ROC AUC
1、什么是性能度量?
我们都知道机器学习要建模,但是对于模型性能的好坏(即模型的泛化能力),我们并不知道是怎样的,很可能这个模型就是一个差的模型,泛化能力弱,对测试集不能很好的预测或分类。那么如何知道这个模型是好是坏呢?我们必须有个评判的标准。为了了解模型的泛化能力,我们需要用某个指标来衡量,这就是性能度量的意义。有了一个指标,我们就可以对比不同模型了,从而知道哪个模型相对好,那个模型相对差,并通过这个指标来进一步调参逐步优化我们的模型。
当然,对于分类和回归两类监督学习,分别有各自的评判标准。本篇我们主要讨论与分类相关的一些指标,因为AUC/ROC就是用于分类的性能度量标准。
混淆矩阵,准确率,精准率,召回率
1. 混淆矩阵
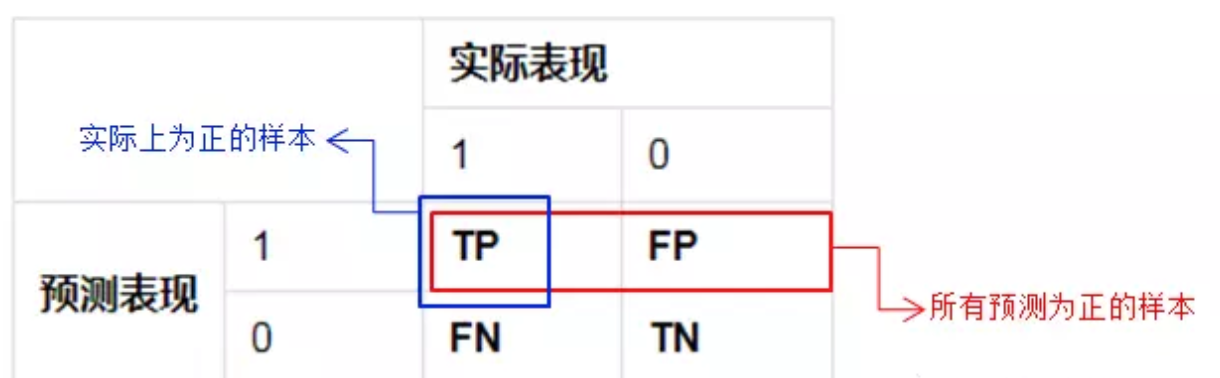
在介绍各个率之前,先来介绍一下混淆矩阵。如果我们用的是个二分类的模型,那么把预测情况与实际情况的所有结果两两混合,结果就会出现以下4种情况,就组成了混淆矩阵。

由于1和0是数字,阅读性不好,所以我们分别用P和N表示1和0两种结果。变换之后为PP,PN,NP,NN,阅读性也很差,我并不能轻易地看出来预测的正确性与否。因此,为了能够更清楚地分辨各种预测情况是否正确,我们将其中一个符号修改为T和F,以便于分辨出结果。
P(Positive):代表1
N(Negative):代表0
T(True):代表预测正确
F(False):代表错误
按照上面的字符表示重新分配矩阵,混淆矩阵就变成了下面这样:

将这种表示方法总结如下,可分为两部分:

因此对于这种表示方法可以这么简单的理解:先看 ①预测结果(P/N),再根据②实际表现对比预测结果,给出判断结果(T/F)。按这个顺序理解,这四种情况就很好记住了。
TP:预测为1,预测正确,即实际1
FP:预测为1,预测错误,即实际0
FN:预测为0,预测错确,即实际1
TN:预测为0,预测正确即,实际0
2. 准确率
既然是个分类指标,我们可以很自然的想到准确率,准确率的定义是预测正确的结果占总样本的百分比,其公式如下:
准确率=(TP+TN)/(TP+TN+FP+FN)

虽然准确率可以判断总的正确率,但是在样本不平衡的情况下,并不能作为很好的指标来衡量结果。举个简单的例子,比如在一个总样本中,正样本占90%,负样本占10%,样本是严重不平衡的。对于这种情况,我们只需要将全部样本预测为正样本即可得到90%的高准确率,但实际上我们并没有很用心的分类,只是随便无脑一分而已。这就说明了:由于样本不平衡的问题,导致了得到的高准确率结果含有很大的水分。即如果样本不平衡,准确率就会失效。
正因为如此,也就衍生出了其它两种指标:精准率和召回率。
3. 精准率
精准率(Precision)又叫查准率,它是针对****预测结果而言的,它的含义是在所有被预测为正的样本中实际为正的样本的概率,意思就是在预测为正样本的结果中,我们有多少把握可以预测正确,其公式如下:
精准率=TP/(TP+FP)
精准率和准确率看上去有些类似,但是完全不同的两个概念。精准率代表对正样本结果中的预测准确程度,而准确率则代表整体的预测准确程度,既包括正样本,也包括负样本。
4. 召回率
召回率(Recall)又叫查全率,它是针对原样本而言的,它的含义是在实际为正的样本中被预测为正样本的概率,其公式如下:
精准率=TP/(TP+FN)

