大巧不工,袋鼠云正式开源大数据任务调度平台——Taier(太阿)!
2022年2月22日,在今天这个特殊的日子里,历经多年持续迭代和千万周期实例并发调度考验的Taier(太阿)终于开源了!
Github开源地址:
https://github.com/DTStack/Taier
官方文档地址:
https://dtstack.github.io/Taier/
这是袋鼠云开源项目的重要里程碑事件,代表着袋鼠云技术研发团队对开源的决心。我们希望通过技术分享,帮助更多人探索大数据平台的业务场景,同时也由衷欢迎更多开发者参与到社区中来,Committer虚位以待!
|缘起:太阿出鞘
Taier的命名,源自中国十大名剑太阿。

Taier Logo
太阿是春秋战国时期楚国的镇国至宝,由铸剑名师欧冶子和干将联手打造。相传楚国在生死存亡之际,靠太阿剑气击败晋国大军,被世人誉为诸侯威武之剑,象征了威武不屈、内心强大的实力,正如Taier强悍稳定的任务调度能力,每天可处理15w+超庞大任务体量,不但大大降低企业ETL的开发成本,还能有效保障大数据平台的平稳运行,功能强大,一如太阿剑威力无穷。
|亮剑:Taier诞生
Taier的诞生,与时代的发展息息相关。
如今,数字化转型已成为全球浪潮,大数据平台建设成为新时代必不可少的基础设施。随着数字化转型的深入,很多企业在建设数据中台过程中,将涉及大量数据采集、处理、计算等方面的工作,需求的不断叠加,出现了单个系统难以满足复杂业务的情况,迫切需要一种兼容多个子系统互相协作的任务调度系统协调,正是基于这种背景,Taier分布式DAG任务调度系统应运而生。
Taier是一个开箱即用的分布式可视化的DAG任务调度系统,技术开发人员可以在Taier 直接进行业务逻辑的开发,而不用关心任务错综复杂的依赖关系与底层的大数据平台的架构实现,将工作的重心更多地聚焦在业务之中。
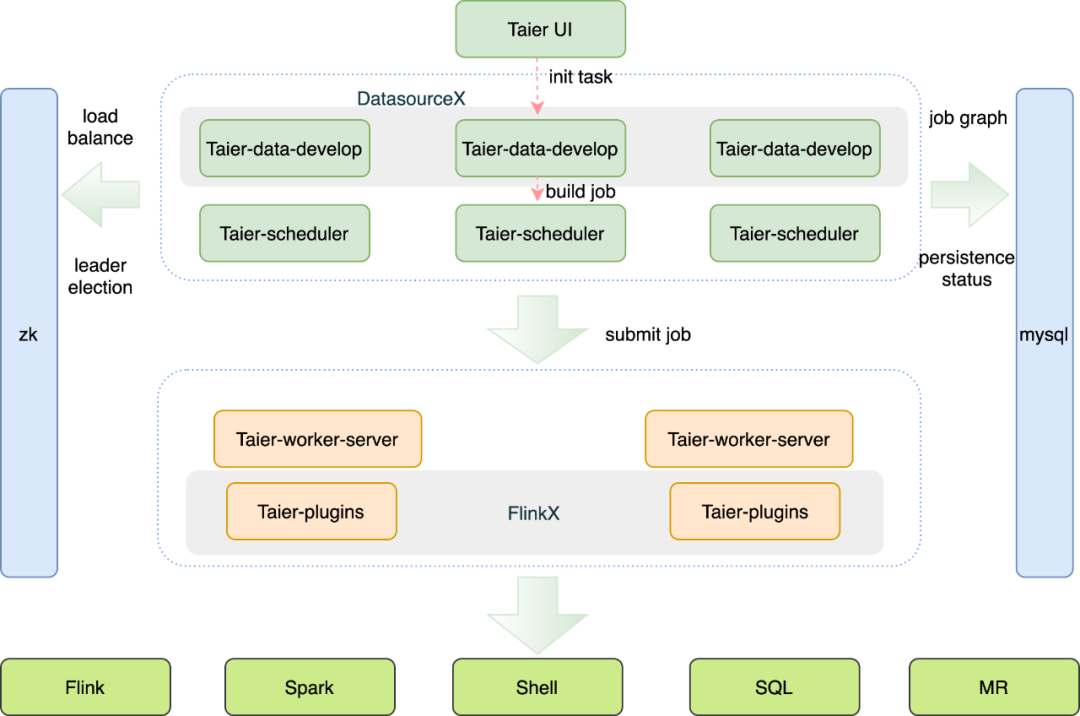
Taier(太阿)调度系统架构图
