堆与堆排序、Top k 问题
二叉堆的定义
二叉堆是完全二叉树或者是近似完全二叉树。
二叉堆满足二个特性:
1.父结点的键值总是大于或等于(小于或等于)任何一个子节点的键值。
2.每个结点的左子树和右子树都是一个二叉堆(都是最大堆或最小堆)。
当父结点的键值总是大于或等于任何一个子节点的键值时为最大堆。当父结点的键值总是小于或等于任何一个子节点的键值时为最小堆。下图展示一个最小堆:
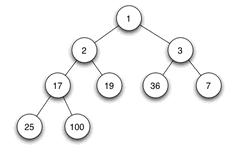
由于其它几种堆(二项式堆,斐波纳契堆等)用的较少,一般将二叉堆就简称为堆。
堆的存储
一般都用数组来表示堆,i结点的父结点下标就为(i – 1) / 2。它的左右子结点下标分别为2 * i + 1和2 * i + 2。如第0个结点左右子结点下标分别为1和2。

堆的操作——插入删除
下面先给出《数据结构C++语言描述》中最小堆的建立插入删除的图解,再给出本人的实现代码,最好是先看明白图后再去看代码。
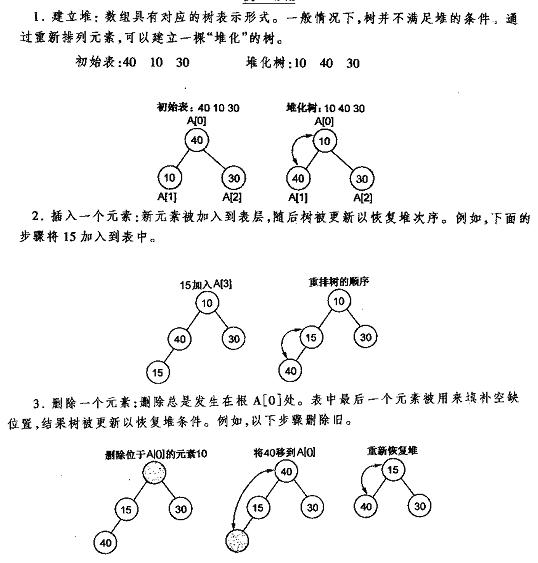
堆的插入
每次插入都是将新数据放在数组最后。可以发现从这个新数据的父结点到根结点必然为一个有序的数列,现在的任务是将这个新数据插入到这个有序数据中——这就类似于直接插入排序中将一个数据并入到有序区间中,对照《白话经典算法系列之二 直接插入排序的三种实现》不难写出插入一个新数据时堆的调整代码:
- // 新加入i结点 其父结点为(i - 1) / 2
- void MinHeapFixup(int a[], int i)
- {
- int j, temp;
- temp = a[i];
- j = (i - 1) / 2; //父结点
- while (j >= 0 && i != 0)
- {
- if (a[j] <= temp)
- break;
- a[i] = a[j]; //把较大的子结点往下移动,替换它的子结点
- i = j;
- j = (i - 1) / 2;
- }
- a[i] = temp;
- }

// 新加入i结点 其父结点为(i - 1) / 2
void MinHeapFixup(int a[], int i)
{
int j, temp;temp = a[i];
j = (i - 1) / 2; //父结点
while (j >= 0 && i != 0)
{
if (a[j] <= temp)
break; a[i] = a[j]; //把较大的子结点往下移动,替换它的子结点
i = j;
j = (i - 1) / 2;
}
a[i] = temp;
}
更简短的表达为:
- void MinHeapFixup(int a[], int i)
- {
- for (int j = (i - 1) / 2; (j >= 0 && i != 0)&& a[i] > a[j]; i = j, j = (i - 1) / 2)
- Swap(a[i], a[j]);
- }
void MinHeapFixup(int a[], int i)
{
for (int j = (i - 1) / 2; (j >= 0 && i != 0)&& a[i] > a[j]; i = j, j = (i - 1) / 2)
Swap(a[i], a[j]);
}
插入时:
- //在最小堆中加入新的数据nNum
- void MinHeapAddNumber(int a[], int n, int nNum)
- {
- a[n] = nNum;
- MinHeapFixup(a, n);
- }
//在最小堆中加入新的数据nNum
void MinHeapAddNumber(int a[], int n, int nNum)
{
a[n] = nNum;
MinHeapFixup(a, n);
}
堆的删除
按定义,堆中每次都只能删除第0个数据。为了便于重建堆,实际的操作是将最后一个数据的值赋给根结点,然后再从根结点开始进行一次从上向下的调整。调整时先在左右儿子结点中找最小的,如果父结点比这个最小的子结点还小说明不需要调整了,反之将父结点和它交换后再考虑后面的结点。相当于从根结点将一个数据的“下沉”过程。下面给出代码:
- // 从i节点开始调整,n为节点总数 从0开始计算 i节点的子节点为 2i+1, 2i+2
- void MinHeapFixdown(int a[], int i, int n)
- {
- int j, temp;
