斯坦福大学公开课机器学习:machine learning system design | data for machine learning(数据量很大时,学习算法表现比较好的原理)
下图为四种不同算法应用在不同大小数据量时的表现,可以看出,随着数据量的增大,算法的表现趋于接近。即不管多么糟糕的算法,数据量非常大的时候,算法表现也可以很好。
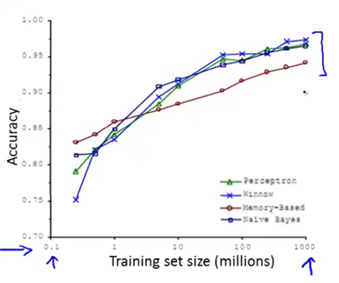
数据量很大时,学习算法表现比较好的原理:
使用比较大的训练集(意味着不可能过拟合),此时方差会比较低;此时,如果在逻辑回归或者线性回归模型中加入很多参数以及层数的话,则偏差会很低。综合起来,这会是一个很好的高性能的学习算法。

斯坦福大学公开课机器学习:machine learning system design | data for machine learning(数据量很大时,学习算法表现比较好的原理)的更多相关文章
- 斯坦福大学公开课机器学习:advice for applying machine learning | diagnosing bias vs. variance(机器学习:诊断偏差和方差问题)
当我们运行一个学习算法时,如果这个算法的表现不理想,那么有两种原因导致:要么偏差比较大.要么方差比较大.换句话说,要么是欠拟合.要么是过拟合.那么这两种情况,哪个和偏差有关.哪个和方差有关,或者是不是 ...
- 第19月第8天 斯坦福大学公开课机器学习 (吴恩达 Andrew Ng)
1.斯坦福大学公开课机器学习 (吴恩达 Andrew Ng) http://open.163.com/special/opencourse/machinelearning.html 笔记 http:/ ...
- 斯坦福大学公开课机器学习:machine learning system design | error metrics for skewed classes(偏斜类问题的定义以及针对偏斜类问题的评估度量值:查准率(precision)和召回率(recall))
上篇文章提到了误差分析以及设定误差度量值的重要性.那就是设定某个实数来评估学习算法并衡量它的表现.有了算法的评估和误差度量值,有一件重要的事情要注意,就是使用一个合适的误差度量值,有时会对学习算法造成 ...
- 斯坦福大学公开课机器学习:Neural Networks,representation: non-linear hypotheses(为什么需要做非线性分类器)
如上图所示,如果用逻辑回归来解决这个问题,首先需要构造一个包含很多非线性项的逻辑回归函数g(x).这里g仍是s型函数(即 ).我们能让函数包含很多像这的多项式,当多项式足够多时,那么你也许能够得到可以 ...
- 斯坦福大学公开课机器学习: machine learning system design | error analysis(误差分析:检验算法是否有高偏差和高方差)
误差分析可以更系统地做出决定.如果你准备研究机器学习的东西或者构造机器学习应用程序,最好的实践方法不是建立一个非常复杂的系统.拥有多么复杂的变量,而是构建一个简单的算法.这样你可以很快地实现它.研究机 ...
- 斯坦福大学公开课机器学习: machine learning system design | prioritizing what to work on : spam classification example(设计复杂机器学习系统的主要问题及构建复杂的机器学习系统的建议)
当我们在进行机器学习时着重要考虑什么问题.以垃圾邮件分类为例子.假如你想建立一个垃圾邮件分类器,看这些垃圾邮件与非垃圾邮件的例子.左边这封邮件想向你推销东西.注意这封垃圾邮件有意的拼错一些单词,就像M ...
- 斯坦福大学公开课机器学习:advice for applying machine learning | model selection and training/validation/test sets(模型选择以及训练集、交叉验证集和测试集的概念)
怎样选用正确的特征构造学习算法或者如何选择学习算法中的正则化参数lambda?这些问题我们称之为模型选择问题. 在对于这一问题的讨论中,我们不仅将数据分为:训练集和测试集,而是将数据分为三个数据组:也 ...
- 斯坦福大学公开课机器学习:advice for applying machine learning - deciding what to try next(设计机器学习系统时,怎样确定最适合、最正确的方法)
假如我们在开发一个机器学习系统,想试着改进一个机器学习系统的性能,我们应该如何决定接下来应该选择哪条道路? 为了解释这一问题,以预测房价的学习例子.假如我们已经得到学习参数以后,要将我们的假设函数放到 ...
- 斯坦福大学公开课机器学习:machine learning system design | trading off precision and recall(F score公式的提出:学习算法中如何平衡(取舍)查准率和召回率的数值)
一般来说,召回率和查准率的关系如下:1.如果需要很高的置信度的话,查准率会很高,相应的召回率很低:2.如果需要避免假阴性的话,召回率会很高,查准率会很低.下图右边显示的是召回率和查准率在一个学习算法中 ...
随机推荐
- python之路--反射
一 . isinstance, type, issubclass isinstance 可以判断该对象是否是XXX家族体系中的(只能往上判断) class Base: pass class Foo(B ...
- zabbix自定义模板——监控TCP连接状态
TCP十二种连接状态说明 可以使用man netstat查看 LISTEN - 侦听来自远方TCP端口的连接请求: SYN-SENT -在发送连接请求后等待匹配的连接请求: SYN-RECEIVED ...
- linux 安装python 和pip
下载文件 python官网:https://www.python.org/downloads/ 百度网盘http://pan.baidu.com/s/1mixGB12 密码 9nzu [r ...
- jqGrid选中行、格式化、自定义按钮、隐藏
获取选择一行的id: var id=$('#jqGrid').jqGrid('getGridParam','selrow'); 获取选择多行的id: var ids=$('#jqGrid').jqGr ...
- HTTP协议 - 基础认识
在http协议使用场景上我们最熟悉的可能就是浏览器了,作为本系列第一篇,就讲一个问题 ”浏览器怎么连接上服务器并获取网页内容的“ : 首先 浏览器怎么连接上服务器的? 如果对OSI七层模型或者TCP ...
- Jenkins+PowerShell持续集成环境搭建(八)邮件通知
1. 默认邮件功能: Jenkins自带的邮件功能比较简单,配置如下: 设置默认发件人地址: 2. Email Extension Plugin 为了能够更加灵活地使用邮件功能,需要安装Email E ...
- 51nod1016
1016 水仙花数 V2 1 秒 131,072 KB 160 分 6 级题 水仙花数是指一个 n 位数 ( n≥3 ),它的每个位上的数字的 n 次幂之和等于它本身.(例如:1^3 + 5^3 ...
- Matplotlib学习---用seaborn画联合分布图(joint plot)
有时我们不仅需要查看单个变量的分布,同时也需要查看变量之间的联系,这时就需要用到联合分布图. 这里利用Jake Vanderplas所著的<Python数据科学手册>一书中的数据,学习画图 ...
- 【XSY2484】mex 离散化 线段树
题目大意 给你一个无限长的数组,初始的时候都为\(0\),有3种操作: 操作\(1\)是把给定区间\([l,r]\)设为\(1\): 操作\(2\)是把给定区间\([l,r]\)设为\(0\): 操作 ...
- linux tar 解压命令
如果提示 common not find 先进行安装如下 wget http://www.rarsoft.com/rar/rarlinux-5.3.0.tar.gz tar -zxvf rarlinu ...