scentos7安装redis,以及redis的主从配置
redis的安装
下载redis安装包
wget http://download.redis.io/releases/redis-4.0.6.tar.gz
解压压缩包
tar -zxvf redis-4.0.6.tar.gz
yum安装gcc依赖
yum install gcc
跳转到redis解压目录下
cd redis-4.0.6
编译安装
make MALLOC=libc
#将/usr/local/redis-4.0.6/src目录下的文件加到/usr/local/bin目录
cd src && make install
redis安装参考资料:https://www.cnblogs.com/zuidongfeng/p/8032505.html
redis主从同步配置:
1、master服务器需要修改一些配置策略
#绑定ip
bind 0.0.0.0 或者 bind 当前服务器IP #开启守护进程
daemonize no 修改为daemonize yes #关闭保护模式
protected-mode yes 修改为 protected-mode no
2、如果master不设置密码,那么直接在slave服务器配置slaveof即可 配置如下
#slaveof msater_ip msater_port
slaveof 221.224.85.186 6379
3、master设置密码的情况下同步数据,其实很简单,我们只要让slave能连上master就可以了,我们在slave的配置文件中加一句话即可。
#master密码
masterauth 123456
redis主从原理
一、复制过程
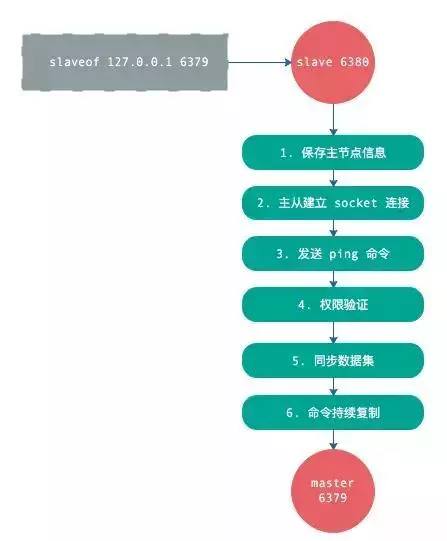
1、从节点执行 slaveof 命令
2、从节点只是保存了 slaveof 命令中主节点的信息,并没有立即发起复制
3、从节点内部的定时任务发现有主节点的信息,开始使用 socket 连接主节点
4、连接建立成功后,发送 ping 命令,希望得到 pong 命令响应,否则会进行重连
5、如果主节点设置了权限,那么就需要进行权限验证;如果验证失败,复制终止。
6、权限验证通过后,进行数据同步,这是耗时最长的操作,主节点将把所有的数据全部发送给从节点。
7、当主节点把当前的数据同步给从节点后,便完成了复制的建立流程。接下来,主节点就会持续的把写命令发送给从节点,保证主从数据一致性。
二、数据间的同步
redis 同步有 2 个命令:
sync 和 psync,前者是 redis 2.8 之前的同步命令,后者是 redis 2.8 为了优化 sync 新设计的命令。我们会重点关注 2.8 的 psync 命令。
psync 命令需要 3 个组件支持:
a、主从节点各自复制偏移量
b、主节点复制积压缓冲区
c、主节点运行 ID
主从节点各自复制偏移量:
1、参与复制的主从节点都会维护自身的复制偏移量。
2、主节点在处理完写入命令后,会把命令的字节长度做累加记录,统计信息在 info replication 中的 masterreploffset 指标中。
3、从节点每秒钟上报自身的的复制偏移量给主节点,因此主节点也会保存从节点的复制偏移量。
4、从节点在接收到主节点发送的命令后,也会累加自身的偏移量,统计信息在 info replication 中。
5、通过对比主从节点的复制偏移量,可以判断主从节点数据是否一致。
主节点复制积压缓冲区:
1、复制积压缓冲区是一个保存在主节点的一个固定长度的先进先出的队列。默认大小 1MB。
2、这个队列在 slave 连接时创建。这时主节点响应写命令时,不但会把命令发送给从节点,也会写入复制缓冲区。
3、他的作用就是用于部分复制和复制命令丢失的数据补救。通过 info replication 可以看到相关信息。
主节点运行 ID:
1、每个 redis 启动的时候,都会生成一个 40 位的运行 ID。
2、运行 ID 的主要作用是用来识别 Redis 节点。如果使用 ip+port 的方式,那么如果主节点重启修改了 RDB/AOF 数据,从节点再基于偏移量进行复制将是不安全的。所以,当运行 id 变化后,从节点将进行全量复制。也就是说,redis 重启后,默认从节点会进行全量复制。
如果在重启时不改变运行 ID 呢?
