【RL系列】Multi-Armed Bandit笔记补充(一)
在此之前,请先阅读上一篇文章:【RL系列】Multi-Armed Bandit笔记
本篇的主题就如标题所示,只是上一篇文章的补充,主要关注两道来自于Reinforcement Learning: An Introduction 的课后习题。
第一题为Exercise 2.5 (programming),主要讨论了Recency-Weighted Average算法相较于Sample Average算法的优点所在。练习内容大致为比较这两种算法在收益分布为非平稳分布的情况下的表现情况,主要的评价指标依照Figure 2.2,也就是Average Reward和Optimal Action Rate两个。
先前我们在上一篇文章中讨论的所有情况都是假设收益分布为一个固定的不变的正态分布,比如N(1, 1),这里可以称其为平稳分布(Stationary Distribution)。那么如何制造一个非平稳分布呢?在练习中,已经给出了提示:在每一步的实验中,在实际收益均值上加一个服从标准差差为0.01,均值为0的正态分布的随机数即可,举个例子,N(1 + N(0, 0.01), 1)。那么在原先的Matlab程序中需要做出如下的修改:
% 10-Armed Bandit
K = 10;
AverReward = randn([1 K]);
% Reward for each Action per experiment
% Reward(Action) = normrnd(AverReward(Action) + normrnd(0, 0.01), 1);
学习过程的参数设定为epsilon = 0.1,最终step数设为10000:
第二题为Exercise 2.6,这个问题是关于初值优化的,主要讨论了初值优化后的OAR图像为何会在实验次数较少时出现突然的尖峰,这个问题也被称作Mysterious Spike:
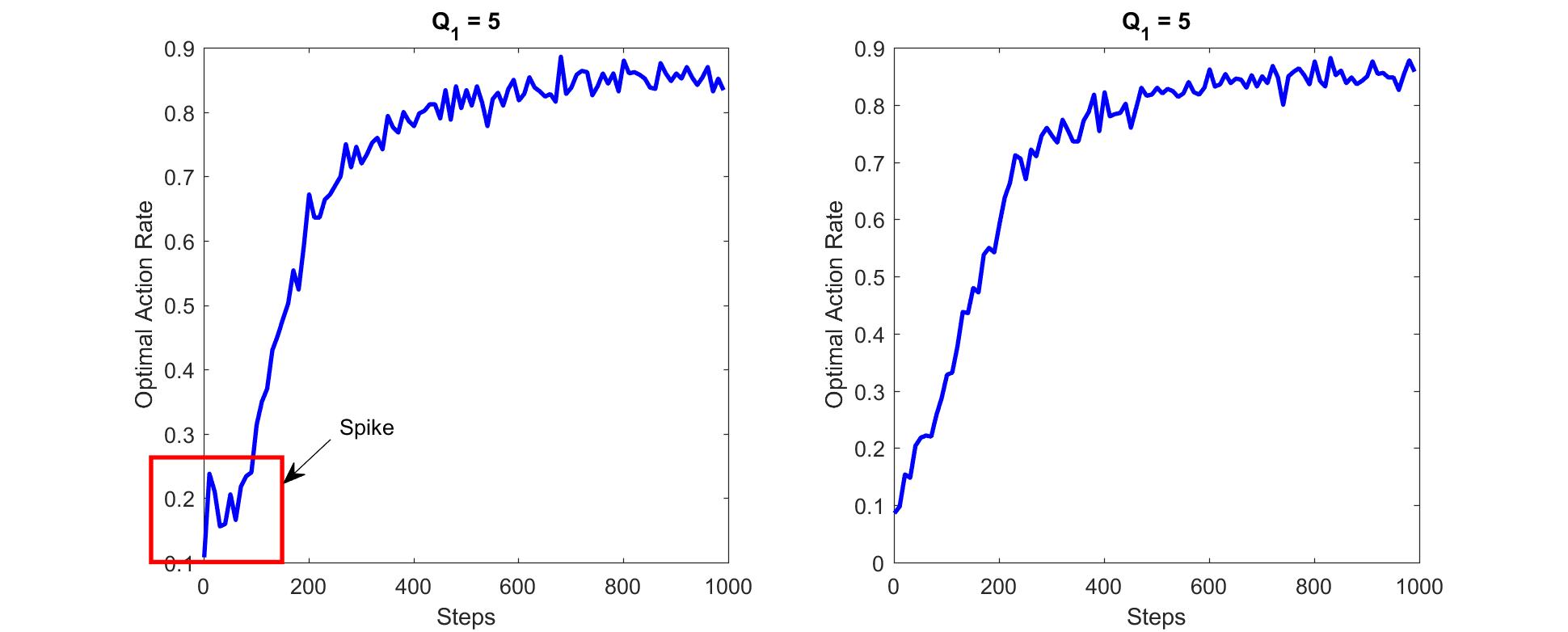
假设我们将初值Q1设为5,最终step数设为1000,epsilon = 0。可以发现左图的greedy策略是直接求解Q值中的最大值所对应的动作,如下将其转化为Matlab
[MAX i] = max(Q);
if(rand(1) < 1 - epsilon)
CurrentA = i;
else
CurrentA = unidrnd(RandK);
end
而右图也同样是将初值设为5,但并未出现Spike现象,给出右图的greedy选择策略:
[MAX i] = max(Q);
if(MAX ~= 5 & rand(1) < 1 - epsilon)
CurrentA = i;
else
CurrentA = unidrnd(RandK);
end
出现Spike现象的原因其实很简单,如果一向量或序列存在两个或两个以上相同的最大值时,计算机在计算最值所在位置的返回值一定是第一个最大值的位置。举个例子(Matlab)
x = [1 2 5 5 5 1]
[MAX n] = max(x); >> MAX = 5
>> n = 3
这个例子中一定不会出现n = 4或n= 5,这就造成了一个问题,我们总是会在有限的步数内不断的去逼近那个真实的收益均值最大值所在的位置。那么在计算Optimal Action Rate时,我们可以举个例子,假设现在是10-Armed Bandit问题,而step数只有不到十次,我们就只看5次的情况吧,假设我们的真实收益最大均值就在向量的第五个位置。
N = 7
K = 10
Reward = [1 2 3 4 5 4.5 3.5 2.5 1.5 0.5];
[MAX i] = max(Reward);
>> MAX = 5
>> i = 5 Q = zeros(1, K) + 5; % First step
[MAXQ i] = max(Q);
>> i = 1
>> Q = [4.6 5 5 5 5 5 5 5 5 5]
