《SQL必知必会》学习笔记(一)
这两天看了《SQL必知必会》第四版这本书,并照着书上做了不少实验,也对以前的概念有得新的认识,也发现以前自己有得地方理解错了。我采用的数据库是SQL Server2012.数据库中有一张比赛成绩表,表里有四个字段。下面变列出我新学到的知识。
这个是数据库的全部记录

1.order by
语句: select * from Scores order by name , Score desc
执行结果:

①order by在执行排序功能时,会先对排序字段按abcd这样的顺序进行,汉字的话是按拼音的首字母,默认是正序。
②例子中先按name字段进行正序排序,当name相同时,又按score倒叙排,例如拜仁两条数据,胜的开头字母是s,负的是f,因为是倒叙,所以胜的那条数据排在前面。
2.通配符 _ 和 %
通配符 _表示的是匹配单个字符,而%则是匹配多个字符。具体写法两者无差别。
select * from Scores where name like '拜_'
select * from Scores where name like '拜%'
注意:①通配符%看起来像是可以匹配任何东西, 但有个例外, 这就是NULL。 子句where name like '%' 不会匹配产品名称为NULL的行。
②不要过度使用通配符。 如果其他操作符能达到相同的目的,应该使用其他操作符。
在确实需要使用通配符时, 也尽量不要把它们用在搜索模式的开始处。 把通配符置于开始处, 搜索起来是最慢的。
3.拼接字段 +
语句: select name+ '('+ Score +')' as ac from Scores
执行结果:

拼接字段就算把两个字段合成一个字段的查询出来。
4.文本处理函数
①SQL中有很多内置函数,这个表是常用的文本处理函数。

语句: select upper(name) from Scores
select len(name) from Scores
select left(name,1) from Scores
执行结果:


②其中对于SOUNDEX()解释一下,SOUNDEX是一个将任何文本串 转换为描述其语音表示的字母数字模式的算法。
select soundex(date) from Scores

select * from Scores where soundex(name) =soundex('张三')

5.日期和时间处理函数
日期和时间采用相应的数据类型存储在表中,每种DBMS都有自己的特殊形式。 日期和时间值以特殊的格式存储,以便能快速和有效地排序或过滤,并且节省物理存储空间。
语句: select date,name from Scores where DATEPART(DD,Date)=10 --查询10号的数据
执行结果:
6.聚合函数
聚合函数是对某些行进行函数运算,并返回一个值,下图是常用的聚合函数。
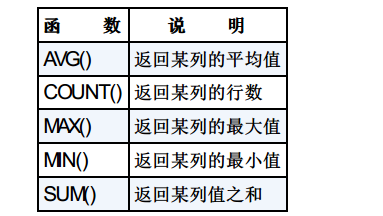
说明:①五个函数都忽略列值为NULL的行。
②使用COUNT(*)对表中行的数目进行计数,不管表列中包含的是空值(NULL)还是非空值,都会计算到总数中。
③使用COUNT(column) 对特定列中具有值的行进行计数, 忽略NULL值。
7.分组函数Group By和having
① 当需要统计球队的胜场次数时,这个时候就需要用到分组函数Group By,用到Group By之后,过滤条件就不能用where了,而要用到having。
语句: select name,COUNT(*) as 场次 from Scores group by name --查询球队名和比赛场次信息
结果:

语句:select name,COUNT(*) as 场次 from Scores group by name having COUNT(*)>1 --查询球队名和比赛场次大于1场的信息
结果:

注意:分组查询中,slect的内容必须是group by的字段或聚合函数,不能是其他。例如将date字段放在select中,便出现错误。

②where和having 差别是:where过滤行, 而having过滤分组。
这里有另一种理解方法, WHERE在数据分组前进行过滤, HAVING在数据分组后进行过滤。 这是一个重要的区别, WHERE排除的行不包括在分组
中。 这可能会改变计算值, 从而影响HAVING子句中基于这些值过滤掉的分组。
语句: select name,COUNT(*) as 场次 from Scores where id<4 group by name having COUNT(*)>1 --在id小于4的数据中查询出球队名和比赛场次大于1场的信息
结果:

8.SELECT子句顺序
SQL 语句的执行顺序跟其语句的语法顺序并不一致,上图是SQL语句的语法顺序。而执行顺序确是:From----->Where----->Group By---->Having----->Select----->Order By
①From 才是 SQL 语句执行的第一步,并非 Select 。数据库在执行 SQL 语句的第一步是将数据从硬盘加载到数据缓冲区中,以便对这些数据进行操作。
② Select 是在大部分语句执行了之后才执行的,严格的说是在 From 和 Group By 之后执行的。理解这一点是非常重要的,这就是你不能在 Where中使用在 Select 中设定别名的字段作为判断条件的原因。
《SQL必知必会》学习笔记(一)的更多相关文章
- 《Hadoop》大数据技术开发实战学习笔记(二)
搭建Hadoop 2.x分布式集群 1.Hadoop集群角色分配 2.上传Hadoop并解压 在centos01中,将安装文件上传到/opt/softwares/目录,然后解压安装文件到/opt/mo ...
- 《Hadoop大数据技术开发实战》学习笔记(一)
基于CentOS7系统 新建用户 1.使用"su-"命令切换到root用户,然后执行命令: adduser zonkidd 2.执行以下命令,设置用户zonkidd的密码: pas ...
- 超人学院Hadoop大数据技术资源分享
超人学院Hadoop大数据技术资源分享 http://bbs.superwu.cn/forum.php?mod=viewthread&tid=807&fromuid=645 很多其它精 ...
- java大数据最全课程学习笔记(1)--Hadoop简介和安装及伪分布式
Hadoop简介和安装及伪分布式 大数据概念 大数据概论 大数据(Big Data): 指无法在一定时间范围内用常规软件工具进行捕捉,管理和处理的数据集合,是需要新处理模式才能具有更强的决策力,洞察发 ...
- hadoop大数据技术架构详解
大数据的时代已经来了,信息的爆炸式增长使得越来越多的行业面临这大量数据需要存储和分析的挑战.Hadoop作为一个开源的分布式并行处理平台,以其高拓展.高效率.高可靠等优点越来越受到欢迎.这同时也带动了 ...
- 除Hadoop大数据技术外,还需了解的九大技术
除Hadoop外的9个大数据技术: 1.Apache Flink 2.Apache Samza 3.Google Cloud Data Flow 4.StreamSets 5.Tensor Flow ...
- 大数据技术之_09_Flume学习_Flume概述+Flume快速入门+Flume企业开发案例+Flume监控之Ganglia+Flume高级之自定义MySQLSource+Flume企业真实面试题(重点)
第1章 Flume概述1.1 Flume定义1.2 Flume组成架构1.2.1 Agent1.2.2 Source1.2.3 Channel1.2.4 Sink1.2.5 Event1.3 Flum ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- 大数据技术之_16_Scala学习_01_Scala 语言概述
第一章 Scala 语言概述1.1 why is Scala 语言?1.2 Scala 语言诞生小故事1.3 Scala 和 Java 以及 jvm 的关系分析图1.4 Scala 语言的特点1.5 ...
- 大数据技术之_16_Scala学习_04_函数式编程-基础+面向对象编程-基础
第五章 函数式编程-基础5.1 函数式编程内容说明5.1.1 函数式编程内容5.1.2 函数式编程授课顺序5.2 函数式编程介绍5.2.1 几个概念的说明5.2.2 方法.函数.函数式编程和面向对象编 ...
随机推荐
- Android 手机卫士--导航界面2
本文地址:http://www.cnblogs.com/wuyudong/p/5947504.html,转载请注明出处. 在之前的文章中,实现了导航界面1布局编写与相关的逻辑代码,如下图所示: 点击“ ...
- Swift-数组
Swift数组 OC和Swift数组的比较 OC 只能存放对象 swift 既可以存放对象,又可以存Int,Float等基本数据类型 下面是swift数组的具体示范 空数组 let arr = [] ...
- Flash Professional 报错 TypeError: Error #1034: 强制转换类型失败:无法将 xxxx@zzzz 转换为 yyy
通常是因为xxx yyy 两个不同链接名的元件 使用了同一个属性名
- 从Sql Server表中随机获取一些记录最简单的方法
* FROM test ORDER BY NewID() 注意,使用时,请将‘test’改为真实的表名.
- SQL Server 2014新特性:分区索引重建
<single_partition_rebuild_index_option> ::= { SORT_IN_TEMPDB = { ON | OFF } | MAXDOP = m ...
- android android BitmapFactory报错OOM
解决方法:listview中尽量不要使用ImageView作为item的组件 换成view并设background
- Mac下安装GIT的坑
先去 https://git-scm.com/download/mac 下载 GIT 客户端 双击安装,界面中有三个文件 接着双节 .pkg 文件,却提示无法安装 解决方式是按住 Control ,再 ...
- 理解Docker(8):Docker 存储之卷(Volume)
(1)Docker 安装及基本用法 (2)Docker 镜像 (3)Docker 容器的隔离性 - 使用 Linux namespace 隔离容器的运行环境 (4)Docker 容器的隔离性 - 使用 ...
- Vuforia Android 6 Camera Error
环境 引擎: Unity 5.3.6f1 SDK: Vuforia 6.0.112 测试系统:Android 4.2/4.3 6.0 Android 6出错 在Android 6下Vuforia打印的 ...
- 新建structs2 web应用及structs.xml常用基础配置
建立一个structs2 web应用程序 1. 创建一个基本的web应用程序 2. 添加structs2的jar文件到Class Path 将structs2的最小jar包拷到WEB-INF/lib目 ...