1、可以通过 debug reload 命令重新加载 RDB 并保持运行 ID 不变。从而有效的避免不必要的全量复制。
2、他的缺点则是:debug reload 命令会阻塞当前 Redis 节点主线程,因此对于大数据量的主节点或者无法容忍阻塞的节点,需要谨慎使用。一般通过故障转移机制可以解决这个问题。
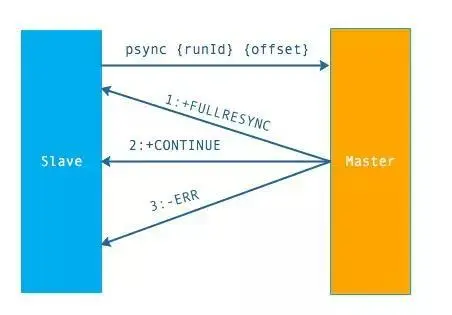
psync 命令的使用方式:
命令格式为 psync{runId}{offset}
runId:从节点所复制主节点的运行
id offset:当前从节点已复制的数据偏移量
psync 执行流程:
流程说明:从节点发送 psync 命令给主节点,runId 就是目标主节点的 ID,如果没有默认为 -1,offset 是从节点保存的复制偏移量,如果是第一次复制则为 -1.
主节点会根据 runid 和 offset 决定返回结果:
1、如果回复 +FULLRESYNC {runId} {offset} ,那么从节点将触发全量复制流程。
2、如果回复 +CONTINUE,从节点将触发部分复制。
3、如果回复 +ERR,说明主节点不支持 2.8 的 psync 命令,将使用 sync 执行全量复制。
4、到这里,数据之间的同步就讲的差不多了,篇幅还是比较长的。主要是针对 psync 命令相关之间的介绍。
三、全量复制
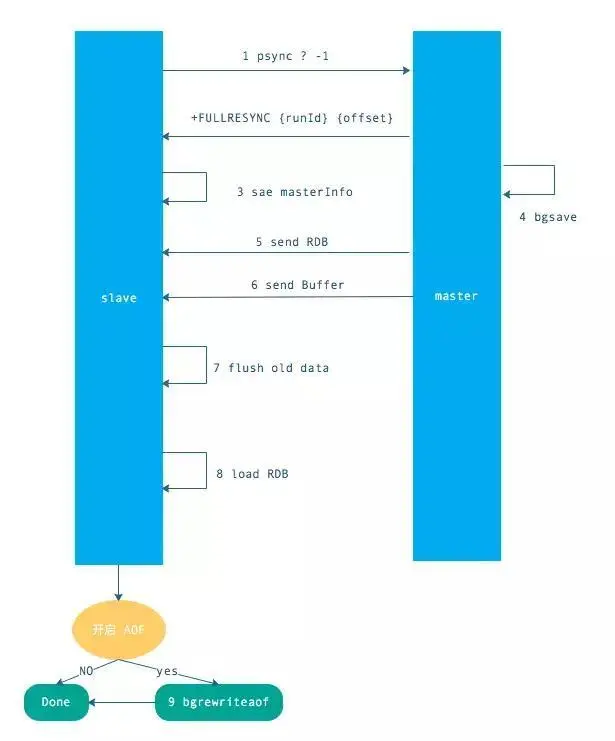
a、发送 psync 命令(spync ? -1)
b、主节点根据命令返回 FULLRESYNC
c、从节点记录主节点 ID 和 offset
d、主节点 bgsave 并保存 RDB 到本地
e、主节点发送 RBD 文件到从节点
f、从节点收到 RDB 文件并加载到内存中
g、主节点在从节点接受数据的期间,将新数据保存到“复制客户端缓冲区”,当从节点加载 RDB 完毕,再发送过去。(如果从节点花费时间过长,将导致缓冲区溢出,最后全量同步失败)
h、从节点清空数据后加载 RDB 文件,如果 RDB 文件很大,这一步操作仍然耗时,如果此时客户端访问,将导致数据不一致,可以使用配置slave-server-stale-data 关闭.
