数栈技术分享:用短平快的方式告诉你Flink-SQL的扩展实现
数栈是云原生—站式数据中台PaaS,我们在github和gitee上有一个有趣的开源项目:FlinkX,FlinkX是一个基于Flink的批流统一的数据同步工具,既可以采集静态的数据,也可以采集实时变化的数据,是全域、异构、批流一体的数据同步引擎。大家喜欢的话请给我们点个star!star!star!
github开源项目:https://github.com/DTStack/flinkx
gitee开源项目:https://gitee.com/dtstack_dev_0/flinkx
首先,本文所述均基于flink 1.5.4。
一、我们为什么扩展Flink-SQL?
由于Flink 本身SQL语法并不提供在对接输入源和输出目的的SQL语法。数据开发在使用的过程中需要根据其提供的Api接口编写Source和 Sink, 异常繁琐,不仅需要了解FLink 各类Operator的API,还需要对各个组件的相关调用方式有了解(比如kafka,redis,mongo,hbase等),并且在需要关联到外部数据源的时候没有提供SQL相关的实现方式,因此数据开发直接使用Flink编写SQL作为实时的数据分析时需要较大的额外工作量。
我们的目的是在使用Flink-SQL的时候只需要关心做什么,而不需要关心怎么做。不需要过多的关心程序的实现,专注于业务逻辑。
接下来,我们一起来看下Flink-SQL的扩展实现吧!
二、扩展了哪些flink相关sql
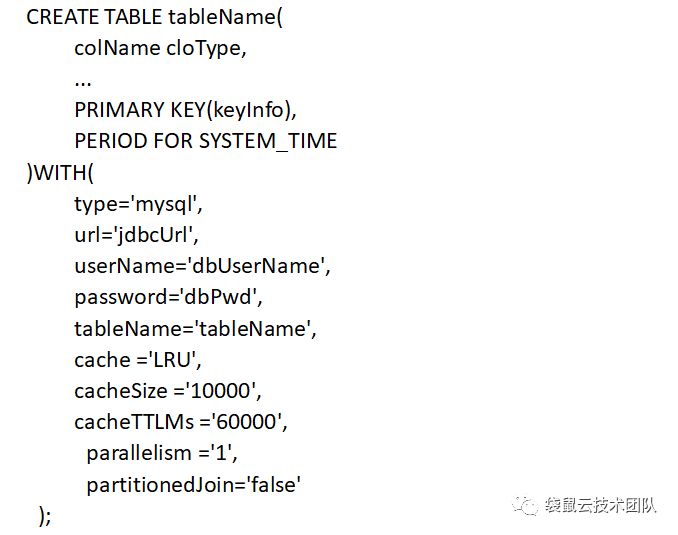
1、创建源表语句
 2、创建输出表语句
2、创建输出表语句

3、创建自定义函数
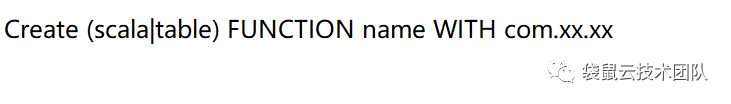
4、维表关联
三、各个模块是如何翻译到flink的实现
1、如何将创建源表的sql语句转换为flink的operator
Flink中表的都会映射到Table这个类。然后调用注册方法将Table注册到environment。
StreamTableEnvironment.registerTable(tableName, table);
当前我们只支持kafka数据源。Flink本身有读取kafka 的实现类, FlinkKafkaConsumer09,所以只需要根据指定参数实例化出该对象。并调用注册方法注册即可。
另外需要注意在flink sql经常会需要用到rowtime, proctime, 所以我们在注册表结构的时候额外添加rowtime,proctime。
当需要用到rowtime的使用需要额外指定DataStream.watermarks(assignTimestampsAndWatermarks),自定义watermark主要做两个事情:1:如何从Row中获取时间字段。 2:设定最大延迟时间。
2、 如何将创建的输出表sql语句转换为flink的operator
Flink输出Operator的基类是OutputFormat, 我们这里继承的是RichOutputFormat, 该抽象类继承OutputFormat,额外实现了获取运行环境的方法getRuntimeContext(), 方便于我们之后自定义metric等操作。
我们以输出到mysql插件mysql-sink为例,分两部分:
- 将create table 解析出表名称,字段信息,mysql连接信息。
该部分使用正则表达式的方式将create table 语句转换为内部的一个实现类。该类存储了表名称,字段信息,插件类型,插件连接信息。
- 继承RichOutputFormat将数据写到对应的外部数据源。
主要是实现writeRecord方法,在mysql插件中其实就是调用jdbc 实现插入或者更新方法。
3、如何将自定义函数语句转换为flink的operator;
Flink对udf提供两种类型的实现方式:
1)继承ScalarFunction
2)继承TableFunction
需要做的将用户提供的jar添加到URLClassLoader, 并加载指定的class (实现上述接口的类路径),然后调用TableEnvironment.registerFunction(funcName, udfFunc);即完成了udf的注册。之后即可使用改定义的udf;
4、维表功能是如何实现的?
