ChatBI≠NL2SQL:关于问数,聊聊我踩过的坑和一点感悟
"如果说数据是新时代的石油,智能问数就是能让普通人也能操作的智能钻井平台。"
这里是**AI粉嫩特攻队!** ,这段时间真的太忙了,不过放心,关于从零打造AI工具的coze实操下篇正在进行中。今天,我们先聊聊另一个很热闹的主题——ChatBI。
还记得那些陷入Excel地狱的日子吗?当同事问你"上个季度我们的销售增长率是多少",你只能叹口气,打开庞大的数据库,编写一段复杂的SQL语句,然后祈祷没有出错——这个过程通常需要半小时甚至更长时间。
而今天,这个问题的答案可能只需几秒钟。
当大语言模型遇上数据分析:一场静悄悄的革命
最近因为工作关系,我深入研究了智能问数产品(业内称为ChatBI)的开发过程。这种产品让人有种"最亲密的陌生人"的感觉——几乎所有人都听说过微软的Power BI,但真正理解其革命性的人却寥寥无几。
从微软的Power BI到现在基于大语言模型(LLM)的智能BI,技术已经经历了几次重大变革。现在有了Coze、Dify这类快速搭建工作流的工具,智能BI的搭建门槛已经大幅降低(曾试过在几小时内就搭建出来一个简易并可执行的应用,那刹那觉得自己很行)。
但别被表面的简单所迷惑——如何做得好用、做得准确,却不是简单的工作流就能解决的问题。这也是现存几乎所有ChatBI产品的痛点。
智能问数的本质:为什么我们需要它?
在深入技术细节前,我们需要思考一个根本问题:人类为什么要开发BI工具?
本质上,我们期望借助真实的数据指标来支持决策者做出更好的判断。而经历了这么多技术变革,原因有二:
- 这些冰冷的数字是最客观反映事物真实进展的方式,几乎每个决策者都在"对着数字说话"
- 在这个快速发展的社会中,易用、高效、智能已经成为了基本需求
插句题外话:当我们在快速追赶时代的脚步时,不妨在某些时刻让自己慢下来,思考我们追逐的究竟是什么。我很喜欢一句话:"到底是什么样的追求,让你把沿途风景都错过?"
揭秘:ChatBI产品背后的技术架构
现在市面上的ChatBI产品技术架构可以说是百花齐放,我常惊叹那些先行者他们的判断与布局。总结起来,一个完整的技术架构通常包含这几个核心部分:用户交互、意图理解、数据执行、数据治理、以及越来越成为一种趋势的知识运营或者说知识沉淀(第一次从大神那听到“知识运营”的时候,那种震撼是无法描述的,真的很崇敬这些热爱思考的先行者)。
1. 用户交互:第一印象决定生死
作为研发人员,我曾经严重低估了前端设计的重要性。然而,用户交互设计决定了产品是否好用,是否能满足用户需求。
有一个重要的认知突破是:界面设计不应局限于传统的报表、大屏和指标报告。任何能够帮助决策者做出判断的形式都是有价值的。我们甚至可以让业务系统"自己解释自己"。下面是Sugar BI做的特色企业大屏模版,我第一次看的时候还是有种耳目一新的感觉的。
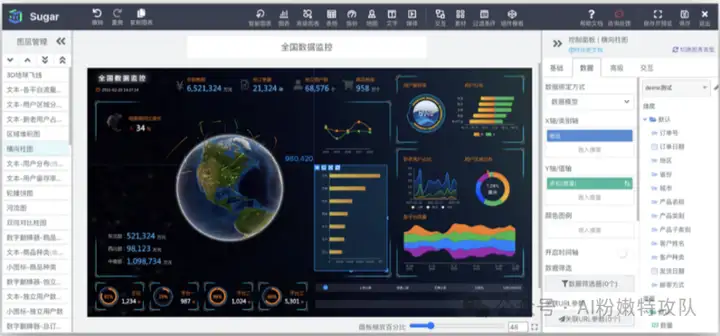
Sugar BI的特色企业大屏:打破传统数据展示的桎梏
除了与最终用户的交互外,还有一个常被忽视的环节:与运营/业务人员的交互。如何引导他们简单快捷地对数据进行治理和解释说明,这同样至关重要。
2. 语义理解:产品能力的分水岭
这是各产品能力的真正分水岭,也是保证问数产品准确度的关键环节。你是否遇到过这些问题?