在Taier Logo的设计上,我们围绕系统本身开放包容、简单易用的特性,在设计中融入了积木、剑、蜂巢等元素。主体Logo由四块积木交叠而成,形若利剑,有组合,有分离,传达开源项⽬开放包容的理念,同时也表现Taier采⽤分布式模式——具有很强的解耦性、扩展性。
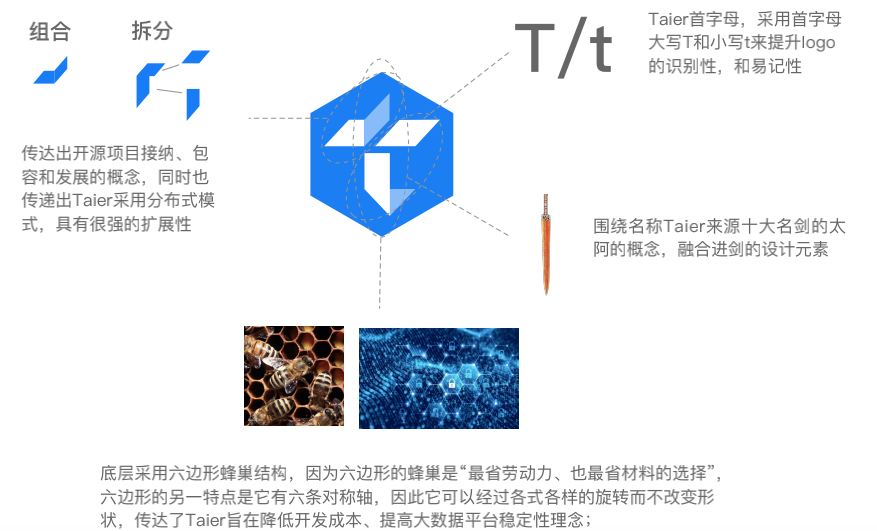
Taier Logo创意阐释
Logo底层采⽤六边形蜂巢结构,六边形蜂巢是大自然中最省劳动⼒、最省材料、最稳定的排列⽅式,其六条对称轴可以经过各种旋转⽽不改变形状,选用六边形作为Logo的边框,意在传达Taier降低开发成本、提⾼⼤数据平台稳定性的特点。
|亮点:Taier功能优势
作为一个分布式可视化的DAG任务调度系统,太阿Taier脱胎于袋鼠云的一站式大数据开发平台——数栈DTinsight,技术实现来源于数栈分布式调度引擎DAGScheduleX,DAGScheduleX是数栈产品的重要基础设施之一,负责大数据平台所有任务实例的调度运行。太阿Taier是DAGScheduleX的重要枢纽,负责调度日常庞大的任务体量,多年的持续迭代与沉淀,造就了太阿Taier六大核心优势:
一、超高的稳定性
单点故障:去中心化的分布式模式
高可用方式:Zookeeper
过载处理:分布式节点+ 两级存储策略 + 队列机制。每个节点都可以处理任务调度与提交;任务多时会优先缓存在内存队列,超出可配置的队列最大数量值后会全部落数据库;任务处理以队列方式消费,队列异步从数据库获取可执行实例
实战检验:得到数百家企业客户生产环境实战检验
二、超强的易用性,一站式任务调度
支持大数据作业Spark、Flink、Hive、MR的调度
支持众多的任务类型,目前支持Spark SQL、Flinkx;后续开源支持:SparkMR、PySpark、FlinkMR、Python、Shell、Jupyter、Tersorflow、Pytorch、HadoopMR、Kylin、Odps、SQL类任务(MySQL、PostgreSQL、Hive、Impala、Oracle、SQLServer、TiDB、greenplum、inceptor、kingbase、presto)