流计算中一个常见的需求就是为数据流补齐字段。因为数据采集端采集到的数据往往比较有限,在做数据分析之前,就要先将所需的维度信息补全,但是当前flink并未提供join外部数据源的SQL功能。
实现该功能需要注意的几个问题:
1)维表的数据是不断变化的
在实现的时候需要支持定时更新内存中的缓存的外部数据源,比如使用LRU等策略。
2)IO吞吐问题
如果每接收到一条数据就串行到外部数据源去获取对应的关联记录的话,网络延迟将会是系统最大的瓶颈。这里我们选择阿里贡献给flink社区的算子RichAsyncFunction。该算子使用异步的方式从外部数据源获取数据,大大减少了花费在网络请求上的时间。
3)如何将sql 中包含的维表解析到flink operator
为了从sql中解析出指定的维表和过滤条件, 使用正则明显不是一个合适的办法。需要匹配各种可能性。将是一个无穷无尽的过程。查看flink本身对sql的解析。它使用了calcite做为sql解析的工作。将sql解析出一个语法树,通过迭代的方式,搜索到对应的维表;然后将维表和非维表结构分开。

通过上述步骤可以通过SQL完成常用的从kafka源表,join外部数据源,写入到指定的外部目的结构中。
数栈技术分享:用短平快的方式告诉你Flink-SQL的扩展实现的更多相关文章
- 技本功丨用短平快的方式告诉你:Flink-SQL的扩展实现
2019年1月28日,阿里云宣布开源“计算王牌”实时计算平台Blink回馈给ApacheFlink社区.官方称,计算延迟已经降到毫秒级,也就是你在浏览网页的时候,眨了一下眼睛,淘宝.天猫处理的信息已经 ...
- Molecule实现数栈至简前端开发新体验
Keep It Simple, Stupid. 这是开发人耳熟能详的 KISS 原则,也像是一句有调侃意味的善意提醒,提醒每个前端人,简洁易懂的用户体验和删繁就简的搭建逻辑就是前端开发的至简大道. 这 ...
- 感知开源的力量-APICloud Studio开源技术分享会
2014.9.15 中国领先的“云端一体”移动应用云服务提供商APICloud正式发布2015.9.15,APICloud上线一周年,迎来第一个生日这一天,APICloud 举办APICloud St ...
- 技术分享 | 在MySQL对于批量更新操作的一种优化方式
欢迎来到 GreatSQL社区分享的MySQL技术文章,如有疑问或想学习的内容,可以在下方评论区留言,看到后会进行解答 作者:景云丽.卢浩.宋源栋 GreatSQL社区原创内容未经授权不得随意使用,转 ...
- UWA 技术分享连载 转载
技术分享连载1 Q1:Texture占用内存总是双倍,这个是我们自己的问题,还是Unity引擎的机制? Q2:我现在发现两个因素直接影响Overhead,一个是Shader的复杂度,一个是空Updat ...