- "为什么这个指标大模型总是不理解?"
- "这个商品名称为什么每次都搜不对?"
- "产品为什么总是不理解我的问题?"
- "同样是用户增长,市场部和研发部门的计算还不一样…"
在研发过程中,这些问题确实让我伤透了脑筋。自己开发的东西那一刻就像是个陌生人一样与我对坐,就像在说你倒是加把劲儿啊。
那就撸起袖子来挨个攻克吧,被难倒总不是咱们研发人员的宿命。这后面的抽象问题其实是语义模糊、实体难对齐、术语/黑话理解苦难、指标计算太复杂。
核心策略:我是从建立专有知识库这一点入手的,如果说术语或者指标难理解,那就建立相应的术语库与指标库,对用户的查询进行相关知识的检索。将检索得到的知识(甚至包括SQL)提交给大模型作为背景知识,去提升推理的效果。
从我的实验来看,这种方法带来的提升非常显著,而且维护成本并不高(因为大多数业务系统中已经包含了许多指标的计算逻辑)。
3. 数据执行:技术人员的主战场
这通常是技术人员最爱发力的环节。不计其数的NL2SQL(自然语言转SQL)、NL2XX的研究文献就可见一斑。
数据执行环节通常包括查询生成、查询语句纠错和查询语句执行等部分。目前主流的技术方案有:
- NL2SQL
查询效率高,准确度较高,但在处理复杂嵌套子查询时存在局限 - NL2Python
灵活性强,但实现复杂 - NL2DSL
特定领域语言转换,针对性强 - NL2API
灵活性极高,可容纳复杂计算逻辑,但自然语言到API参数的映射过程复杂 - NL2MDX
微软查询风格,适合多维数据分析
通用的NL2SQL准确度已经相当高,但面对企业内部的专业术语和复杂指标计算时,效果往往大打折扣。这也是为什么我们需要将语义理解与数据执行深度结合的原因。
4. 数据治理:老生常谈却至关重要
我认为,做数据治理的企业天然具有开发智能问数产品的优势。因为这些企业不仅懂数据,更懂业务,这一点至关重要。
在数据治理环节,我经常问自己这些问题:
- 数据安全如何保证?
- 用户权限如何管理?
- 基于智能问数的数据标准如何建立?
- 数据从输入到输出,整个环节如何监控?
数据治理不是一次性工作,而是持续的过程。它直接决定了智能问数产品的质量上限。
5. 知识沉淀:产品的核心竞争力
随着DeepSeek的推出,现在越来越多的声音提倡建立个人知识库。其实产品也是一样,专属的知识库是一种财富,是产品的沉淀。做了这么多产品,我们留下了什么,如何持续的优化升级保持动力。我想知识沉淀部分就是答案。
万物可入知识库,只要它有价值:术语说明、专有指标、算法专家经验都可以作为知识沉淀下来,并加以复用。而知识运营更是一个庞大的话题,庞大到企业是否可以在AGI时代不被淘汰。
智能问数产品的现状与未来
