Python之 爬虫(十二)关于深度优先和广度优先
- 网站的树结构
- 深度优先算法和实现
- 广度优先算法和实现
网站的树结构
通过伯乐在线网站为例子:
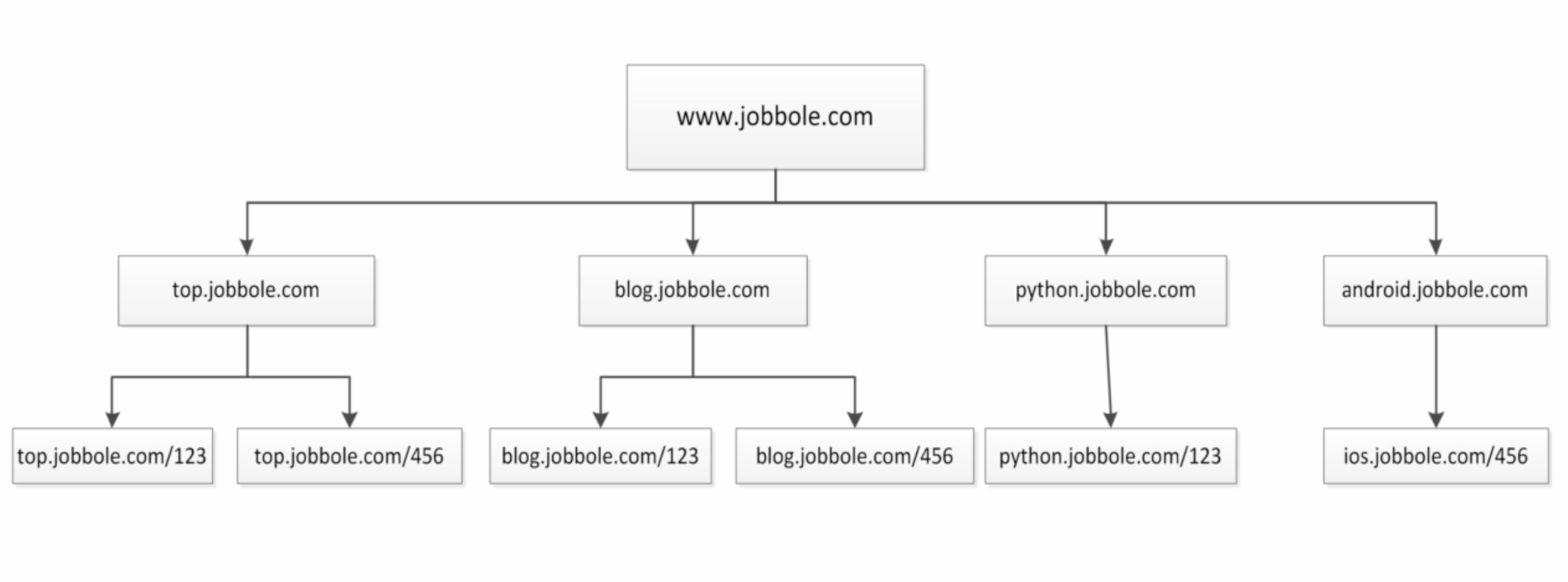
并且我们通过访问伯乐在线也是可以发现,我们从任何一个子页面其实都是可以返回到首页,所以当我们爬取页面的数据的时候就会涉及到去重的问题,我们需要将爬过的url记录下来,我们将上图进行更改

在爬虫系统中,待抓取URL队列是很重要的一部分,待抓取URL队列中的URL以什么样的顺序排队列也是一个很重要的问题,因为这涉及到先抓取哪个页面,后抓取哪个页面。而决定这些URL排列顺序的方法,叫做抓取策略。下面是常用的两种策略:深度优先、广度优先
深度优先
深度优先是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续追踪链接,通过下图进行理解:
注:scrapy默认采用的是深度优先算法
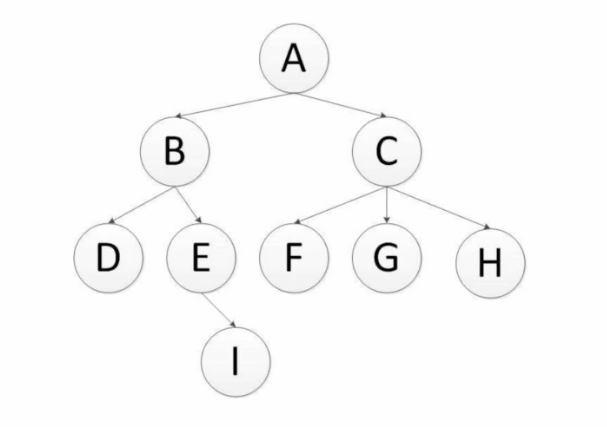
这里是深度优先,所以这里的爬取的顺序式:
A-B-D-E-I-C-F-G-H (递归实现)
深度优先算法的实现(伪代码):

广度优先
广度优先,有人也叫宽度优先,是指将新下载网页发现的链接直接插入到待抓取URL队列的末尾,也就是指网络爬虫会先抓取起始页中的所有网页,然后在选择其中的一个连接网页,继续抓取在此网页中链接的所有网页,通过下图进行理解:

还是以这个图为例子,广度优先的爬取顺序为:
A-B-C-D-E-F-G-H-I (队列实现)
广度优先代码的实现(伪代码):