- 袋鼠云研发手记 | 数栈·开源:Github上400+Star的硬核分布式同步工具FlinkX
作为一家创新驱动的科技公司,袋鼠云每年研发投入达数千万,公司80%员工都是技术人员,袋鼠云产品家族包括企业级一站式数据中台PaaS数栈.交互式数据可视化大屏开发平台Easy[V]等产品也在迅速迭代.在 ...
- 阿里钉钉技术分享:企业级IM王者——钉钉在后端架构上的过人之处
本文引用了唐小智发表于InfoQ公众号上的“钉钉企业级IM存储架构创新之道”一文的部分内容,收录时有改动,感谢原作者的无私分享. 1.引言 业界的 IM 产品在功能上同质化较高,而企业级的 IM 产品 ...
- 数栈运维实例:Oracle数据库运维场景下,智能运维如何落地生根?
从马车到汽车是为了提升运输效率,而随着时代的发展,如今我们又希望用自动驾驶把驾驶员从开车这项体力劳动中解放出来,增加运行效率,同时也可减少交通事故发生率,这也是企业对于智能运维的诉求. 从人工运维到自 ...
- 恒天云技术分享系列5 – 虚拟化平台性能对比(KVM & VMware)
恒天云技术分享系列:http://www.hengtianyun.com/download-show-id-14.html 概述 本性能测试报告将详细陈述各虚拟化平台基准性能测试的主要结论和详细结果. ...
- 恒天云技术分享系列4 – OpenStack网络攻击与防御
恒天云技术分享系列:http://www.hengtianyun.com/download-show-id-13.html 云主机的网络结构本质上和传统的网络结构一致,区别大概有两点. 1.软网络管理 ...
随机推荐
- Delphi 判断字符是否是汉字
function IsHZ(ch: WideChar): boolean; var i: Integer; begin i := Ord(ch); if (i < 19968) or (i &g ...
- DeepSeek引发的AI发展路径思考
DeepSeek引发的AI发展路径思考 参考文章来源于科技导报 ,作者李国杰院士 | 哈工大 DeepSeek 技术前沿与应用讲座 1. DeepSeek 的科技突破 7 天之内 DeepSeek 的 ...
- study Python3 【1】
用VSCode来编辑Python代码,作为IDE使用,有点头晕. https://www.runoob.com/python3/python-vscode-setup.html有介绍.还有更好的博客介 ...
- datasnap的Restful的接口方法
//Restful接口测试 //GET function Test(Value: string): string; //POST function updateTest(Value: string; ...
- Avalonia跨平台实战(二),Avalonia相比WPF的便利合集(一)
本话讲的是Avalonia中相比于WPF更方便的一些特性 布局 布局方面没什么好说的,和WPF没什么区别,Grid,StckPanel...这些,不熟悉的话可以B站上找一下教程 xml树 在WPF中我 ...
- Junit单元测试的maven设置
maven 官方文档: https://maven.apache.org/surefire/maven-surefire-plugin/usage.html maven是通过插件 maven-sure ...
- symfony或doctrine报错:Object of class App\Entity\* could not be converted to string
报错: Catchable Fatal Error: Object of class App\Entity\ProjectType could not be converted to string 版 ...
- 『Plotly实战指南』--样式定制基础篇
在数据可视化的世界中,一个精心设计的图表不仅能准确传达信息,还能提升整体的专业性和吸引力. 而Plotly作为Python中强大的可视化库,提供了丰富的样式定制功能,帮助我们轻松实现这一目标. 本文从 ...
- 在IIS发布.net9 api程序踩坑总结
参照:.NET 9.0 WebApi 发布到 IIS 详细步骤_webapi发布到iis-CSDN博客 环境搭建: 注意安装与程序版本对应的Windows Server Hosting,安装完成之后, ...
- JWT Token解析
参照:c#中token的使用方法实例_C#教程_脚本之家 (jb51.net) (7条消息) JWT 算法_み旋律的博客-CSDN博客_jwt算法