召回率的应用场景:比如拿网贷违约率为例,相对好用户,我们更关心坏用户,不能错放过任何一个坏用户。因为如果我们过多的将坏用户当成好用户,这样后续可能发生的违约金额会远超过好用户偿还的借贷利息金额,造成严重偿失。召回率越高,代表实际坏用户被预测出来的概率越高,它的含义类似:宁可错杀一千,绝不放过一个。
5. 精准率和召回率的关系,F1分数
通过上面的公式,我们发现:精准率和召回率的分子是相同,都是TP,但分母是不同的,一个是(TP+FP),一个是(TP+FN)。两者的关系可以用一个P-R图来展示:

如何理解P-R(查准率-查全率)这条曲线?
有的朋友疑惑:这条曲线是根据什么变化的?为什么是这个形状的曲线?其实这要从排序型模型说起。拿逻辑回归举例,逻辑回归的输出是一个0到1之间的概率数字,因此,如果我们想要根据这个概率判断用户好坏的话,我们就必须定义一个阈值。通常来讲,逻辑回归的概率越大说明越接近1,也就可以说他是坏用户的可能性更大。比如,我们定义了阈值为0.5,即概率小于0.5的我们都认为是好用户,而大于0.5都认为是坏用户。因此,对于阈值为0.5的情况下,我们可以得到相应的一对查准率和查全率。
但问题是:这个阈值是我们随便定义的,我们并不知道这个阈值是否符合我们的要求。因此,为了找到一个最合适的阈值满足我们的要求,我们就必须遍历0到1之间所有的阈值,而每个阈值下都对应着一对查准率和查全率,从而我们就得到了这条曲线。
有的朋友又问了:如何找到最好的阈值点呢?首先,需要说明的是我们对于这两个指标的要求:我们希望查准率和查全率同时都非常高。但实际上这两个指标是一对矛盾体,无法做到双高。图中明显看到,如果其中一个非常高,另一个肯定会非常低。选取合适的阈值点要根据实际需求,比如我们想要高的查全率,那么我们就会牺牲一些查准率,在保证查全率最高的情况下,查准率也不那么低。
F1分数
但通常,如果想要找到二者之间的一个平衡点,我们就需要一个新的指标:F1分数。F1分数同时考虑了查准率和查全率,让二者同时达到最高,取一个平衡。F1分数的公式为 = 2查准率查全率 / (查准率 + 查全率)。我们在图中看到的平衡点就是F1分数得来的结果。
ROC/AUC的概念
1. 灵敏度,特异度,真正率,假正率
在正式介绍ROC/AUC之前,我们还要再介绍两个指标,这两个指标的选择也正是ROC和AUC可以无视样本不平衡的原因。这两个指标分别是:灵敏度和(1-特异度),也叫做真正率(TPR)和假正率(FPR)。
灵敏度(Sensitivity) = TP/(TP+FN)
特异度(Specificity) = TN/(FP+TN)
其实我们可以发现灵敏度和召回率是一模一样的,只是名字换了而已。
由于我们比较关心正样本,所以需要查看有多少负样本被错误地预测为正样本,所以使用(1-特异度),而不是特异度。
真正率(TPR) = 灵敏度 = TP/(TP+FN)
假正率(FPR) = 1- 特异度 = FP/(FP+TN)
下面是真正率和假正率的示意,我们发现TPR和FPR分别是基于实际表现1和0出发的,也就是说它们分别在实际的正样本和负样本中来观察相关概率问题。正因为如此,所以无论样本是否平衡,都不会被影响。还是拿之前的例子,总样本中,90%是正样本,10%是负样本。我们知道用准确率是有水分的,但是用TPR和FPR不一样。这里,TPR只关注90%正样本中有多少是被真正覆盖的,而与那10%毫无关系,同理,FPR只关注10%负样本中有多少是被错误覆盖的,也与那90%毫无关系,所以可以看出:如果我们从实际表现的各个结果角度出发,就可以避免样本不平衡的问题了,这也是为什么选用TPR和FPR作为ROC/AUC的指标的原因。
ROC AUC的更多相关文章
- 一文让你彻底理解准确率,精准率,召回率,真正率,假正率,ROC/AUC
参考资料:https://zhuanlan.zhihu.com/p/46714763 ROC/AUC作为机器学习的评估指标非常重要,也是面试中经常出现的问题(80%都会问到).其实,理解它并不是非常难 ...
- 模型评测之IoU,mAP,ROC,AUC
IOU 在目标检测算法中,交并比Intersection-over-Union,IoU是一个流行的评测方式,是指产生的候选框candidate bound与原标记框ground truth bound ...
- ROC & AUC笔记
易懂:http://alexkong.net/2013/06/introduction-to-auc-and-roc/ 分析全面但难懂:http://mlwiki.org/index.php/ROC_ ...
