双汇大数据方案选型:从棘手的InfluxDB+Redis到毫秒级查询的TDengine
双汇发展多个分厂的能源管控大数据系统主要采用两种技术栈:InfluxDB/Redis和Kafka/Redis/HBase/Flink,对于中小型研发团队来讲,无论是系统搭建,还是实施运维都非常棘手。经过对InfluxDB/Redis和TDengine大数据平台的功能和性能对比测试,最终将TDengine作为实施方案。
1. 项目背景
基于双汇发展对能源管控的需求,利用云平台技术以及电气自动化处理手段,对双汇发展的一级、二级、三级能源仪表进行整体改造,实现仪表组网,进一步通过边缘网关进行能源在线监测数据的采集,并上报至云平台,建立统一能源管理信息化系统,实现能源的实时监控、报表统计、能源流向分析与预测,降低企业单位产品能源消耗,提高经济效益,最终实现企业能源精细化管理。
2. 总体架构
能源管控平台基于私有云构建,包括完整的IaaS层、PaaS层和SaaS层,而能源采集系统作为管控平台中最为重要的一环,采用TDengine作为核心数据引擎,通过Restful接口进行仪表在线数据插入,并实现大规模时序数据的高效稳定存储,同时,也为能源管控应用层提供实时数据查询、历史聚合统计、流计算和订阅服务等功能,实现能源地图监控、能耗预警、能源流向预测和能源互联综合决策,具体架构如下图所示。
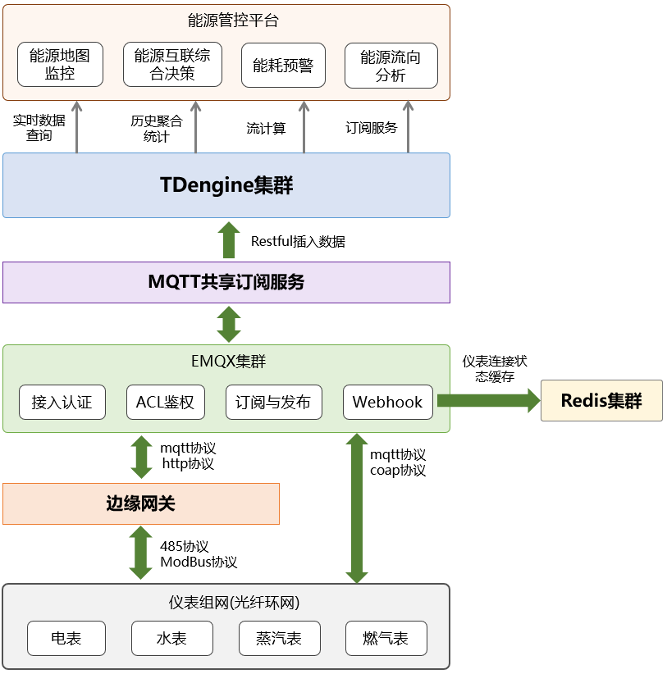 图1 能源采集系统架构
图1 能源采集系统架构
3. TDengine关键应用
3.1 Connector选择
本项目数据采集最关键的环节,就是将订阅到的MQTT数据插入到TDengine中,于是也就涉及到了TDengine连接器的选择,我们平时项目中java使用居多,而且JDBC的性能也相对较强,理论上,应该选择JDBC API,但最终选择了RESTful Connector,主要考虑以下几点:
1)简洁性
毫无疑问,RESTful通用性最强,TDengine直接通过HTTP POST 请求BODY中包含的SQL语句来操作数据库,而且TDengine本身作为时序数据库并不提供存储过程或者事务机制,基本上都是每次执行单条SQL语句,所以RESTful在使用上很简便。
2)可移植性
本项目的Java应用都是部署在Kubernetes中,所以向TDengine插入数据的Java应用需要容器化部署,而之前了解到,JDBC需要依赖的本地函数库libtaos.so文件,所以容器化部署可能较为麻烦,而RESTful仅需采用OKHttp库即可实现,移植性较强。
3)数据规模
本项目数采规模不大,大约每分钟7000条数据,甚至后续数采功能扩展到其他分厂,RESTful也完全满足性能要求。
但总体来讲,JDBC是在插入与查询性能上具有一定优势的,而且支持从firstEp和secondEp选择有效节点进行连接(类似于Nginx的keepalive高可用),目前TDengine版本发布情况上看,JDBC的维护与提升也是重中之重,后续项目也可能会向JDBC迁移。
3.2 RESTful代码实现
1)ThreadPoolExecutor线程池
订阅EMQX和RESTful插入TDengine的代码写在了同一个java服务中,每接收到一条MQTT订阅消息,便开启一个线程向TDengine插入数据,线程均来自于线程池,初始化如下:
ExecutorService pool =newThreadPoolExecutor(150,300,1000,TimeUnit.MILLISECONDS,newArrayBlockingQueue<Runnable>(100),Executors.defaultThreadFactory(),newThreadPoolExecutor.DiscardOldestPolicy());
线程池采用基于数组的先进先出队列,采用丢弃早期任务的拒绝策略,因为本次场景中单次RESTful插入数据量大约在100~200条,执行速度快,迟迟未执行完极可能是SQL语句异常或连接taosd服务异常等原因,应该丢弃任务。核心线程数设为150,相对较高,主要为了保证高峰抗压能力。
