集合之LinkedHashSet(含JDK1.8源码分析)
一、前言
上篇已经分析了Set接口下HashSet,我们发现其操作都是基于hashMap的,接下来看LinkedHashSet,其底层实现都是基于linkedHashMap的。
二、linkedHashSet的数据结构
因为linkedHashSet的底层是基于linkedHashMap实现的,所以linkedHashSet的数据结构就是linkedHashMap的数据结构,因为前面已经分析过了linkedHashMap的数据结构,这里不再赘述。集合之LinkedHashMap(含JDK1.8源码分析)。
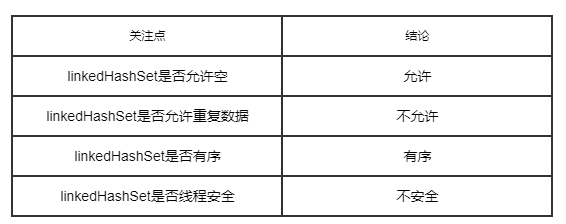
四个关注点在linkedHashSet上的答案
三、linkedHashSet源码分析-属性及构造函数
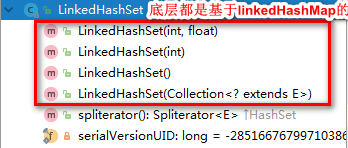
3.1 类的继承关系
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable
说明:继承HashSet,实现了Set接口,其内定义了一些共有的操作。
3.2 类的属性
由上图可知,除了本身的序列号,linkedHashSet并没有定义一些新的属性,其属性都是继承自hashSet。
3.3 类的构造函数
说明:如上图所示,linkedHashSet的四种构造函数都是基于linkedHashMap实现的,这里列出一种,其它几种也是一样。
/**
* Constructs a new, empty linked hash set with the specified initial
* capacity and load factor.
*
* @param initialCapacity the initial capacity of the linked hash set
* @param loadFactor the load factor of the linked hash set
* @throws IllegalArgumentException if the initial capacity is less
* than zero, or if the load factor is nonpositive
*/
public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);
}
通过super调用父类hashSet对应的构造函数,如下:
/**
* Constructs a new, empty linked hash set. (This package private
* constructor is only used by LinkedHashSet.) The backing
* HashMap instance is a LinkedHashMap with the specified initial
* capacity and the specified load factor.
*
* @param initialCapacity the initial capacity of the hash map
* @param loadFactor the load factor of the hash map
* @param dummy ignored (distinguishes this
* constructor from other int, float constructor.)
* @throws IllegalArgumentException if the initial capacity is less
* than zero, or if the load factor is nonpositive
*/
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
四、linkedHashSet源码分析-核心函数
linkedHashSet的add方法,contains方法,remove方法等等都是继承自hashSet的,也是基于hashMap实现的,只是一些细节上还是基于linkedHashMap实现而已,前面已经分析过,这里不再赘述。
举例:
public class Test {
public static void main(String[] args) {
LinkedHashSet linkedHashSet = new LinkedHashSet<>();
linkedHashSet.add("zs");
linkedHashSet.add("ls");
linkedHashSet.add("ww");
linkedHashSet.add("zl");
linkedHashSet.add(null);
linkedHashSet.add("zs");
System.out.println(linkedHashSet);
boolean zs1 = linkedHashSet.remove("zs");
System.out.println("删除zs===" + zs1);
System.out.println(linkedHashSet);
boolean zs = linkedHashSet.contains("zs");
System.out.println("是否包含zs===" + zs);
}
}
结果:可见,linkedHashSet允许空值,不允许重复数据,元素按照插入顺序排列。
[zs, ls, ww, zl, null]
删除zs===true
[ls, ww, zl, null]
是否包含zs===false
五、总结
可见,linkedHashSet是与linkedHashMap相对应的,分析完linkedHashMap再来看linkedHashSet就很简单了。
集合之LinkedHashSet(含JDK1.8源码分析)的更多相关文章
- 集合之TreeSet(含JDK1.8源码分析)
一.前言 前面分析了Set接口下的hashSet和linkedHashSet,下面接着来看treeSet,treeSet的底层实现是基于treeMap的. 四个关注点在treeSet上的答案 二.tr ...
- 集合之HashSet(含JDK1.8源码分析)
一.前言 我们已经分析了List接口下的ArrayList和LinkedList,以及Map接口下的HashMap.LinkedHashMap.TreeMap,接下来看的是Set接口下HashSet和 ...