- temp = a[i];
- j = 2 i + 1;
- while (j < n)
- {
- if (j + 1 < n && a[j + 1] < a[j]) //在左右孩子中找最小的
- j++;
- if (a[j] >= temp)
- break;
- a[i] = a[j]; //把较小的子结点往上移动,替换它的父结点
- i = j;
- j = 2 i + 1;
- }
- a[i] = temp;
- }
- //在最小堆中删除数
- void MinHeapDeleteNumber(int a[], int n)
- {
- Swap(a[0], a[n - 1]);
- MinHeapFixdown(a, 0, n - 1);
- }
// 从i节点开始调整,n为节点总数 从0开始计算 i节点的子节点为 2i+1, 2i+2
void MinHeapFixdown(int a[], int i, int n)
{
int j, temp;temp = a[i];
j = 2 * i + 1;
while (j < n)
{
if (j + 1 < n && a[j + 1] < a[j]) //在左右孩子中找最小的
j++; if (a[j] >= temp)
break; a[i] = a[j]; //把较小的子结点往上移动,替换它的父结点
i = j;
j = 2 * i + 1;
}
a[i] = temp;
}
//在最小堆中删除数
void MinHeapDeleteNumber(int a[], int n)
{
Swap(a[0], a[n - 1]);
MinHeapFixdown(a, 0, n - 1);
}
堆化数组
有了堆的插入和删除后,再考虑下如何对一个数据进行堆化操作。要一个一个的从数组中取出数据来建立堆吧,不用!先看一个数组,如下图:
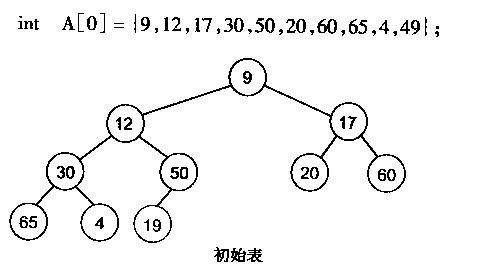
很明显,对叶子结点来说,可以认为它已经是一个合法的堆了即20,60, 65, 4, 49都分别是一个合法的堆。只要从A[4]=50开始向下调整就可以了。然后再取A[3]=30,A[2] = 17,A[1] = 12,A[0] = 9分别作一次向下调整操作就可以了。下图展示了这些步骤:
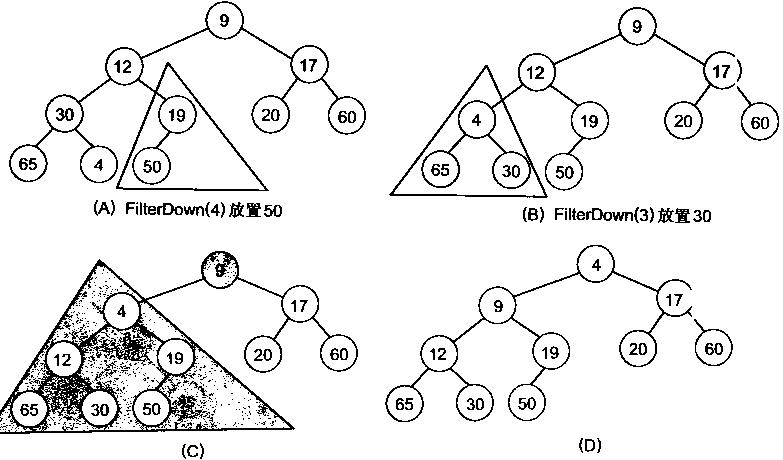
写出堆化数组的代码:
- //建立最小堆
- void MakeMinHeap(int a[], int n)
- {
- for (int i = n / 2 - 1; i >= 0; i--)
- MinHeapFixdown(a, i, n);
- }
//建立最小堆
void MakeMinHeap(int a[], int n)
{
for (int i = n / 2 - 1; i >= 0; i--)
MinHeapFixup(a, i, n);
}
至此,堆的操作就全部完成了(注1),再来看下如何用堆这种数据结构来进行排序。
堆排序
首先可以看到堆建好之后堆中第0个数据是堆中最小的数据。取出这个数据再执行下堆的删除操作。这样堆中第0个数据又是堆中最小的数据,重复上述步骤直至堆中只有一个数据时就直接取出这个数据。
由于堆也是用数组模拟的,故堆化数组后,第一次将A[0]与A[n - 1]交换,再对A[0…n-2]重新恢复堆。第二次将A[0]与A[n – 2]交换,再对A[0…n - 3]重新恢复堆,重复这样的操作直到A[0]与A[1]交换。由于每次都是将最小的数据并入到后面的有序区间,故操作完成后整个数组就有序了。有点类似于直接选择排序。
- void MinheapsortTodescendarray(int a[], int n)
- {
- for (int i = n - 1; i >= 1; i--)
- {
- Swap(a[i], a[0]);
- MinHeapFixdown(a, 0, i);
- }
- }
void MinheapsortTodescendarray(int a[], int n)
{
for (int i = n - 1; i >= 1; i--)
{
Swap(a[i], a[0]);
MinHeapFixdown(a, 0, i);
}
}
注意使用最小堆排序后是递减数组,要得到递增数组,可以使用最大堆。