2)OKHttp线程池
在每个ThreadPoolExecutor线程中,基于OKHttp库进行RESTful插入操作,也是采用ConnectionPool管理 HTTP 和 HTTP/2 连接的重用,以减少网络延迟,OKHttp重点配置如下:
publicConnectionPool pool(){returnnewConnectionPool(20,5,TimeUnit.MINUTES);}
即最大空闲连接数为20,每个连接最大空闲时间为5分钟,每个OKHttp插入操作采用异步调用方式,主要代码如下:
publicvoid excuteTdengineWithSqlAsync(String sql,Callback callback){try{okhttp3.MediaType mediaType = okhttp3.MediaType.parse("application/octet-stream");RequestBody body =RequestBody.create(mediaType, sql);Request request =newRequest.Builder().url(tdengineHost).post(body).addHeader("Authorization","Basic cm9vdDp0YW9zZGF0YQ==").addHeader("cache-control","no-cache").build();mOkHttpClient.newCall(request).enqueue(callback);}catch(Exception e){logger.error("执行tdengine操作报错:"+ e.getMessage());}}
3)Java打包镜像
长期压力测试显示,每秒执行200次RESTful插入请求,单次请求包含100条数据,每条数据包含5组标签,Java服务内存稳定在300M~600M。而且上述模拟规模仅针对单个Java应用而言,在Kubernetes可以跑多个这样pod来消费不同的MQTT主题,所以并发能力完全够用。打包镜像时,堆内存最大值设为1024MB,主要语句为:
ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom","-XX:MaxRAM=2000m","-Xms1024m","-jar","/app.jar"]
3.3 性能测试
1)RESTful插入性能
按照3.2小节中的RESTful代码进行数据插入,Java程序和TDengine集群均运行在私有云中,虚拟机之间配备万兆光纤交换机,Java程序具体如3.2小节所示,TDengine集群部署在3个虚拟机中,配置均为1TB硬盘、12核、12GB(私有云中CPU比较充裕,但内存比较紧张),经过大约三周的生产环境运行,性能总结如下:
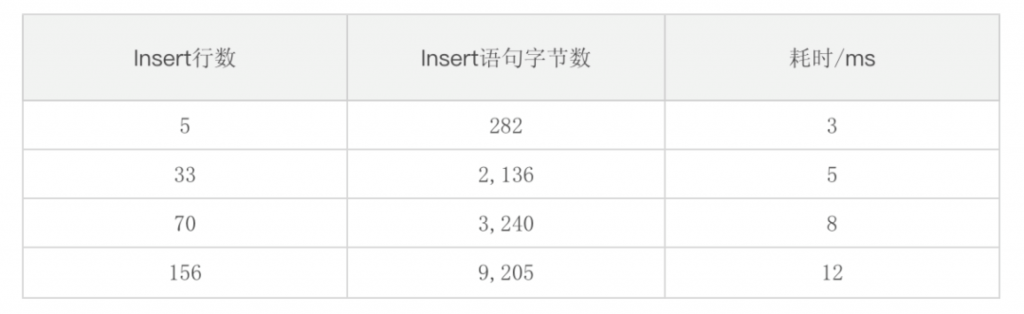 表1 生产环境下RESTful插入性能测试
表1 生产环境下RESTful插入性能测试
生产环境下,单条插入性能极高,完全满足需求,当然前期也进行过稍大规模的插入场景模拟,主要是基于2.0.4.0以后的版本,注意到2.0.4.0之前的TDengine版本RESTful的SQL语句上限为64KB。模拟环境下,RESTful插入性能非常优秀,具体如下表所示。
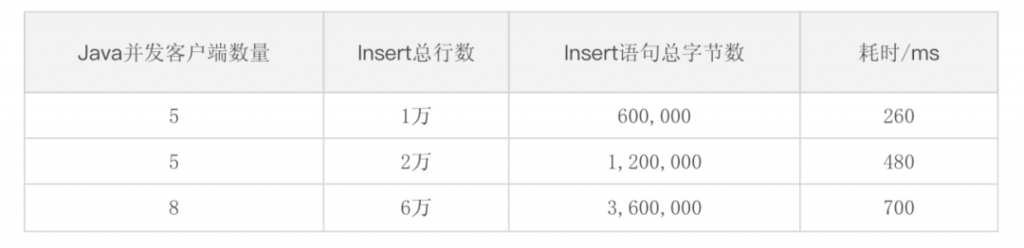 表2 模拟环境下RESTful插入性能测试
表2 模拟环境下RESTful插入性能测试
2)RESTful查询性能
使用RESTful进行SQL查询时,性能也是非常好,目前真实生产环境中,数据总量为800万,相对单薄,所以查询性能测试在模拟环境下进行,在8亿数据量下,LAST_ROW函数可以达到10ms响应速度,count、interval、group by等相关函数执行速度均在百毫秒量级上。
3.4 实施方案
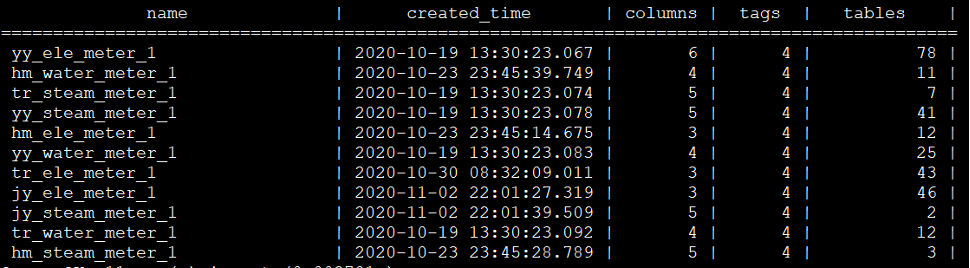