- 分类器的评价指标-ROC&AUC
ROC 曲线:接收者操作特征曲线(receiver operating characteristic curve),是反映敏感性和特异性连续变量的综合指标,roc 曲线上每个点反映着对同一信号刺激的感 ...
- 模型评估【PR|ROC|AUC】
这里主要讲的是对分类模型的评估. 1.准确率(Accuracy) 准确率的定义是:[分类正确的样本] / [总样本个数],其中分类正确的样本是不分正负样本的 优点:简单粗暴 缺点:当正负样本分布不均衡 ...
- keras 上添加 roc auc指标
https://stackoverflow.com/questions/41032551/how-to-compute-receiving-operating-characteristic-roc-a ...
- Precision/Recall、ROC/AUC、AP/MAP等概念区分
1. Precision和Recall Precision,准确率/查准率.Recall,召回率/查全率.这两个指标分别以两个角度衡量分类系统的准确率. 例如,有一个池塘,里面共有1000条鱼,含10 ...
- 准确率,召回率,F值,ROC,AUC
度量表 1.准确率 (presion) p=TPTP+FP 理解为你预测对的正例数占你预测正例总量的比率,假设实际有90个正例,10个负例,你预测80(75+,5-)个正例,20(15+,5-)个负例 ...
- ROC/AUC以及相关知识点
参考博文,特别的好!!!:https://www.jianshu.com/p/82903edb58dc AUC的计算: 法1:AUC为ROC曲线下的面积,那我们直接计算面积可得.面积为一个个小的梯形面 ...
随机推荐
- 部分视图 - partial
对于partia来说,可以理解为组件化的运用,即将对应的html/js/css进行封装,然后通过模板引擎直接进行调用 1.partial的注册 //可以直接写在app.js,也可以写在之前所说的hel ...
- linux操作系统中安装redis
第一步:安装gcc编译软件 redis是用c编写的,在下载之后需要使用gcc编译之后才能安装,首先需要下载gcc yum install gcc-c++ 第二步 下载redis安装包,并解压编译 ...
- 记录2-在mac上安装ubuntu 16.04 LTS
前几天升级了我用了六七年mac硬件,内存由4G变为8G,硬盘也换成1T SSD,索性把一直想装的ubuntu也装了,方便温习下以前的工作环境. 我比较喜欢LTS的版本,所以安装了16.04. 主要步骤 ...
- Tomcat修改service.xml性能调优 增加最大并发连接数
详细配置: <Connector executor="tomcatThreadPool" port="80" protocol ...
- C语言的split功能
其它高级语言都有字符串的split功能,但C没有系统自带的,只能自己写一个了. void c_split(char *src, const char *separator, int maxlen, c ...
- 搭建zookeeper+kafka集群
搭建zookeeper+kafka集群 一.环境及准备 集群环境: 软件版本: 部署前操作: 关闭防火墙,关闭selinux(生产环境按需关闭或打开) 同步服务器时间,选择公网ntpd服务器或 ...
- dva中roadhog版本升级后带来的问题及解决方法
从同事手中接手项目之后.npm install 然后npm start的时候.开始报上图的错误.解决方法一(比较 愚蠢)当时找到的解决方法都没有用.然后只能按照报错的路径,从同事那边复制了node_m ...
- Navicat连接到服务器端数据库
https://blog.csdn.net/javakklam/article/details/80060866
- js长整型的失真问题解决
遇到的问题: 后端返回的订单号是整型的,超过了Math.pow(2,53) = 9007199254740992,导致获取的数据失真. 类似问题:https://www.zhihu.com/quest ...
- C#创建windows服务并发布
创建window 服务 新建一个window 服务项目MyService,如下图 切换到代码视图修改. using System; using System.Collections.Generic; ...