i、从节点成功加载完 RBD 后,如果开启了 AOF,会立刻做 bgrewriteaof。
以上红色的部分是整个全量同步耗时的地方
注意:
1、如过 RDB 文件大于 6GB,并且是千兆网卡,Redis 的默认超时机制(60 秒),会导致全量复制失败。可以通过调大 repl-timeout 参数来解决此问题。
2、Redis 虽然支持无盘复制,即直接通过网络发送给从节点,但功能不是很完善,生产环境慎用。
四、部分复制
1、当从节点正在复制主节点时,如果出现网络闪断和其他异常,从节点会让主节点补发丢失的命令数据
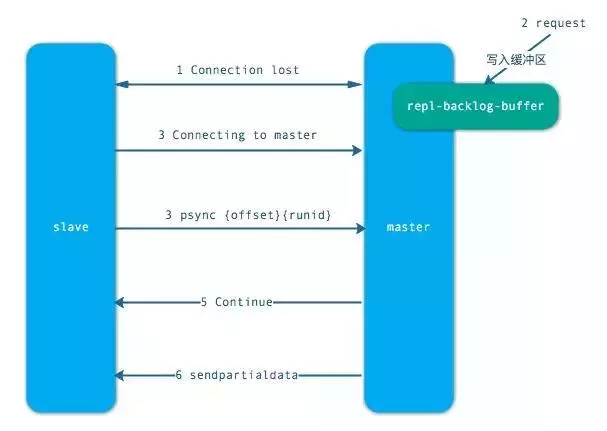
a、当从节点出现网络中断,超过了 repl-timeout 时间,主节点就会中断复制连接。
b、主节点会将请求的数据写入到“复制积压缓冲区”,默认 1MB。
c、当从节点恢复,重新连接上主节点,从节点会将 offset 和主节点 id 发送到主节点
d、主节点校验后,如果偏移量的数后的数据在缓冲区中,就发送 cuntinue 响应 —— 表示可以进行部分复制
e、主节点将缓冲区的数据发送到从节点,保证主从复制进行正常状态。
五、心跳
主从节点在建立复制后,他们之间维护着长连接并彼此发送心跳命令。
心跳的关键机制如下:
1、主从都有心跳检测机制,各自模拟成对方的客户端进行通信,通过 client list 命令查看复制相关客户端信息,主节点的连接状态为 flags = M,从节点的连接状态是 flags = S。
2、主节点默认每隔 10 秒对从节点发送 ping 命令,可修改配置 repl-ping-slave-period 控制发送频率。
3、从节点在主线程每隔一秒发送 replconf ack{offset} 命令,给主节点上报自身当前的复制偏移量。
4、主节点收到 replconf 信息后,判断从节点超时时间,如果超过 repl-timeout 60 秒,则判断节点下线。
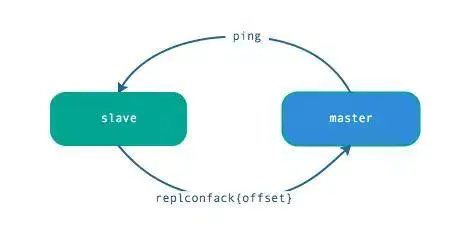
注意:为了降低主从延迟,一般把 redis 主从节点部署在相同的机房/同城机房,避免网络延迟带来的网络分区造成的心跳中断等情况。
六、总结
Redis主从同步策略
1、主从刚刚连接的时候,进行全量同步;
2、全同步结束后,进行增量同步。
3、如果有需要,slave 在任何时候都可以发起全量同步。
4、redis 策略是,无论如何,首先会尝试进行增量同步;
5、不成功,要求从机进行全量同步。
注意点:
1、如果多个Slave断线了,需要重启的时候,因为只要Slave启动,就会发送sync请求和主机全量同步,
2、当多个同时出现的时候,可能会导致Master IO剧增宕机。
主从复制的一些特点:
1)采用异步复制;
2)一个主redis可以含有多个从redis;
3)每个从redis可以接收来自其他从redis服务器的连接;