本项目针对双汇发展下属的6个分厂(后续会继续扩充)进行能源数据采集,大约1200多块仪表(后续会继续扩充),每块仪表包括3至5个采集标签,采集频率均为1分钟,数据接入规模不大。六个厂各自有独立的租户空间,为了方便各自的时序数据库管理,同时也方便各厂间的聚合查询(目前六个分厂均从属双汇发展总部),所以各分厂分别建立超级表,每个超级表包括4个tag,分别为厂编号、仪表级别、所属工序和仪表编号,具体超级表建表情况如下图所示。
主要用到的集群包括TDengine集群、EMQX集群和Redis集群,其中Redis集群在数据采集方面,仅仅用于缓存仪表连接状态,其重点在于缓存业务系统数据;EMQX集群用于支撑MQTT数据的发布与订阅,部署在Kubernetes中,可以实现资源灵活扩展;TDengine集群部署在IaaS虚拟机中,支持大规模时序数据的存储与查询。
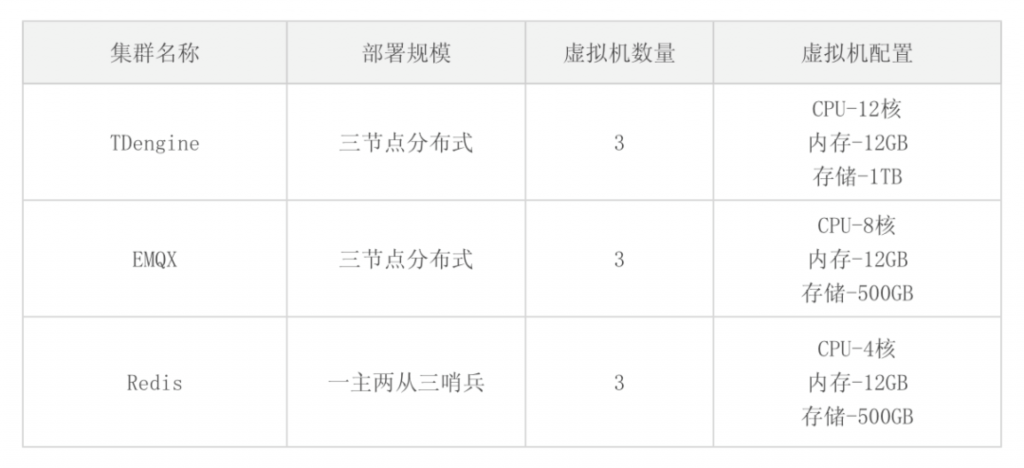 表3 集群配置信息
表3 集群配置信息
按照TDengine官方的建议,“一个数据采集点一张表,同一类型数据采集点一张超级表”,我针对不同分厂的水表、电表、蒸汽表和燃气表分别建立的超级表,每个仪表单独建表,保证每张表的时间戳严格递增。在实践TDengine的过程中,重点体会如下:
1)集群搭建门槛低
TDengine集群安装部署非常便捷,尤其相比于其他集群,仅需要简单的配置就可以实现生产环境级的搭建,官方文档也比较丰富,社区活跃,也大为降低了后续运维成本。
2)插入与查询效率极高
TDengine的插入与查询性能极高,这点在实际运行时也深有感触,用last_row函数查询仪表最新数据,基本上可以达到毫秒级,在几十亿级的数据上进行聚合查询操作,也可达到百毫秒级,极大提供了系统的响应速度。
3)全栈式时序处理引擎
在未使用TDengine之前,我们主要采用InfluxDB/Redis和Kafka/Redis/HBase/Flink两种技术栈,对于我们中小型研发团队来讲,无论是系统搭建,还是实施运维都非常棘手。但是使用TDengine后,一切都简化了,TDengine将数据库、消息队列、缓存、流式计算等功能融合一起,以一种全栈的方式,为我们的大数据系统带来了便捷。技术方案的对比如表4所示。
注:方案一为InfluxDB/Redis,方案二为Kafka/Redis/HBase/Flink,方案三为TDengine
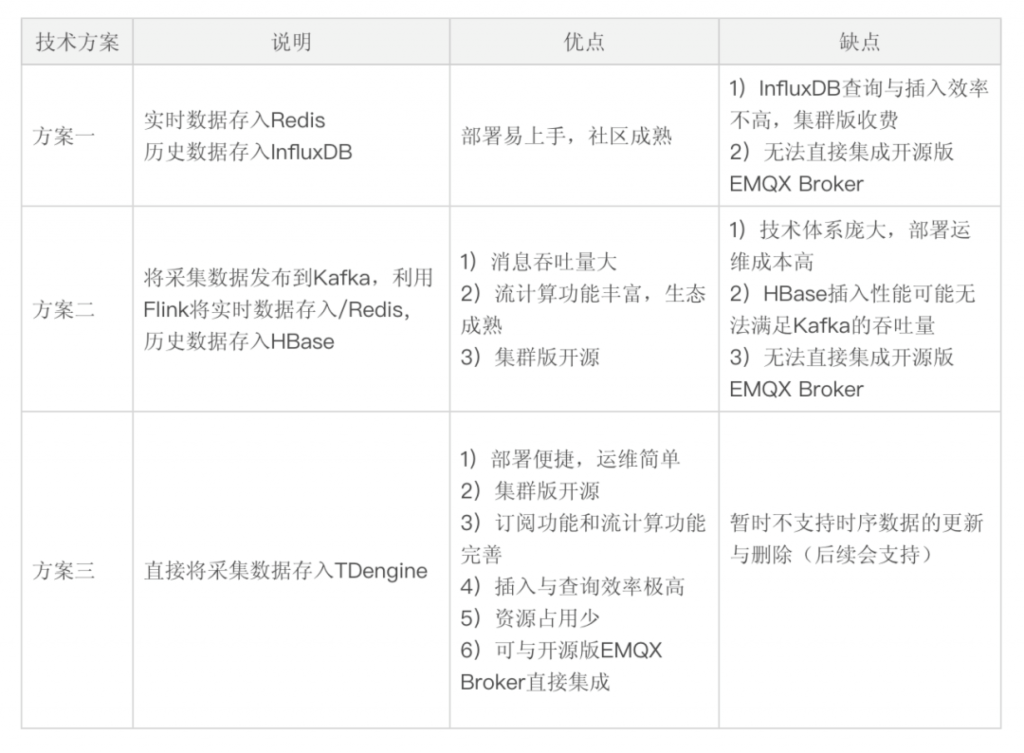 表4 数据采集方案对比
表4 数据采集方案对比
从表4的对比方案中可以看出,TDengine(方案三)是有着很大的优势,尤其在开源EMQX Broker的支持上也非常好(主要依赖于Restful接口),其他的例如Kafka和InfluxDB只能和企业版EMQX集成;在数据插入和查询效率方面,上述三种方案关键在于TDengine、HBase和InfluxDB的对比,官网有非常详细的测试报告,TDengine也是有绝对优势,这里就不过多叙述。所以选择TDengine是势在必行的。
3.5 技术期望
在时序数据库性能方面,TDengine有着很大的优势,并且也集成了消息订阅和流计算功能,可以说在中小型物联场景下,是无需部署Kafka和Flink的。当然个人理解TDengine不是为了完全取代Kafka和Flink而生的,尤其是在大型云服务项目中,更多是共存。
但是在边缘端,TDengine凭借着极低的资源占用率和优秀的时序处理性能,将会产生更大的能量,期望能彻底集成边缘流计算和MQTT broker等功能,扩充Modbus、OPC-UA等常见工业协议支持,向下连接工业设备或者物联设施,向上和边缘Kubernetes生态(如KubeEdge、K3S等)协同,或者直接和云中心协同。
3.6 系统运行界面
项目重点是能耗统计,而在线采集到TDengine里的数据都是累计量,所以在计算能耗时,需要在不同的超级表执行按表分组、按时间周期采样的查询,类似下面语法:
selectlast(累计列)as max_val,first(累计列)as min_val from[超级表名]where[标签栏相关过滤]and ts>=now-10h INTERVAL(1h)groupby[仪表编号];
得益于TDengine的极佳性能,基本能保证不超过百毫秒的访问延时,下面是一些相关的PC端、移动端界面(我们移动端是用H5做的,为了直接能跑在Android和iOS上)。
写在最后
其实从2019年开始就一直在关注TDengine,也看了很多陶总的演讲,受益匪浅,尤其在今年8月份,TDengine进行了集群版开源,也正好准备启动能源数据采集项目,所以果断采用TDengine作为核心时序引擎,目前也是收获了非常的效果。本次项目实施过程中,尤其感谢涛思数据的苏晓慰工程师,多次协助解决TDengine相关的实施问题。计划在后续其他项目也也会继续推广TDengine,同时也愿意为一些商业版功能付费,支持国产,支持涛思。
作者介绍
于淼,学历硕士,副研究员,主要从事MES系统研发以及智能制造相关理论和标准研究,主要研究方向:数字工厂使能技术、制造执行系统关键技术和智能制造标准体系等,参与国家级项目及企业项目十余项,包括国家重点研发计划以及国家智能制造专项等。
双汇发展多个分厂的能源管控大数据系统主要采用两种技术栈:InfluxDB/Redis和Kafka/Redis/HBase/Flink,对于中小型研发团队来讲,无论是系统搭建,还是实施运维都非常棘手。经过对InfluxDB/Redis和TDengine大数据平台的功能和性能对比测试,最终将TDengine作为实施方案。
### 项目背景基于双汇发展对能源管控的需求,利用云平台技术以及电气自动化处理手段,对双汇发展的一级、二级、三级能源仪表进行整体改造,实现仪表组网,进一步通过边缘网关进行能源在线监测数据的采集,并上报至云平台,建立统一能源管理信息化系统,实现能源的实时监控、报表统计、能源流向分析与预测,降低企业单位产品能源消耗,提高经济效益,最终实现企业能源精细化管理。
### 总体架构能源管控平台基于私有云构建,包括完整的IaaS层、PaaS层和SaaS层,而能源采集系统作为管控平台中最为重要的一环,采用TDengine作为核心数据引擎,通过Restful接口进行仪表在线数据插入,并实现大规模时序数据的高效稳定存储,同时,也为能源管控应用层提供实时数据查询、历史聚合统计、流计算和订阅服务等功能,实现能源地图监控、能耗预警、能源流向预测和能源互联综合决策,具体架构如下图所示。### TDengine关键应用#### Connector选择
本项目数据采集最关键的环节,就是将订阅到的MQTT数据插入到TDengine中,于是也就涉及到了TDengine连接器的选择,我们平时项目中java使用居多,而且JDBC的性能也相对较强,理论上,应该选择JDBC API,但最终选择了RESTful Connector,主要考虑以下几点:
**1)简洁性**
毫无疑问,RESTful通用性最强,TDengine直接通过HTTP POST 请求BODY中包含的SQL语句来操作数据库,而且TDengine本身作为时序数据库并不提供存储过程或者事务机制,基本上都是每次执行单条SQL语句,所以RESTful在使用上很简便。
**2)可移植性**
本项目的Java应用都是部署在Kubernetes中,所以向TDengine插入数据的Java应用需要容器化部署,而之前了解到,JDBC需要依赖的本地函数库libtaos.so文件,所以容器化部署可能较为麻烦,而RESTful仅需采用OKHttp库即可实现,移植性较强。
**3)数据规模**
本项目数采规模不大,大约每分钟7000条数据,甚至后续数采功能扩展到其他分厂,RESTful也完全满足性能要求。
但总体来讲,JDBC是在插入与查询性能上具有一定优势的,而且支持从firstEp和secondEp选择有效节点进行连接(类似于Nginx的keepalive高可用),目前TDengine版本发布情况上看,JDBC的维护与提升也是重中之重,后续项目也可能会向JDBC迁移。