现在的问数产品还是饱受诟病的:不到75%的准确率、超过10秒的响应时间会使用户厌烦,从而放弃使用。当我们做产品的时候,我们只是做出来就可以吗?其实每个产品都是一个鲜活的生命,而作为创造者则要为之计深远。我也搜了很多的破局之道,其中一个高人的回答我颇为赞同,那就是有效的数据治理、统一的指标口径以及企业独有的知识库。
写在最后
所有人都在赶路,我们也从不停歇。做难而正确的事情,持精益求精的态度。
科技车轮滚滚向前,你我都是这场革命的见证者。
附两个产品技术架构图让大家也找找感觉。
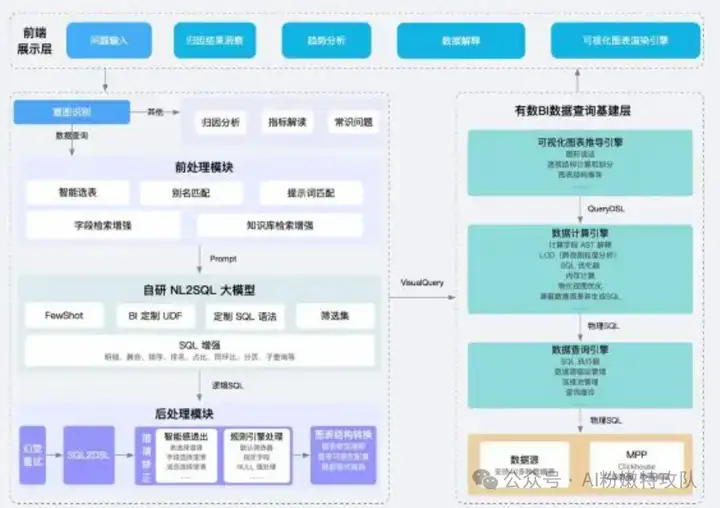
有数BI 技术架构图
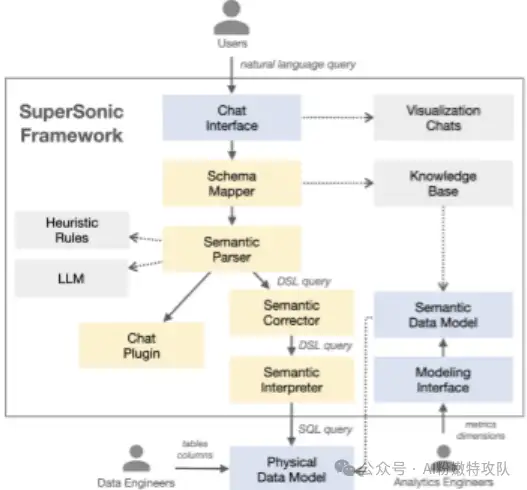
腾讯云BI架构图
这只是我对智能问数产品研发的初步探讨,后续将带来更多与这些问题相关的内容:
- NL2SQL技术的优化与落地
- 提升智能问数准确率的实战技巧
- 面向不同行业的智能问数定制策略
- 如何构建企业专属知识库
- 各ChatBI产品的介绍与对比
- ...
以上,既然看到这里了,如果觉得不错,随手点个赞、分享、推荐三连吧,你的鼓励是我持续创作的动力,我们,下次再见。
AI粉嫩特攻队,内卷不灭,奋斗不止!关注我们,帮你把时间还给创造!
| 作者:冬阳,AI粉嫩特攻队员之一,资深AI产品研发工程师,专注于智能BI与数据分析领域,曾参与多个企业级智能问数产品的设计与开发。
| 互动交流,请联系邮箱:fennenqiushui@qq.com
ChatBI≠NL2SQL:关于问数,聊聊我踩过的坑和一点感悟的更多相关文章
- 工作总结:kafka踩过的坑
餐饮系统每天中午和晚上用餐高峰期,系统的并发量不容小觑.公司规定各部门都要轮流值班,防止出现线上问题时能够及时处理. 后厨显示系统属于订单的下游业务. 用户点完菜下单后,订单系统会通过发 Kafka ...
- 使用ffmpeg视频编码过程中踩的一个坑
今天说说使用ffmpeg在写视频编码程序中踩的一个坑,这个坑让我花了好多时间,回头想想,非常多时候一旦思维定势真的挺难突破的.以下是不对的编码结果: ...
- 《C++之那些年踩过的坑(三)》
C++之那些年踩过的坑(三) 作者:刘俊延(Alinshans) 本系列文章针对我在写C++代码的过程中,尤其是做自己的项目时,踩过的各种坑.以此作为给自己的警惕. [版权声明]转载请注明原文来自:h ...
- 《C++之那些年踩过的坑(附录一)》
C++之那些年踩过的坑(附录一) 作者:刘俊延(Alinshans) 本系列文章针对我在写C++代码的过程中,尤其是做自己的项目时,踩过的各种坑.以此作为给自己的警惕. [版权声明]转载请注明原文来自 ...
- Pro Flight YOKE 设备键位映射踩过的坑
背景 VR游戏项目.街机游戏项目7月阶段版本快要结束了,考虑到带有键鼠外设显得逼格比较Low,所以决定采用"高大上"的专业设备来进行游戏操作. 需求 需要将键盘鼠标操作的18个键位 ...