4)主从复制对于主redis服务器来说是非阻塞的,这意味着当从服务器在进行主从复制同步过程中,主redis仍然可以处理外界的访问请求;
5)主从复制对于从redis服务器来说也是非阻塞的,这意味着,即使从redis在进行主从复制过程中也可以接受外界的查询请求,只不过这时候从redis返回的是以前老的数据,
如果你不想这样,那么在启动redis时,可以在配置文件中进行设置,那么从redis在复制同步过程中来自外界的查询请求都会返回错误给客户端;(虽然说主从复制过程中
对于从redis是非阻塞的,但是当从redis从主redis同步过来最新的数据后还需要将新数据加载到内存中,在加载到内存的过程中是阻塞的,在这段时间内的请求将会被阻,
但是即使对于大数据集,加载到内存的时间也是比较多的);
6)主从复制提高了redis服务的扩展性,避免单个redis服务器的读写访问压力过大的问题,同时也可以给为数据备份及冗余提供一种解决方案;
7)为了编码主redis服务器写磁盘压力带来的开销,可以配置让主redis不在将数据持久化到磁盘,而是通过连接让一个配置的从redis服务器及时的将相关数据持久化到磁盘,
不过这样会存在一个问题,就是主redis服务器一旦重启,因为主redis服务器数据为空,这时候通过主从同步可能导致从redis服务器上的数据也被清空;
主从同步时的几个问题
1)在上面的全量同步过程中,master会将数据保存在rdb文件中然后发送给slave服务器,但是如果master上的磁盘空间有效怎么办呢?那么此时全部同步对于master来说
将是一份十分有压力的操作了。此时可以通过无盘复制来达到目的,由master直接开启一个socket将rdb文件发送给slave服务器。(无盘复制一般应用在磁盘空间有限但是网
络状态良好的情况下) 2)主从复制结构,一般slave服务器不能进行写操作,但是这不是死的,之所以这样是为了更容易的保证主和各个从之间数据的一致性,如果slave服务器上数据进行了修改,
那么要保证所有主从服务器都能一致,可能在结构上和处理逻辑上更为负责。不过你也可以通过配置文件让从服务器支持写操作。(不过所带来的影响还得自己承担哦。。。) 3)主从服务器之间会定期进行通话,但是如果master上设置了密码,那么如果不给slave设置密码就会导致slave不能跟master进行任何操作,所以如果你的master服务器
上有密码,那么也给slave相应的设置一下密码吧(通过设置配置文件中的masterauth); 4)关于slave服务器上过期键的处理,由master服务器负责键的过期删除处理,然后将相关删除命令已数据同步的方式同步给slave服务器,slave服务器根据删除命令删除
本地的key。
当主服务器不能持久化时复制的安全性
在进行主从复制设置时,强烈建议在主服务器上开启持久化,当不能这么做时,比如考虑到延迟的问题,应该将实例配置为避免自动重启。 为什么不持久化的主服务器自动重启非常危险呢?