- 集合之HashMap(含JDK1.8源码分析)
一.前言 之前的List,讲了ArrayList.LinkedList,反映的是两种思想: (1)ArrayList以数组形式实现,顺序插入.查找快,插入.删除较慢 (2)LinkedList以链表形 ...
- 集合之LinkedList(含JDK1.8源码分析)
一.前言 LinkedList是基于链表实现的,所以先讲解一下什么是链表.链表原先是C/C++的概念,是一种线性的存储结构,意思是将要存储的数据存在一个存储单元里面,这个存储单元里面除了存放有待存储的 ...
- 集合之ArrayList(含JDK1.8源码分析)
一.ArrayList的数据结构 ArrayList底层的数据结构就是数组,数组元素类型为Object类型,即可以存放所有类型数据.我们对ArrayList类的实例的所有的操作(增删改查等),其底层都 ...
- 集合之TreeMap(含JDK1.8源码分析)
一.前言 前面所说的hashMap和linkedHashMap都不具备统计的功能,或者说它们的统计性能的时间复杂度都不是很好,要想对两者进行统计,需要遍历所有的entry,时间复杂度比较高,此时,我们 ...
- 集合之LinkedHashMap(含JDK1.8源码分析)
一.前言 大多数的情况下,只要不涉及线程安全问题,map都可以使用hashMap,不过hashMap有一个问题,hashMap的迭代顺序不是hashMap的存储顺序,即hashMap中的元素是无序的. ...
- 【集合框架】JDK1.8源码分析HashSet && LinkedHashSet(八)
一.前言 分析完了List的两个主要类之后,我们来分析Set接口下的类,HashSet和LinkedHashSet,其实,在分析完HashMap与LinkedHashMap之后,再来分析HashSet ...
- 【集合框架】JDK1.8源码分析之HashMap(一) 转载
[集合框架]JDK1.8源码分析之HashMap(一) 一.前言 在分析jdk1.8后的HashMap源码时,发现网上好多分析都是基于之前的jdk,而Java8的HashMap对之前做了较大的优化 ...
随机推荐
- vue组件详解——使用slot分发内容
每天学习一点点 编程PDF电子书.视频教程免费下载:http://www.shitanlife.com/code 一.什么是slot 在使用组件时,我们常常要像这样组合它们: <app& ...
- 001_Python2 的中文编码处理
最近业务中需要用 Python 写一些脚本.尽管脚本的交互只是命令行 + 日志输出,但是为了让界面友好些,我还是决定用中文输出日志信息. 很快,我就遇到了异常: UnicodeEncodeError: ...
- java通过百度AI开发平台提取身份证图片中的文字信息
废话不多说,直接上代码... IdCardDemo.java package com.wulss.baidubce; import java.io.BufferedReader; import jav ...
- 微信硬件平台(七)微信开发--如何存储并定时更新access_token
https://blog.csdn.net/sct_t/article/details/53002611 我们知道请求access_Token会返回这样一个json,包括access_token(凭证 ...
- 06 python初学 (列表内置方法)
目录: type(a) is list :判断 a 是不是列表.返回 True False count:计算列表内某一元素出现的次数 extend:在列表末尾一次性添加另一列表中的全部值 index: ...
- SQLNET.AUTHENTICATION_SERVICES操作系统认证登录的设定
$ORACLE_HOME/network/admin/sqlnet.ora 如果使用了SQLNET.AUTHENTICATION_SERVICES=(NTS)则说明可以使用OS认证就,只要conn / ...
- 深入理解 Object.defineProperty 及实现数据双向绑定
Object.defineProperty() 和 Proxy 对象,都可以用来对数据的劫持操作.何为数据劫持呢?就是在我们访问或者修改某个对象的某个属性的时候,通过一段代码进行拦截行为,然后进行额外 ...
- 一步一步写出java swing登录界面,以及输入的参数获取
经过好几天的学习,研究,接下来说说java swing,以及内嵌浏览器的方法. 一.swing是一个用于java应用程序用户界面的的开发工具包. 例如:接下来我们做个登录界面,简要说明 做之前的构想图 ...
- Pyhton2.x 和Python3.x
一. 异常处理和pint区别 try: ...except Exception,e: # 2.x,3.x 需要把逗号(,)变为as. print e.message # 2.x,3.需要吧print内 ...
- Unity热更新学习(二) —— ToLua c#与lua的相互调用
tolua 下载地址:http://www.ulua.org/index.html c#调用lua的方法,tolua的官方例子提供了很多种.我初步学了一种在做项目使用的方法.通过DoFile方法执行l ...