可视化工作流配置:支持封装工作流、支持单任务运行,不必封装工作流、支持拖拽模式绘制DAG
DAG监控界面:运维中心、支持集群资源查看,了解当前集群资源的剩余情况、支持对调度队列中的任务批量停止、任务状态、任务类型、重试次数、任务运行机器、可视化变量等关键信息一目了然
调度时间配置:可视化配置
多集群连接:支持一套调度系统连接多套Hadoop集群
三、超凡的兼容性,支持多版本引擎
支持Spark 、Flink、Hive、MR等引擎的多个版本共存,例如可同时支持Flink1.10、Flink1.12(后续开源)
四、安全可靠,支持Kerberos
Spark、Flink、Hive
五、丰富的系统参数
支持3种时间基准,且可以灵活设置输出格式
六、卓越的扩展性,支持多种方式扩容
设计之处就考虑分布式模式,目前支持整体Taier水平扩容方式;后续开源支持:Scheduler/Worker分离部署模式。
调度能力随集群线性增长
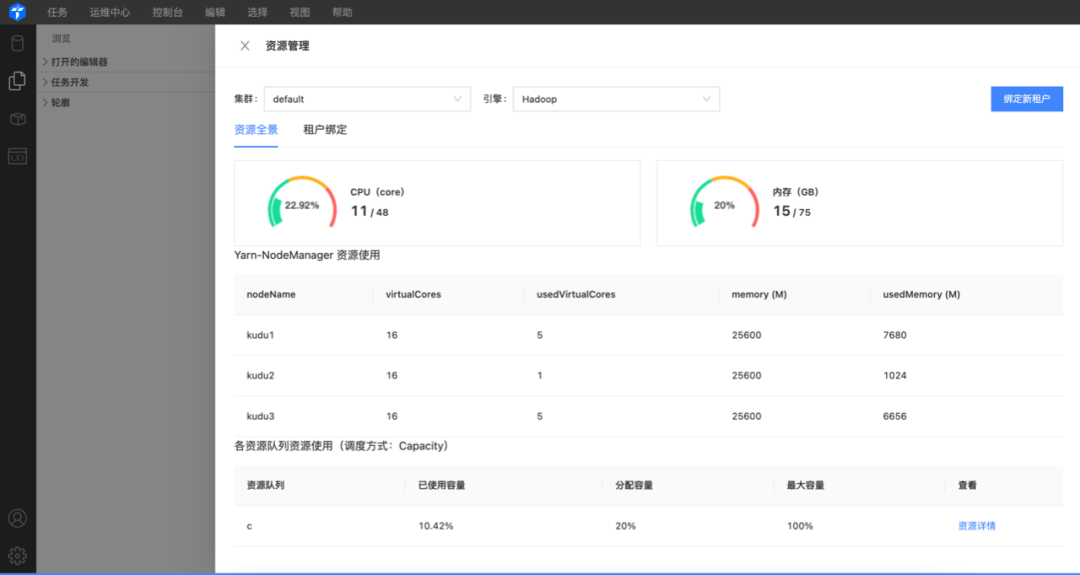
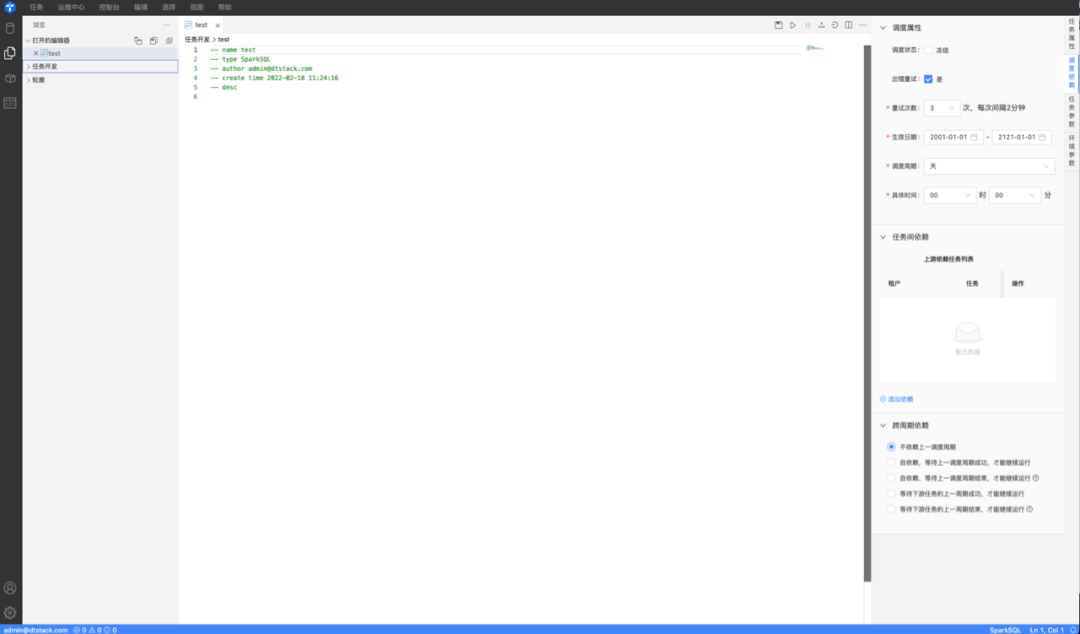
|终端:Taier用户界面

|展望:未来迭代计划
Taier调度平台是数据平台框架中的一个组件,可以满足企业日常数据分析、处理、展示需要。未来随着业务的接入和数据规模的增大,Taier将持续提升用户体验,计划将优化:
任务类型:支持SparkMR、PySpark、FlinkMR、Python、Shell、Jupyter、Tersorflow、Pytorch、HadoopMR、Kylin、Odps、SQL(MySQL、PostgreSQL、Hive、Impala、Oracle、SQLServer、TiDB、greenplum、inceptor、kingbase、presto
调度方式:同时支持Yarn/K8s
计算引擎:同时支持Spark-2.1.x/2.4.x、Flink-1.10/1.12(与Flink后续版本)
部署方式:同时支持Scheduler/Worker整合与分离部署
功能支持:支持交易日历、事件驱动