为了更好的理解这个问题,看下面这个失败的例子,其中主服务器和从服务器中数据库都被删除了。 设置节点A为主服务器,关闭持久化,节点B和C从节点A复制数据。
这时出现了一个崩溃,但Redis具有自动重启系统,重启了进程,因为关闭了持久化,节点重启后只有一个空的数据集。
节点B和C从节点A进行复制,现在节点A是空的,所以节点B和C上的复制数据也会被删除。
当在高可用系统中使用Redis Sentinel,关闭了主服务器的持久化,并且允许自动重启,这种情况是很危险的。
比如主服务器可能在很短的时间就完成了重启,以至于Sentinel都无法检测到这次失败,那么上面说的这种失败的情况就发生了。 如果数据比较重要,并且在使用主从复制时关闭了主服务器持久化功能的场景中,都应该禁止实例自动重启。
只读服务器
从Redis 2.6开始,从服务器支持只读模式,并且是默认模式。这个行为是由Redis.conf文件中的slave-read-only 参数控制的,
可以在运行中通过CONFIG SET来启用或者禁用。 只读的从服务器会拒绝所有写命令,所以对从服务器不会有误写操作。但这不表示可以把从服务器实例暴露在危险的网络环境下,
因为像DEBUG或者CONFIG这样的管理命令还是可以运行的。不过你可以通过使用rename-command命令来为这些命令改名来增加安全性。 你可能想知道为什么只读限制还可以被还原,使得从服务器还可以进行写操作。虽然当主从服务器进行重新同步或者从服务器重启后,
这些写操作都会失效,还是有一些使用场景会想从服务器中写入临时数据的,但将来这个特性可能会被去掉。
限制有N个以上服务器才允许写入
从Redis 2.8版本开始,可以配置主服务器连接N个以上从服务器才允许对主服务器进行写操作。但是,因为Redis使用的是异步主从复制,
没办法确保从服务器确实收到了要写入的数据,所以还是有一定的数据丢失的可能性。 这一特性的工作原理如下:
1)从服务器每秒钟ping一次主服务器,确认处理的复制流数量。
2)主服务器记住每个从服务器最近一次ping的时间。
3)用户可以配置最少要有N个服务器有小于M秒的确认延迟。
4)如果有N个以上从服务器,并且确认延迟小于M秒,主服务器接受写操作。 还可以把这看做是CAP原则(一致性,可用性,分区容错性)不严格的一致性实现,虽然不能百分百确保一致性,但至少保证了丢失的数据不会超过M秒内的数据量。 如果条件不满足,主服务器会拒绝写操作并返回一个错误。
1)min-slaves-to-write(最小从服务器数)
2)min-slaves-max-lag(从服务器最大确认延迟)
scentos7安装redis,以及redis的主从配置的更多相关文章
- Docker安装mysql镜像并进行主从配置
Docker安装mysql镜像并进行主从配置 1.下载需要的mysql版本镜像 docker pull mysql:5.6 2.启动mysql服务实例(基本启动) #启动主mysql docker r ...
- redis集群(主从配置)
市面上太多kv的缓存,最常用的就属memcache了,但是memcache存在单点问题,不过小日本有复制版本,但是使用的人比较少,redis的出现让kv内存存储的想法成为现实.今天主要内容便是redi ...
- Redis集群_主从配置
链接地址http://www.2cto.com/database/201502/377069.html 收藏备用. Redis主从配置(Master-Slave) 一. Redis Replicati ...
- Redis四大模式之主从配置
Redis工作模式主要有单机模式.主从模式(slave).哨兵模式(sentinel).集群模式(cluster)这四种,本文主要讲解一下主从模式的部署方式. 我是windows单机进行的这套搭建操作 ...
