Spark运行模式_local(本地模式)
本地运行模式 (单机)
- 该模式被称为Local[N]模式,是用单机的多个线程来模拟Spark分布式计算,直接运行在本地,便于调试,通常用来验证开发出来的应用程序逻辑上有没有问题。
- 其中N代表可以使用N个线程,每个线程拥有一个core。如果不指定N,则默认是1个线程(该线程有1个core)。
- 如果是local[*],则代表 Run Spark locally with as many worker threads as logical cores on your machine.


那么,这些线程都运行在什么进程下呢?
运行该模式非常简单,只需要把Spark的安装包解压后,改一些常用的配置即可使用,而不用启动Spark的Master、Worker守护进程( 只有集群的Standalone方式时,才需要这两个角色),也不用启动Hadoop的各服务(除非你要用到HDFS),这是和其他模式的区别哦,要记住才能理解。
那么,这些执行任务的线程,到底是共享在什么进程中呢?
我们用如下命令提交作业:

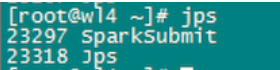
这个SparkSubmit进程又当爹、又当妈,既是客户提交任务的Client进程、又是Spark的driver程序、还充当着Spark执行Task的Executor角色。(如下图所示:driver的web ui)

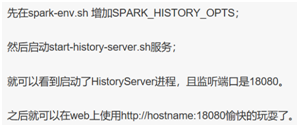
这里有个小插曲,因为driver程序在应用程序结束后就会终止,那么如何在web界面看到该应用程序的执行情况呢,需要如此这般:(如下图所示)

转载自:
作者:俺是亮哥
链接:https://www.jianshu.com/p/65a3476757a5
來源:简书
Spark运行模式_local(本地模式)的更多相关文章
- Windows下nodejs 模块配置 全局模式与本地模式的区别
第1步:下载.安装文件 (nodejs的官网http://www.nodejs.org/download/ ) 第2步:安装相关模块环境 打开C:\Program Files\nodejs 目录你会发 ...
- 啃掉Hadoop系列笔记(03)-Hadoop运行模式之本地模式
Hadoop的本地模式为Hadoop的默认模式,不需要启用单独进程,直接可以运行,测试和开发时使用. 在<啃掉Hadoop系列笔记(02)-Hadoop运行环境搭建>中若环境搭建成功,则直 ...
- Hadoop运行模式:本地模式、伪分布模式、完全分布模式
1.本地模式:默认模式 - 不对配置文件进行修改. - 使用本地文件系统,而不是分布式文件系统. - Hadoop不会启动NameNode.DataNode.ResourceManager.NodeM ...
- Hive的三种安装方式(内嵌模式,本地模式远程模式)
一.安装模式介绍: Hive官网上介绍了Hive的3种安装方式,分别对应不同的应用场景. 1.内嵌模式(元数据保村在内嵌的derby种,允许一个会话链接,尝试多个会话链接时会报错) ...
- Spark运行模式与Standalone模式部署
上节中简单的介绍了Spark的一些概念还有Spark生态圈的一些情况,这里主要是介绍Spark运行模式与Spark Standalone模式的部署: Spark运行模式 在Spark中存在着多种运行模 ...
- 【node.js】本地模式安装express:'express' 不是内部或外部命令,也不是可运行的程序或批处理文件。
今天闲来无事想起了node.js,因此到网上下载了一个node.js的安装程序进行安装.其中: 安装程序:node-v0.11.13-x64.msi PC系统:Windows 7 自定义安装路径:D: ...
- 55.storm 之 hello word(本地模式)
strom hello word 概述 然后卡一下代码怎么实现的: 编写数据源类:Spout.可以使用两种方式: 继承BaseRichSpout类 实现IRichSpout接口 主要需要实现或重写几个 ...
- hadoop的安装和配置(一)本地模式
博主会用三篇文章来为大家详细的说明hadoop的三种模式: 本地模式 伪分布模式 完全分布模式 本地模式: 思路走向 |--------------------| | ①:配置Java环境 | | ...
- spark 运行架构
spark 运行架构基本由三部分组成,包括SparkContext(驱动程序),ClusterManager(集群资源管理器)和Executor(任务执行过程)组成. 其中SparkContext负责 ...
- Scala进阶之路-Spark本地模式搭建
Scala进阶之路-Spark本地模式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Spark简介 1>.Spark的产生背景 传统式的Hadoop缺点主要有以下两 ...
随机推荐
- layui分页
毕业已经两年,期间经历了很多.一个人欢笑与哭泣,在墙角.在路边.在床上.每天搭乘首班车来到公司,每天无数次反省自己,每天每天再问自己为什么活着. 一.下载并引用css和js 地址:点我 <lin ...
- Win10安装msi程序报错2503和2502错误解决方案
刚升级了系统到win10,重新搭建开发环境,在安装scala的时候一直报2503.2502错误,如图 试了好几种办法都不好使,现在罗列依次用到的三种方法: 一.命令提示符(管理员)启动 "w ...
- 条件独立(conditional independence) 结合贝叶斯网络(Bayesian network) 概率有向图 (PRML8.2总结)
转:http://www.cnblogs.com/Dzhouqi/p/3204481.html本文会利用到上篇,博客的分解定理,需要的可以查找上篇博客 D-separation对任何用有向图表示的概率 ...
- React Native调试技巧与心得
转自:http://blog.csdn.net/quanqinyang/article/details/52215652 在做React Native开发时,少不了的需要对React Native程序 ...
- 为什么S/4HANA的生产订单创建后会自动release
在S/4HANA系统里我们观察到通过函数CO_61_ORDER_EDIT创建的生产订单会自动释放Release: 通过第86行的IF语句的条件检测不难找到原因. 变量PROFILE_TMP的类型为TC ...
- 一段markdown编辑器代码研究
一段markdown编辑器代码研究 说明 代码在 https://github.com/dukeofharen/markdown-editor 之所以选择这个来分析是一方面是因为它的代码结构比较简单, ...
- Dropbox的CEO在MIT的毕业演讲
这是我今天看到的一个演讲,个人觉得和乔老大在斯坦佛的毕业演讲有异曲同工之妙,我也觉得对工科的我们很有启发意义,就此转载,希望与君共勉. 编者注:本篇文章基于Drew Houston 在 MIT 毕业典 ...
- idea debug操作
3. 条件断点 说明: 调试的时候,在循环里增加条件判断,可以极大的提高效率,心情也能愉悦.具体操作: 在断点处右击调出条件断点.可以在满足某个条件下,实施断点. 查看表达式的值(Ctrl + u): ...
- PAT——年会抽奖(错位 排序)
题目描述 今年公司年会的奖品特别给力,但获奖的规矩却很奇葩: 1. 首先,所有人员都将一张写有自己名字的字条放入抽奖箱中:2. 待所有字条加入完毕,每人从箱中取一个字条:3. 如果抽到的字条上写的就是 ...
- 教你使用 Reflexil 反编译.NET 转
转自:http://www.wxzzz.com/711.html http://sebastien.lebreton.free.fr/reflexil/ http://www.aneasystone. ...