scrapy暂停和重启,及url去重原理,telenet简单使用
一.scrapy暂停与重启
1.要暂停,就要保留一些中间信息,以便重启读取中间信息并从当前位置继续爬取,则需要一个目录存放中间信息:
scrapy crawl spider_name -s JOBDIR=dir/001——spider_name是你要爬取得spider的py文件名,JOBDIR是命令参数,即代表存放位置参数,dir是中间信息要保存的目录,001新生成的文件夹名是保存的中间信息,重启则读取该文件信息。可以将JOBDIR 设置在setting中,或写在custom_settings中,在Pycharm中都会执行,但是在Pycharm中无法发送ctrl+c,即无法将进程放入后台并暂停。
2.执行命令:scrapy crawl jobbole -s JOBDIR=jobs/001
2.1有可能会报以下错误,这是因为未进入到项目目录(crawl会搜索scrapy.cfg文件):

2.2进入目录正常运行后,ctrl+c暂停进程:
会在jobs下生成一个001文件夹生成如下图文件,request.seen是保存的已经访问了的url,spider.state是spider的状态信息,request.queue中有active.json和p0两个文件,p0是还需要继续做的request(跑完该文件就没有了)


3.重启(也是执行scrapy crawl jobbole -s JOBDIR=jobs/001):
会读取相关信息并继续执行,p0文件会减小,request.seen文件会增大(读取新的request,存入url),两次ctrl+c强制关掉,若需从新爬则可以指定新的文件夹,如jobs/002.
二.scrapy去重原理
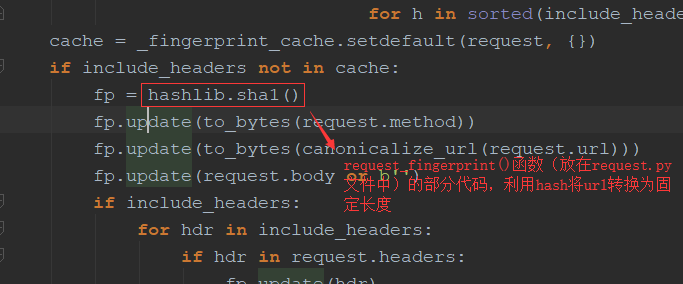
对于每一个url的请求,调度器都会根据请求得相关信息加密(request_fingerprint)得到一个指纹信息,并且将指纹信息和set()集合中的指纹信息进行比对,如果set()集合中已经存在这个数据,就不在将这个Request放入队列中。如果set()集合中没有存在这个加密后的数据,就将这个Request对象放入队列中,等待被调度。

三.telnet的简单使用
1.telnet简介:
Scrapy配有内置的telnet控制台,用于检查和控制Scrapy运行过程。telnet控制台只是在Scrapy进程中运行的常规python shell,所以你可以从中做任何事情。
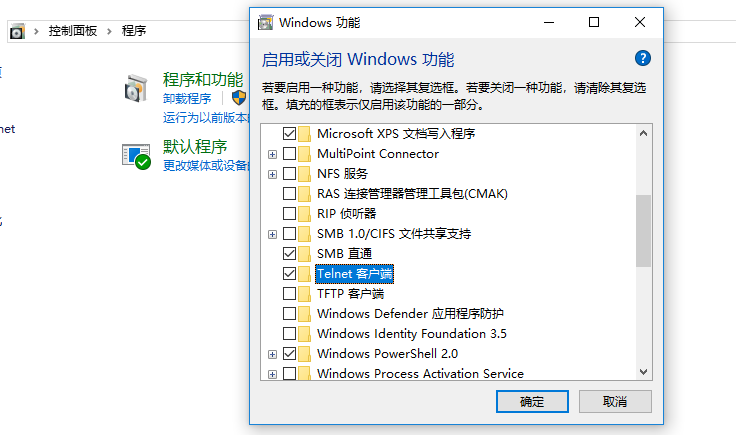
2.windows打开telnet客户端和服务端:
3.telenet连接:
telnet控制台侦听TELNETCONSOLE_PORT设置中定义的TCP端口 ,默认为6023,如下:
telenet localhost 6023
4.telenet简单使用(相当于一个python终端):
变量:

scrapy暂停和重启,及url去重原理,telenet简单使用的更多相关文章
- scrapy 爬虫的暂停与重启
暂停爬虫项目 首先在项目目录下创建一个文件夹用来存放暂停爬虫时的待处理请求url以及其他的信息.(文件夹名称:job_info) 在启动爬虫项目时候用pycharm自带的终端启动输入下面的命令: sc ...
- 第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启
第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启 scrapy的每一个爬虫,暂停时可以记录暂停状态以及爬取了哪些url,重启时可以从暂停状态开始爬取过的UR ...
- 三十二 Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启
scrapy的每一个爬虫,暂停时可以记录暂停状态以及爬取了哪些url,重启时可以从暂停状态开始爬取过的URL不在爬取 实现暂停与重启记录状态 1.首先cd进入到scrapy项目里 2.在scrapy项 ...
- 【转】larbin中的url去重算法
1.bloom filter算法 传说中,larbin使用bloom filter算法来进行url去重.那我们就先来了解下bloom filter算法好了. [以下转自:http://hi.baidu ...
- [原创]手把手教你写网络爬虫(7):URL去重
手把手教你写网络爬虫(7) 作者:拓海 摘要:从零开始写爬虫,初学者的速成指南! 封面: 本期我们来聊聊URL去重那些事儿.以前我们曾使用Python的字典来保存抓取过的URL,目的是将重复抓取的UR ...
- 爬虫URL去重
这个要看你想抓取的网页数量是哪种规模的.如果是千万以下用hash表, set, 布隆过滤器基本可以解决,如果是海量的......嗯我也没做过海量的,不过hash表之类的就别想了,内存根本不够,分割线下 ...
- URL去重与文章去重的一些基本方法
一.url去重url存到数据库所有url放到set中(一亿条占用9G内存)md5之后放到set中(一亿条占用2,3G的内存)scrapy采用的就是类似方法bitmap方法(url经过hash后映射到b ...
- URL 去重的 6 种方案!(附详细实现代码)
URL 去重在我们日常工作中和面试中很常遇到,比如这些: 可以看出,包括阿里,网易云.优酷.作业帮等知名互联网公司都出现过类似的面试题,而且和 URL 去重比较类似的,如 IP 黑/白名单判断等也经常 ...
- [爬虫学习笔记]基于Bloom Filter的url去重模块UrlSeen
Url Seen用来做url去重.对于一个大的爬虫系统,它可能已经有百亿或者千亿的url,新来一个url如何能快速的判断url是否已经出现过非常关键.因为大的爬虫系统可能一秒钟就会下载 ...
随机推荐
- filter 实现登录状态控制
每天学习一点点 编程PDF电子书.视频教程免费下载:http://www.shitanlife.com/code 网站需要做用户登录鉴权控制,没有登录的话,不能访问网站,提示需要登录. 实现方式: 使 ...
- 【转】Xposed出现 java.lang.IllegalAccessError: Class ref in pre-verified class resolved to unexpected implementation
Xposed出现 java.lang.IllegalAccessError: Class ref in pre-verified class resolved to unexpected implem ...
- 【angularjs】pc端使用angular搭建项目,实现导出excel功能
此为简单demo. <!DOCTYPE html> <html ng-app="myApp"> <head> <meta charset= ...
- Oracle 周相关函数
Oracle 周相关函数 select trunc(sysdate,'W'), --每月1日作为第一个星期第一天 取当前周第一天对应日期 trunc(sysdate,'WW'), --每年1月1日 ...
- 二维数组遍历的方式(for普通循环遍历、foreach循环遍历、toString方式遍历)
package com.Summer_0421.cn; import java.lang.reflect.Array; import java.util.Arrays; /** * @author S ...
- 2018-2019-2 20175310 实验二《Java面向对象程序设计》实验报告
2018-2019-2 20175310 实验二<Java面向对象程序设计>实验报告 一.实验步骤及内容 (一).面向对象程序设计-1 参考 http://www.cnblogs.com/ ...
- Linux每天一个命令:iostat
iostat用于输出CPU和磁盘I/O相关的统计信息 安装Sysstat工具包 centos: yum install sysstat ubuntu: sudo apt-get install sys ...
- ML.NET 示例:推荐之One Class 矩阵分解
写在前面 准备近期将微软的machinelearning-samples翻译成中文,水平有限,如有错漏,请大家多多指正. 如果有朋友对此感兴趣,可以加入我:https://github.com/fei ...
- python2.x版本与python3.x版本的区别以及运算符
python2.x中: 重复代码,语言不统一,不支持中文 py2中除法获取的都是整形 py2中有long(长整形) print 可以加括号也可以不加括号 range 在py2中打印的结果是列表 py2 ...
- shell 小工具
1.打印进度条(待完善) #!/bin/sh printf -- 'Performing asynchronous action..'; DONE=; printf -- '............. ...