由于每次重新恢复堆的时间复杂度为O(logN),共N - 1次重新恢复堆操作,再加上前面建立堆时N / 2次向下调整,每次调整时间复杂度也为O(logN)。二次操作时间相加还是O(N * logN)。故堆排序的时间复杂度为O(N * logN)。STL也实现了堆的相关函数,可以参阅《STL系列之四 heap 堆》。
注1 作为一个数据结构,最好用类将其数据和方法封装起来,这样即便于操作,也便于理解。此外,除了堆排序要使用堆,另外还有很多场合可以使用堆来方便和高效的处理数据,以后会一一介绍。
-------------------------------------------自己的东西-------------------------------------------
Question ——Kth Largest Element in an Array
Find the kth largest element in an unsorted array. Note that it is the kth largest element in the sorted order, not the kth distinct element.
For example,
Given [3,2,1,5,6,4] and k = 2, return 5.
Note:
You may assume k is always valid, 1 ≤ k ≤ array's length.
解题思路
这道题就是让我们在数组中找第k大的数,直接来个排序,从大到小,然后输出第k个,就结束了? 用快排时间复杂度为O(nlgn)。 题目有这么简单?
显然不是这样的,说明要找一个比这个更快的算法。这其实是一个比较经典的top k的问题。 时间复杂度为O(nlgk)。
具体实现
#include <iostream>
#include <vector>
using namespace std;
class Solution {
public:
int findKthLargest(vector<int>& nums, int k) {
// 建立节点个数为k的堆,直接用前k个节点
// 然后遍历剩下的节点,如果比堆的顶点都小的直接舍弃,大的则将堆的顶点用新的节点替换,然后再进行堆的调整
// 所以时间复杂度为 O(nlgk)
// 建立大小为k的堆
for (int i = 0; i < k; i++) {
MinHeapFixup(nums, i);
}
for (int i = k; i < nums.size(); i++) {
if (nums[i] > nums[0]) {
nums[0] = nums[i];
MinHeapFixdown(nums, 0, k);
}
}
return nums[0];
}
// 堆的插入
void MinHeapFixup(vector<int>& nums, int i) {
int j, tmp;
tmp = nums[i];
j = (i - 1) / 2; //父节点
while(j >= 0 && i != 0) {
if (nums[j] < tmp)
break;
nums[i] = nums[j];
i = j;
j = (i - 1) / 2;
}
nums[i] = tmp;
}
// 堆的删除(堆的调整,从根部开始)
// 堆删除的实际做法,就是将数组中的最后一个节点和根节点对换,删除最后一个元素,然后再把堆进行调整。
void MinHeapFixdown(vector<int>&nums, int i, int k) {
int j, tmp;
tmp = nums[i];
j = 2 * i + 1; // 孩子节点
while (j < k) {
if (j + 1 < k && nums[j + 1] < nums[j]) //在左右孩子中找最小的孩子
j++;
if (nums[j] > tmp)
break;
nums[i] = nums[j];
i = j;
j = 2 * i + 1;
}
nums[i] = tmp;
}
};
前面的内容转载至:http://blog.csdn.net/morewindows/article/details/6709644/
堆与堆排序、Top k 问题的更多相关文章
- 利用堆来处理Top K问题
目录 一.什么是Top K问题 二.Top K的实际应用场景 三.Top K问题的代码实现及其效率对比 1.用堆来实现Top K 2.用快排来实现Top K 3.用堆或用快排来实现 TopK 的效率对 ...