#### RESTful代码实现
**1)ThreadPoolExecutor线程池**
订阅EMQX和RESTful插入TDengine的代码写在了同一个java服务中,每接收到一条MQTT订阅消息,便开启一个线程向TDengine插入数据,线程均来自于线程池,初始化如下:
```ExecutorService pool = new ThreadPoolExecutor(150, 300, 1000, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<Runnable>(100), Executors.defaultThreadFactory(),new ThreadPoolExecutor.DiscardOldestPolicy());```
线程池采用基于数组的先进先出队列,采用丢弃早期任务的拒绝策略,因为本次场景中单次RESTful插入数据量大约在100~200条,执行速度快,迟迟未执行完极可能是SQL语句异常或连接taosd服务异常等原因,应该丢弃任务。核心线程数设为150,相对较高,主要为了保证高峰抗压能力。
**2)OKHttp线程池**
在每个ThreadPoolExecutor线程中,基于OKHttp库进行RESTful插入操作,也是采用ConnectionPool管理 HTTP 和 HTTP/2 连接的重用,以减少网络延迟,OKHttp重点配置如下:
```public ConnectionPool pool() { return new ConnectionPool(20, 5, TimeUnit.MINUTES);}```
即最大空闲连接数为20,每个连接最大空闲时间为5分钟,每个OKHttp插入操作采用异步调用方式,主要代码如下:
```public void excuteTdengineWithSqlAsync(String sql,Callback callback) { try{ okhttp3.MediaType mediaType = okhttp3.MediaType.parse("application/octet-stream"); RequestBody body = RequestBody.create(mediaType, sql); Request request = new Request.Builder() .url(tdengineHost) .post(body) .addHeader("Authorization", "Basic cm9vdDp0YW9zZGF0YQ==") .addHeader("cache-control", "no-cache") .build(); mOkHttpClient.newCall(request).enqueue(callback); } catch (Exception e) { logger.error("执行tdengine操作报错:"+ e.getMessage()); }}```
**3)Java打包镜像**
长期压力测试显示,每秒执行200次RESTful插入请求,单次请求包含100条数据,每条数据包含5组标签,Java服务内存稳定在300M~600M。而且上述模拟规模仅针对单个Java应用而言,在Kubernetes可以跑多个这样pod来消费不同的MQTT主题,所以并发能力完全够用。打包镜像时,堆内存最大值设为1024MB,主要语句为:
```ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom","-XX:MaxRAM=2000m","-Xms1024m","-jar","/app.jar"]```
#### 性能测试
**1)RESTful插入性能**
按照3.2小节中的RESTful代码进行数据插入,Java程序和TDengine集群均运行在私有云中,虚拟机之间配备万兆光纤交换机,Java程序具体如3.2小节所示,TDengine集群部署在3个虚拟机中,配置均为1TB硬盘、12核、12GB(私有云中CPU比较充裕,但内存比较紧张),经过大约三周的生产环境运行,性能总结如下:
表1 生产环境下RESTful插入性能测试| Insert 行数| Insert 语句字节数 | 耗时/ms||--|--|--||5 | 282 |3||33 | 2,136 |5||70 | 3,240 |8||156 | 9,205 |12|
生产环境下,单条插入性能极高,完全满足需求,当然前期也进行过稍大规模的插入场景模拟,主要是基于2.0.4.0以后的版本,注意到2.0.4.0之前的TDengine版本RESTful的SQL语句上限为64KB。模拟环境下,RESTful插入性能非常优秀,具体如下表所示。
表2 模拟环境下RESTful插入性能测试|Java 并发客户端数量| Insert 行数| Insert 语句字节数 | 耗时/ms||--|--|--|--||5 | 1万 |600,000|260||5 | 2万 |1,200,000|480||8 | 6万 |3,600,000|700|
**2)RESTful查询性能**
使用RESTful进行SQL查询时,性能也是非常好,目前真实生产环境中,数据总量为800万,相对单薄,所以查询性能测试在模拟环境下进行,在8亿数据量下,LAST_ROW函数可以达到10ms响应速度,count、interval、group by等相关函数执行速度均在百毫秒量级上。
#### 实施方案
本项目针对双汇发展下属的6个分厂(后续会继续扩充)进行能源数据采集,大约1200多块仪表(后续会继续扩充),每块仪表包括3至5个采集标签,采集频率均为1分钟,数据接入规模不大。六个厂各自有独立的租户空间,为了方便各自的时序数据库管理,同时也方便各厂间的聚合查询(目前六个分厂均从属双汇发展总部),所以各分厂分别建立超级表,每个超级表包括4个tag,分别为厂编号、仪表级别、所属工序和仪表编号,具体超级表建表情况如下图所示。
主要用到的集群包括TDengine集群、EMQX集群和Redis集群,其中Redis集群在数据采集方面,仅仅用于缓存仪表连接状态,其重点在于缓存业务系统数据;EMQX集群用于支撑MQTT数据的发布与订阅,部署在Kubernetes中,可以实现资源灵活扩展;TDengine集群部署在IaaS虚拟机中,支持大规模时序数据的存储与查询。
表3 集群配置信息|集群名称|部署规模|虚拟机数量| 虚拟机配置|--|--|--|--||TDengine|三节点分布式|3|CPU-12核 内存-12GB 存储-1TB|EMQX|三节点分布式|3|CPU-8核 内存-12GB 存储-500GB|Redis|一主两从三哨兵|3|CPU-4核 内存-12GB 存储-500GB
按照TDengine官方的建议,“一个数据采集点一张表,同一类型数据采集点一张超级表”,我针对不同分厂的水表、电表、蒸汽表和燃气表分别建立的超级表,每个仪表单独建表,保证每张表的时间戳严格递增。在实践TDengine的过程中,重点体会如下:
**1)集群搭建门槛低**
TDengine集群安装部署非常便捷,尤其相比于其他集群,仅需要简单的配置就可以实现生产环境级的搭建,官方文档也比较丰富,社区活跃,也大为降低了后续运维成本。
**2)插入与查询效率极高**
TDengine的插入与查询性能极高,这点在实际运行时也深有感触,用last_row函数查询仪表最新数据,基本上可以达到毫秒级,在几十亿级的数据上进行聚合查询操作,也可达到百毫秒级,极大提供了系统的响应速度。
**3)全栈式时序处理引擎**
在未使用TDengine之前,我们主要采用InfluxDB/Redis和Kafka/Redis/HBase/Flink两种技术栈,对于我们中小型研发团队来讲,无论是系统搭建,还是实施运维都非常棘手。但是使用TDengine后,一切都简化了,TDengine将数据库、消息队列、缓存、流式计算等功能融合一起,以一种全栈的方式,为我们的大数据系统带来了便捷。技术方案的对比如表4所示。
注:方案一为InfluxDB/Redis,方案二为Kafka/Redis/HBase/Flink,方案三为TDengine