外部系统对接:支持Taier系统对接外部调度系统(AZKBAN、Control-M、DS调度)
|结语:
Taier 使用了 Apache 的多个开源项目如Flink、Spark 作为计算组件实现数据同步和批处理计算,得益于开源社区才有如今的太阿 Taier。正因为Taier 取之于社区, 所以我们希望通过开源此项技术的方式,回馈社区,共同弘扬“Community Over Code“的Apache文化。未来,我们仍将秉承兼容并包与开放多样化的心态,将继续推出Taier 后续版本,欢迎更多的公司和个人参与到开发者队伍中来,让Taier社区更加健壮、健康的发展,让更多人享受开源带来的技术革命!
大巧不工,袋鼠云正式开源大数据任务调度平台——Taier(太阿)!的更多相关文章
- 开源大数据技术专场(下午):Databircks、Intel、阿里、梨视频的技术实践
摘要: 本论坛第一次聚集阿里Hadoop.Spark.Hbase.Jtorm各领域的技术专家,讲述Hadoop生态的过去现在未来及阿里在Hadoop大生态领域的实践与探索. 开源大数据技术专场下午场在 ...
- 开源大数据技术专场(上午):Spark、HBase、JStorm应用与实践
16日上午9点,2016云栖大会“开源大数据技术专场” (全天)在阿里云技术专家封神的主持下开启.通过封神了解到,在上午的专场中,阿里云高级技术专家无谓.阿里云技术专家封神.阿里巴巴中间件技术部高级技 ...
- 华为云BigData Pro解读: 鲲鹏云容器助力大数据破茧成蝶
华为云鲲鹏云容器 见证BigData Pro蝶变之旅大数据之路顺应人类科技的进步而诞生,一直顺风顺水,不到20年时间,已渗透到社会生产和人们生活的方方面面,.然而,伴随着信息量的指数级增长,大数据也开 ...
- 开源大数据生态下的 Flink 应用实践
过去十年,面向整个数字时代的关键技术接踵而至,从被人们接受,到开始步入应用.大数据与计算作为时代的关键词已被广泛认知,算力的重要性日渐凸显并发展成为企业新的增长点.Apache Flink(以下简称 ...