- Redis 集群_主从配置_哨兵模式
首先:slaveof 可以在[从]服务器启动一个service服务,直接将[从]服务器定义为[从Redis] redis-server --slaveof <master-ip> < ...
- Redis数据库之服务器主从配置
目的 主要培养对分布式REDIS主从复制架构运用的能力.理解并掌握REPLICATION工作原理的同时,能独立配置Replication ,使数据库运行在主从架格上.针对主从复制架构的运用,着力掌握S ...
- docker安装mysql5.6镜像并进行主从配置
docker安装mysql镜像并进行主从配置 1.去DaoCloud官网(dockerhub可能因为网速问题下载的慢)查找需要的mysql版本镜像 docker pull daocloud.io/li ...
- Redis 安装,主从配置及Sentinel配置自动Failover
1.安装redis 首页地址:http://redis.io/ 下载地址:http://download.redis.io/ 下载最新的源码包 tar -zxvf redis-stable.tar.g ...
- Redis安装及主从配置(转)
一.何为Redis redis是一个key-value存储系统.和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list(链表).set(集合)和zset(有 ...
- Redis安装及主从配置
一.何为Redis redis是一个key-value存储系统.和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list(链表).set(集合)和zset(有 ...
随机推荐
- uniapp使用axios以及封装错误重试解决方案
在uniapp中,使用axios进行请求时,uniapp无法使用axios的适配器,需要基于uni.request来定义适配器. 安装完成axios后在项目utils目录下建一个axios文件夹 文中 ...
- 手机运行Linux系统,可以办公,可以上网,太爽了!
之前用 Termux 编程一直都是在黑乎乎的命令行敲代码,有多少人知道其实可以在手机上用 Termux 构建一个包含桌面环境的 Linux 系统呢. 这个构建出的 linux 系统,可以显示出桌面,可 ...
- 第05组 Alpha冲刺 (3/6)(组长)
.th1 { font-family: 黑体; font-size: 25px; color: rgba(0, 0, 255, 1) } #ka { margin-top: 50px } .aaa11 ...
- Vue+nodejs+npm完美结合入门==vue入门
因为我的是win7系统 64位 只能下载低版本的nodjs: 传送门:https://nodejs.org/dist/v9.7.1/ 一.使用之前,我们先来掌握3个东西是用来干什么的. npm: No ...
- waitpid()系统调用学习
waitpid()的头文件 #include <sys/types.h> #include <sys/wait.h> pid_t waitpid(pid_t pid,int ...
- 在 Kubernetes Ingress 中支持 Websocket/Socket 服务
Kubernetes Ingress 可将集群内部的 Service 通过 HTTP/HTTPS 的方式暴露供外部访问,并通过路径匹配规则定义服务的路由.但是 Ingress 对 TCP/UDP 的服 ...
- nice-ni 耗光cpu
可以看到 低优先级的进程 暂用了比较高的CPU时间. top 命令中可以看到 NI 为19, 其优先级最低 但是使用cpu 最高. 说明这个进程需要经行优化了, 通过gdb 发现此进程一直都在处理报文 ...
- 重看 mb volatile atomic
在单处理器情况下,每条指令的执行都是原子性的,但在多处理器情况下,只有那些单独的读操作或写操作才是原子性的.为了弥补这一缺点,x86提供了附加的lock前缀,使带lock前缀的读修改写指令也能原子性执 ...
- 广度优先遍历&深度优先遍历
一.广度优先算法BFS(Breadth First Search) 基本实现思想 (1)顶点v入队列. (2)当队列非空时则继续执行,否则算法结束. (3)出队列取得队头顶点v: (4)查找顶点v的所 ...
- python 第二天 之循环与判断
人生苦短我用python------这句话说的一点都没有错,python功能真的是太强大了,最主要的节约时间,节约时间对于一个程序员意味着什么?意味着早睡,意味着更多的时间可以干更多的活.少熬了了多少 ...