表4 数据采集方案对比|技术方案|说明|优点|缺点|--|--|--|--||方案一|实时数据存入Redis 历史数据存入InfluxDB|部署易上手,社区成熟|1)InfluxDB查询与插入效率不高,集群版收费 2)无法直接集成开源版EMQX Broker|方案二|将采集数据发布到Kafka,利用Flink将实时数据存入/Redis,历史数据存入HBase|1)消息吞吐量大 2)流计算功能丰富,生态成熟 3)集群版开源|1)技术体系庞大,部署运维成本高 2)HBase插入性能可能无法满足Kafka的吞吐量 3)无法直接集成开源版EMQX Broker|方案三|直接将采集数据存入TDengine|1)部署便捷,运维简单 2)集群版开源 3)订阅功能和流计算功能完善 4)插入与查询效率极高 5)资源占用少 6)可与开源版EMQX Broker直接集成|暂时不支持时序数据的更新与删除(后续会支持)
从表4的对比方案中可以看出,TDengine(方案三)是有着很大的优势,尤其在开源EMQX Broker的支持上也非常好(主要依赖于Restful接口),其他的例如Kafka和InfluxDB只能和企业版EMQX集成;在数据插入和查询效率方面,上述三种方案关键在于TDengine、HBase和InfluxDB的对比,官网有非常详细的测试报告,TDengine也是有绝对优势,这里就不过多叙述。所以选择TDengine是势在必行的。
#### 技术期望
在时序数据库性能方面,TDengine有着很大的优势,并且也集成了消息订阅和流计算功能,可以说在中小型物联场景下,是无需部署Kafka和Flink的。当然个人理解TDengine不是为了完全取代Kafka和Flink而生的,尤其是在大型云服务项目中,更多是共存。
但是在边缘端,TDengine凭借着极低的资源占用率和优秀的时序处理性能,将会产生更大的能量,期望能彻底集成边缘流计算和MQTT broker等功能,扩充Modbus、OPC-UA等常见工业协议支持,向下连接工业设备或者物联设施,向上和边缘Kubernetes生态(如KubeEdge、K3S等)协同,或者直接和云中心协同。
#### 系统运行界面
项目重点是能耗统计,而在线采集到TDengine里的数据都是累计量,所以在计算能耗时,需要在不同的超级表执行按表分组、按时间周期采样的查询,类似下面语法:```select last(累计列) as max_val,first(累计列) as min_val from [超级表名] where [标签栏相关过滤] and ts>=now-10h INTERVAL(1h) group by [仪表编号] ;```得益于TDengine的极佳性能,基本能保证不超过百毫秒的访问延时,下面是一些相关的PC端、移动端界面(我们移动端是用H5做的,为了直接能跑在Android和iOS上)。### 写在最后其实从2019年开始就一直在关注TDengine,也看了很多陶总的演讲,受益匪浅,尤其在今年8月份,TDengine进行了集群版开源,也正好准备启动能源数据采集项目,所以果断采用TDengine作为核心时序引擎,目前也是收获了非常的效果。本次项目实施过程中,尤其感谢涛思数据的苏晓慰工程师,多次协助解决TDengine相关的实施问题。计划在后续其他项目也也会继续推广TDengine,同时也愿意为一些商业版功能付费,支持国产,支持涛思。
### 作者介绍于淼,学历硕士,副研究员,主要从事MES系统研发以及智能制造相关理论和标准研究,主要研究方向:数字工厂使能技术、制造执行系统关键技术和智能制造标准体系等,参与国家级项目及企业项目十余项,包括国家重点研发计划以及国家智能制造专项等。
双汇大数据方案选型:从棘手的InfluxDB+Redis到毫秒级查询的TDengine的更多相关文章
- 低调、奢华、有内涵的敏捷式大数据方案:Flume+Cassandra+Presto+SpagoBI
基于FacebookPresto+Cassandra的敏捷式大数据 文件夹 1 1.1 1.1.1 1.1.2 1.2 1.2.1 1.2.2 2 2.1 2.2 2.3 2.4 2.5 2.6 3 ...