- wrk 使用记录及踩过的坑
wrk是什么?https://github.com/wg/wrk wrk 是一个非常小巧高效的开源性能测试工具,支持lua脚本来创建复杂的测试场景.wrk 的一个很好的特性就是能用很少的线程压出很大的 ...
- 可视化爬虫Portia安装和部署踩过的坑
背景 Scrapy爬虫的确是好使好用,去过scrapinghub的官网浏览一下,更是赞叹可视化爬虫的犀利.scrapinghub有一系列的产品,开源了大部分项目,Portia负责可视化爬虫的编辑,Sp ...
- python抓取360百科踩过的坑!
学习python一周,学着写了一个爬虫,用来抓取360百科的词条,在这个过程中.因为一个小小的修改,程序出现一些问题,又花了几天时间研究,问了各路高手,都没解决,终于还是自己攻克了,事实上就是对lis ...
- 我用select做多路复用踩到的坑
既然说是用select踩到的坑,那么就先直接贴一段使用select的代码上来瞅一下: bool SocketAction(int fd, const char* buf, size_t len, ui ...
- 那些移动端web踩过的坑
原文链接:https://geniuspeng.github.io/2017/08/24/mobile-issues/ 扔了N久,还是捡回来了.好好弄一下吧.刚工作的时候挺忙的,后来不那么忙了,但是变 ...
随机推荐
- 【web】一个自适应的导航栏前端设计(只含HTML+CSS)
上一篇文章:[前端]CSS实现图片文字对齐 并随着设备尺寸改变而改变大小 本文是基于上一篇文章的补充. 效果如下 HTML源码 点击查看HTML代码 <!DOCTYPE html> < ...
- resttemplate的ReadTimeout和ConnectTimeout
问题描述:今天,在做微服务开发中,A服务区调用B服务,获取数据做导出excel操作.A服务出现了"java.net.SocketTimeoutException: Read timed ou ...
- Zstd-数据压缩组件
Zstandard 简称Zstd,是一款快速实时的开源数据压缩程序,由Facebook开发,源码是用C语言编写的.相比业内其他压缩算法(如Gzip.Snappy.Zlib)它的特点是:当需要时,它可以 ...
- Ubuntu终端输入异常、无法退格(删除文本)、使用方向键命令
1 起因 为了学习嵌入式开发安装去安装的ncurses库,使用命令:sudo apt-get install libncurses5-dev导致系统自带的ncurses-base被自动删除. 2 出现 ...
- Pytorch损失函数总结
损失函数 nn.L1Loss 创建一个衡量输入中每个元素之间的平均绝对误差 (MAE) 的标准XX和目标是的是的. nn.MSELoss 创建一个标准,用于测量输入中每个元素之间的均方误差(平方 L2 ...
- 在 Vercel 部署随机图 API
在本文中,将详细介绍如何在 Vercel 平台上部署一个具有分类功能的随机图片 API.通过这个 API,用户可以根据不同的分类获取随机图片链接,并且还可以从所有分类中随机获取一张图片. 项目结构 首 ...
- 认识Token和Cookie
认识Token和Cookie 1.token和cookie有什么区别? 1.1 存储位置及方式:Cookie是浏览器用来存储本地信息的文件,有一定的存储限制,而Token是由服务器按一定算法生成的 ...
- 2024年终总结:5000 Star,10w 下载量,这是我交出的开源答卷
你好,我是 Kagol,个人公众号:前端开源星球. 2024年,我做前端开发工作满10年啦! 这10年我一直在开发前线,做过电商项目.广告平台.项目管理系统等业务,目前主要专注于前端组件库建设和开源社 ...
- C# Windows Media Player 播放playlist 歌单
using AxWMPLib; using System; using System.Collections.Generic; using System.Linq; using System.Text ...
- 【java提高】---细则(4)
java提高(16)---java注解 注解含义注解是JDK1.5之后才有的新特性,它相当于一种标记,在程序中加入注解就等于为程序打上某种标记,之后又通过类的反射机制来解析注解. 一.JDK自带注解 ...