Python之 爬虫(十二)关于深度优先和广度优先的更多相关文章
- 进击的Python【第十二章】:mysql介绍与简单操作,sqlachemy介绍与简单应用
进击的Python[第十二章]:mysql介绍与简单操作,sqlachemy介绍与简单应用 一.数据库介绍 什么是数据库? 数据库(Database)是按照数据结构来组织.存储和管理数据的仓库,每个数 ...
- python 教程 第二十二章、 其它应用
第二十二章. 其它应用 1) Web服务 ##代码 s 000063.SZ ##开盘 o 26.60 ##最高 h 27.05 ##最低 g 26.52 ##最新 l1 26.66 ##涨跌 c ...
- python 教程 第十二章、 标准库
第十二章. 标准库 See Python Manuals ? The Python Standard Library ? 1) sys模块 import sys if len(sys.argv) ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- python 网络爬虫(二) BFS不断抓URL并放到文件中
上一篇的python 网络爬虫(一) 简单demo 还不能叫爬虫,只能说基础吧,因为它没有自动化抓链接的功能. 本篇追加如下功能: [1]广度优先搜索不断抓URL,直到队列为空 [2]把所有的URL写 ...
- python 网络爬虫(二)
一.编写第一个网络爬虫 为了抓取网站,我们需要下载含有感兴趣的网页,该过程一般被称为爬取(crawling).爬取一个网站有多种方法,而选择哪种方法更加合适,则取决于目标网站的结构. 首先探讨如何安全 ...
- Python爬虫(十二)_XPath与lxml类库
Python学习指南 有同学说,我正则用的不好,处理HTML文档很累,有没有其他的方法? 有!那就是XPath,我们可以用先将HTML文档转换成XML文档,然后用XPath查找HTML节点或元素. 什 ...
- Python之爬虫(二十六) Scrapy登录知乎
因为现在很多网站为了限制爬虫,设置了为只有登录才能看更多的内容,不登录只能看到部分内容,这也是一种反爬虫的手段,所以这个文章通过模拟登录知乎来作为例子,演示如何通过scrapy登录知乎 在通过scra ...
- Python之爬虫(二十五) Scrapy的中间件Downloader Middleware实现User-Agent随机切换
总架构理解Middleware 通过scrapy官网最新的架构图来理解: 这个图较之前的图顺序更加清晰,从图中我们可以看出,在spiders和ENGINE提及ENGINE和DOWNLOADER之间都可 ...
- Python之爬虫(二十四) 爬虫与反爬虫大战
爬虫与发爬虫的厮杀,一方为了拿到数据,一方为了防止爬虫拿到数据,谁是最后的赢家? 重新理解爬虫中的一些概念 爬虫:自动获取网站数据的程序反爬虫:使用技术手段防止爬虫程序爬取数据误伤:反爬虫技术将普通用 ...
随机推荐
- jenkins环境安装(windows)
一.简介 Jenkins是一个开源软件项目,是基于Java开发的一种持续集成工具,用于监控持续重复的工作,旨在提供一个开放易用的软件平台,使软件的持续集成变成可能. 二. Jenkins功能 1. ...
- @hdu - 6426@ Problem A.Alkane
目录 @description@ @solution@ @accepted code@ @details@ @description@ 求包含 n 个碳的烷烃与烷基的同分异构体个数 mod 99824 ...
- JavaScript常用项目(更新至19.11.17)
目录 项目一:鼠标拖动方块 项目二:网页显示键入字母 项目三:实现滚播图 项目四: 本地数据记事本 项目一:鼠标拖动方块 代码: <!DOCTYPE html> <html> ...
- 项目实战:Qt手机模拟器拉伸旋转框架
若该文为原创文章,未经允许不得转载原博主博客地址:https://blog.csdn.net/qq21497936原博主博客导航:https://blog.csdn.net/qq21497936/ar ...
- elasticSearch数据库、skywalking集群部署
Centos6上面安装elasticsearc数据库的集群 安装的是6.3.2版本,安装之前首先要先安装jdk1.8版本 安装之前首先需要关闭防火墙 Centos6 sudo service ipta ...
- Spring Boot Admin 2.1.4最新实战教程
环境的搭建 首先搭建eruka的注册中心 pom.xml <?xml version="1.0" encoding="UTF-8"?> <pr ...
- JavaWeb网上图书商城完整项目--day02-7.提交注册表单功能之流程分析
1.点击注册之后将提交的信息传递到UserServlet的public String regist方法进行处理,然后将东西通过service进行处理 业务流程:
- ubuntu无法安装vim、tree等解决办法
rm /etc/apt/sources.list.d/* 删除该目录下所有文件
- 开发中如何让本地host和代理共存?
开发中若遇到了需要相同域名的情况,比如利用cookie共享的sso策略,可以设置本地host映射到开发服务.设置域名,生效,正常开发. 但在公司中可能是内网,请求都需要经过代理,这时候可能会发现设置h ...
- 洛谷 P6145 【[USACO20FEB]Timeline G】
这道题难就难在建图吧,建图懂了之后,跑一遍最长路就好了(也就是关键路径,但是不会用拓补排序求qnq,wtcl). 怎么建图呢?先不管输入的S,看下面的输入,直接建有向边即可,权值为x.如果现在跑最长路 ...