程,网络编程,可以说在往后学习或者是工作上,起到一个基石的作用,没了地基,房 ...
随机推荐
- java double转string去除科学计数法"E" 非tostring()和valueOf()
在遇到需要将double类型转换string类型时,会出现转成科学计数法的形式,希望字符串能原样输出.直接使用会报java.lang.Double cannot be cast to java.lan ...
- [Symfony\Component\Process\Exception\RuntimeException] The Process class relies on proc_open, which is not available on your PHP installation.
[Symfony\Component\Process\Exception\RuntimeException] The Process class relies on proc_open, which ...
- NET6使用AutoFac依赖注入(仓储模式)
第一次使用autofac,然后net6最新长期支持的,就想着在net6的基础上使用autofac,我对依赖注入理解很差,一知半解的搞了好久.好在有了一点点的头绪,记录下省的以后忘记(突然发现自己以前用 ...
- 【Windows】终端配置代理
Windows cmd 设置代理 设置 HTTP 代理: set http_proxy=http://127.0.0.1:7890 & set https_proxy=http://127.0 ...
- BOF编写-修改时间戳
模板配置 跟着网上的教程使用evilashz师傅的模板,下载模板解压至vs的模板目录: %UserProfile%\Documents\Visual Studio 2022\Templates\Pro ...
- RPA_Robocorp
一.RCC使用(https://robocorp.com/docs/rcc/workflow) 1. Creat a new bot : rcc create my-robot 2. Adding ...
- 【译】在分析器中使用 Meter Histogram(直方图)解锁见解
您是否正在与应用程序中的性能瓶颈作斗争?不要再观望了!Visual Studio 2022 在其性能分析套件中引入了 Meter Histogram(直方图)功能,为您提供了前所未有的分析和可视化直方 ...
- 第三章 (Nginx+Lua)Redis/SSDB安装与使用
目前对于互联网公司不使用Redis的很少,Redis不仅仅可以作为key-value缓存,而且提供了丰富的数据结果如set.list.map等,可以实现很多复杂的功能:但是Redis本身主要用作内存缓 ...
- CV高手是怎么炼成的?
你平时都怎么复制粘贴的?是否每次都是复制一段粘贴一段?是否厌倦了每次只能复制粘贴一次的限制?那这篇文章就是为你量身订做的. CopyQ简介 CopyQ is clipboard manager – a ...
- Oracle 遍历游标的四种方式汇总(for、fetch、while、BULK COLLECT)
本文原创:https://www.cnblogs.com/Marydon20170307/p/12869692.html 感谢博主分享 注意:原文中方式四FORALL处有语法错误,应该使用FOR. 1 ...