- spark + cassandra +postgres +codis 大数据方案
1.环境: 1.1.cassandra 集群: 用于日志数据存储 1.2.spark集群: 用户后期的实时计算及批处理 1.3.codis 集群: 用于缓存一些基本数据如IP归属地,IP经纬度等,当日 ...
- (已实现)相似度到大数据查找之Mysql 文章匹配的一些思路与提高查询速度
需求,最近实现了文章的原创度检测功能,处理思路一是分词之后做搜索引擎匹配飘红,另一方面是量化词组,按文章.段落.句子做数据库查询,功能基本满足实际需求. 接下来,还需要在海量大数据中快速的查找到与一句 ...
- 一个大数据方案:基于Nutch+Hadoop+Hbase+ElasticSearch的网络爬虫及搜索引擎
网络爬虫架构在Nutch+Hadoop之上,是一个典型的分布式离线批量处理架构,有非常优异的吞吐量和抓取性能并提供了大量的配置定制选项.由于网络爬虫只负责网络资源的抓取,所以,需要一个分布式搜索引擎, ...
- mysql大数据量使用limit分页,随着页码的增大,查询效率越低下
1. 直接用limit start, count分页语句, 也是我程序中用的方法: select * from product limit start, count当起始页较小时,查询没有性能问题 ...
- 相似度到大数据查找之Mysql 文章匹配的一些思路与提高查询速度
文章相关度匹配的一些思路---"压缩"预料库,即提取用特征词或词频,量化后以“列向量”形式保存到数据库:按前N组词拼为向量组供查询使用,即组合为1到N字的组合,量化后以“行向量”形 ...
- 三【相关度 相似度查询与计算】相似度到大数据查找之Mysql 文章匹配的一些思路与提高查询速度
记录下,在上2回的数据基础之上,附带一个互信息(MI,Mutual Information)可以计算词之间的相关度 标准互信息 MI(X,Y)=log2p(x,y)/p(x)p(y) 值越大于0 则趋 ...
- MySQL 大数据量使用limit分页,随着页码的增大,查询效率越低下。
数据表结构 CREATE TABLE `ad_keyword` ( `id` int(11) NOT NULL AUTO_INCREMENT, `plan_goods_id` int(11) DEFA ...
- 论各类BI工具的“大数据”特性!
市面上的BI工具形形色色,功能性能包装得十分亮丽,但实际应用中我们往往更关注的是朴实的技术特性和解决方案.对于大数据,未来的应用趋势不可抵挡,很多企业也正存在大数据分析处理展现的需求,以下我们列举市面 ...
随机推荐
- JSX 详解
一 jsx 的本质是什么? jsx是语法糖,需要被编译成js才能运行. jsx 看似是html 结构,实质是js结构的语法糖,在代码编译阶段被编译成js结构.所以jsx的本质可描述为看似html结构的 ...
- 租房数据分析,knn算法使用
import numpy as np import pandas as pd import matplotlib.pyplot as plt data = pd.read_excel('jiemo.x ...
- jmeter_02_目录文档说明
jmeter目录文档说明 bin目录是可执行文件 jmeter.bat 是启动文件 可以启动jmeter. 使用notpad++ 等文本编辑器打开 bat文件 可以配置jvm的参数 比如堆内存[Hea ...
- centos8安装java jdk 13
一,查看本地centos的版本 [root@localhost lib]# cat /etc/redhat-release CentOS Linux release 8.1.1911 (Core) 说 ...
- lumen laravel response对象返回数据
Route::get('home', function () { $content = "内容"; $status = 301; $value = 'text/html'; // ...
- zookeeper动态添加/删除集群中实例(zookeeper 3.6)
一,用来作为demo操作的zookeeper集群中的实例: 机器名:zk1 server.1=172.18.1.1:2888:3888 机器名:zk2 server.2=172.18.1.2:2888 ...
- OpenCV(c++)-1 安装和配置OpenCV4.4(Windows+visual studio 2019)
@ 目录 安装OpenCV4 在Windows系统安装OpenCV4 配置visual studio 2019 配置包含路径 验证配置结果 安装OpenCV4 OpenCV是一个基于BSD许可(开源) ...
- Lombda表达式(五)
public class Test05 { /* * lambda表达式是用来简化匿名内部类的一种函数式编程的语法. * 只有SAM接口才能使用lambda表达式 * 方法引用和构造器引用是用来简化l ...
- 支持向量机SVM基本问题
1.SVM的原理是什么? SVM是一种二类分类模型.它的基本模型是在特征空间中寻找间隔最大化的分离超平面的线性分类器.(间隔最大是它有别于感知机) 试图寻找一个超平面来对样本分割,把样本中的正例和反例 ...
- JAVA NIO 基础学习
package com.hrd.netty.demo.jnio; import java.io.BufferedReader; import java.io.IOException; import j ...