- 优先队列PriorityQueue实现 大小根堆 解决top k 问题
转载:https://www.cnblogs.com/lifegoesonitself/p/3391741.html PriorityQueue是从JDK1.5开始提供的新的数据结构接口,它是一种基于 ...
- Top K问题的两种解决思路
Top K问题在数据分析中非常普遍的一个问题(在面试中也经常被问到),比如: 从20亿个数字的文本中,找出最大的前100个. 解决Top K问题有两种思路, 最直观:小顶堆(大顶堆 -> 最小1 ...
- 排序算法Java版,以及各自的复杂度,以及由堆排序产生的top K问题
常用的排序算法包括: 冒泡排序:每次在无序队列里将相邻两个数依次进行比较,将小数调换到前面, 逐次比较,直至将最大的数移到最后.最将剩下的N-1个数继续比较,将次大数移至倒数第二.依此规律,直至比较结 ...
- 优先队列实现 大小根堆 解决top k 问题
摘于:http://my.oschina.net/leejun2005/blog/135085 目录:[ - ] 1.认识 PriorityQueue 2.应用:求 Top K 大/小 的元素 3 ...
- 堆实战(动态数据流求top k大元素,动态数据流求中位数)
动态数据集合中求top k大元素 第1大,第2大 ...第k大 k是这群体里最小的 所以要建立个小顶堆 只需要维护一个大小为k的小顶堆 即可 当来的元素(newCome)> 堆顶元素(small ...
- [LeetCode] Top K Frequent Words 前K个高频词
Given a non-empty list of words, return the k most frequent elements. Your answer should be sorted b ...
- 利用堆实现堆排序&优先队列
数据结构之(二叉)堆一文在末尾提到"利用堆能够实现:堆排序.优先队列.".本文代码实现之. 1.堆排序 如果要实现非递减排序.则须要用要大顶堆. 此处设计到三个大顶堆的操作:(1) ...
- 海量数据中找top K专题
1. 10亿个数中找出最大的1000个数 这种题目就是分治+堆排序. 为啥分治?因为数太多了,全部加载进内存不够用,所以分配到多台机器中,或者多个文件中,但具体分成多少份,视情况而定,只要保证满足内存 ...
随机推荐
- AndroidManifest.xml文件详解(activity)(四)
android:multiprocess 这个属性用于设置Activity的实例能否被加载到与启动它的那个组件所在的进程中,如果设置为true,则可以,否则不可以.默认值是false. 通常,一个新的 ...
- jpa双向一对一关联外键映射
项目结构: Wife package auth.model; import javax.persistence.CascadeType; import javax.persistence.Column ...
- vertical-align 使用参考
在实现文字与图片垂直对齐的时候,发现了vertical-align的值也是很纷繁复杂,博客讲解各种不懂,最终还是找了CSS权威指南-中文第三版,看了前6章,终于弄明白了,如果你也有不懂的地方,请去看书 ...
- cdr X6 64位32位缩略图补丁包
cdr X6 64位32位缩略图补丁包下载 安装了X6没有缩略图的话,点击下面链接下载安装插件即可 点击下载
- etcd集群安装部署
1. 集群架构 由于我们只有两个机房,所以选择的是以上图中所示的数据同步方案, 通过做镜像的方式保证两个集群的数据实时同步. 整体架构如上图所示, 整个全局元数据中心包括两套集群,廊坊集群和马驹桥集群 ...
- socketserver模块、MySQL(数据库、数据表的操作)
一.socketserver实现并发 基于tcp的套接字,关键就是两个循环,一个链接循环,一个通信循环. socketserver模块中分两大类:server类(解决链接问题)和request类(解决 ...
- 目标检测之R-FCN
R-FCN:Object Detection via Region-based Fully Convolutional Networks R-FCN的网络结构 一个Base的convolutional ...
- 系列文章(二):从WLAN的安全威胁,解析电信诈骗的技术症结——By Me
导读:互联网的无线接入已经成为大趋势,其中无线局域网(又称为WLAN,Wireless Local AreaNetwork)以其使用方便.组网灵活.可扩展性好.成本低等优点,成为互联网特别是移动互联网 ...
- unity3d相关资源
http://pan.baidu.com/s/1kTG9DVD GUI源码
- (转)RTP-H264封包分析
rtp(H264)第一个包(单一NAL单元模式)————-sps 80 {V=10,p=0,x=0,cc=0000} 60 {m=0,pt=110 0000} 53 70{sequence numbe ...