- 持续引领大数据行业发展,腾讯云发布全链路数据开发平台WeData
9月11日,在腾讯全球数字生态大会大数据专场上,腾讯云大数据产品副总经理雷小平重磅发布了全链路数据开发平台WeData,同时发布和升级了流计算服务.云数据仓库.ES.企业画像等6款核心产品,进一步优化 ...
- 揭秘阿里云EB级大数据计算引擎MaxCompute
日前,全球权威咨询与服务机构Forrester发布了<The Forrester WaveTM: Cloud Data Warehouse, Q4 2018>报告.这是Forrester ...
- 从 Airflow 到 Apache DolphinScheduler,有赞大数据开发平台的调度系统演进
点击上方 蓝字关注我们 作者 | 宋哲琦 ✎ 编 者 按 在不久前的 Apache DolphinScheduler Meetup 2021 上,有赞大数据开发平台负责人 宋哲琦 带来了平台调度系统 ...
- 大数据计算平台Spark内核解读
1.Spark介绍 Spark是起源于美国加州大学伯克利分校AMPLab的大数据计算平台,在2010年开源,目前是Apache软件基金会的顶级项目.随着 Spark在大数据计算领域的暂露头角,越来越多 ...
- 大数据计算平台Spark内核全面解读
1.Spark介绍 Spark是起源于美国加州大学伯克利分校AMPLab的大数据计算平台,在2010年开源,目前是Apache软件基金会的顶级项目.随着Spark在大数据计算领域的暂露头角,越来越多的 ...
- 基于MaxCompute的媒体大数据开放平台建设
摘要:随着自媒体的发展,传统媒体面临着巨大的压力和挑战,新华智云运用大数据和人工智能技术,致力于为媒体行业赋能.通过媒体大数据开放平台,将媒体行业全网数据汇总起来,借助平台数据处理能力和算法能力,将有 ...
随机推荐
- Linux下使用fdisk扩大分区容量
磁盘容量有300GB,之前分区的时候只分了一个150GB的/data分区,现在/data分区已经不够用了. 需求:把这块磁盘剩余的150GB容量增加到之前的/data分区,并且保证/data分区原有的 ...
- frameset frame 实例和用法
转
看这个比较好
- Springboot连接Greenplum,分页查询
1.springboot分页查询greenplum数据报错: org.mybatis.spring.MyBatisSystemException: nested exception is org.ap ...
- Java连接Redis常用操作
1.去重 package Data; import redis.clients.jedis.Jedis; public class TestRedisUniq { public static Jedi ...
- 事务注解@Transactional
目录 1.属性介绍 2.传播机制 准备例子 总结 3.原理 4.失效场景 一.属性介绍 1.isolation 属性 事务的隔离级别,默认值为 Isolation.DEFAULT.可选的值有: Iso ...
- apache/wampserver配置虚拟主机、多站点端口、允许通过ip访问
虽然经常配置这个,但有时一着急想不起来,这里做个记录 步骤: 监听本网络本主机的端口 (Listen 0.0.0.0:端口号) 添加虚拟主机 VirtualHost 配置目录访问权限(Require ...
- hadoop集群搭建(亲测笔记)
------步骤: 准备3台机器 同步时间 配置主机名 配置主机名ip映射 免密登录 关闭防火墙 搭建zookeeper集群 搭建hadoop 准备3台机器 我通过VMware workstation ...
- 前端传字符串,需要转List对象
前端传字符串,需要转List对象 import com.alibaba.fastjson.JSONObject; List<LogySbjsJdsbqxxxAccount> param = ...
- Qwen3接入评测,最强开源模型更懂Graph了吗?
今日凌晨,阿里开源Qwen3,推理成本大幅下降,性能全面超越 DeepSeek-R1.OpenAI-o1 等,问鼎全球最强开源模型.在代码.数学.通用能力各项性能指标中,Qwen3都名列前茅.与 De ...
- 基于Kubernetes可扩展的Selenium 并行自动化测试部署及搭建(2)——Win10环境下Kubernetes(k8s)部署
继续上一篇,本篇进行K8S环境部署. K8s部署: 1. 访问k8s-for-docker-desktop 的github地址: https://github.com/AliyunContainer ...