>> OAR = 0 % Second step
[MAXQ i] = max(Q);
>> i = 2
>> Q = [4.6 4.7 5 5 5 5 5 5 5 5]
>> OAR = 0 ..... % 5th step
[MAX i] = max(Q);
>> i = 5
>> Q = [4.6 4.7 4.8 4.9 5 5 5 5 5 5]
>> OAR = 0.2
%Notice that here's a Spike!
所以依据上面的推断,我们可以推测出,Spike的发生大概率出现在K次实验内(K为K-Armed中的K),而且Spike的最高值取决于真实的收益均值所在的位置与K值之比,假设其所在位置为第M位,则Spike的值可以估计为M/K。当实验次数大于K时,OAR则会从1/K开始逐步增加。
【RL系列】Multi-Armed Bandit笔记补充(一)的更多相关文章
- 【RL系列】Multi-Armed Bandit笔记补充(二)
本篇的主题是对Upper Conference Bound(UCB)策略进行一个理论上的解释补充,主要探讨UCB方法的由来与相关公式的推导. UCB是一种动作选择策略,主要用来解决epsilon-gr ...
- 【RL系列】Multi-Armed Bandit笔记——UCB策略与Gradient策略
本篇主要是为了记录UCB策略与Gradient策略在解决Multi-Armed Bandit问题时的实现方法,涉及理论部分较少,所以请先阅读Reinforcement Learning: An Int ...
- 【RL系列】Multi-Armed Bandit问题笔记
这是我学习Reinforcement Learning的一篇记录总结,参考了这本介绍RL比较经典的Reinforcement Learning: An Introduction (Drfit) .这本 ...
- 【RL系列】马尔可夫决策过程——状态价值评价与动作价值评价
请先阅读上两篇文章: [RL系列]马尔可夫决策过程中状态价值函数的一般形式 [RL系列]马尔可夫决策过程与动态编程 状态价值函数,顾名思义,就是用于状态价值评价(SVE)的.典型的问题有“格子世界(G ...
- 【RL系列】从蒙特卡罗方法步入真正的强化学习
蒙特卡罗方法给我的感觉是和Reinforcement Learning: An Introduction的第二章中Bandit问题的解法比较相似,两者皆是通过大量的实验然后估计每个状态动作的平均收益. ...
- (zhuan) 一些RL的文献(及笔记)
一些RL的文献(及笔记) copy from: https://zhuanlan.zhihu.com/p/25770890 Introductions Introduction to reinfor ...
- 【RL系列】马尔可夫决策过程中状态价值函数的一般形式
请先阅读上一篇文章:[RL系列]马尔可夫决策过程与动态编程 在上一篇文章里,主要讨论了马尔可夫决策过程模型的来源和基本思想,并以MAB问题为例简单的介绍了动态编程的基本方法.虽然上一篇文章中的马尔可夫 ...
- STM32 FSMC学习笔记+补充(LCD的FSMC配置)
STM32 FSMC学习笔记+补充(LCD的FSMC配置) STM32 FSMC学习笔记 STM32 FSMC的用法--LCD
- Vue双向绑定的实现原理系列(四):补充指令解析器compile
补充指令解析器compile github源码 补充下HTML节点类型的知识: 元素节点 Node.ELEMENT_NODE(1) 属性节点 Node.ATTRIBUTE_NODE(2) 文本节点 N ...
随机推荐
- IOS 文件名获取简洁方式
//这里有一个模拟器沙盒路径(完整路径) NSString* index=@"/Users/junzoo/Library/Application Support/iPhone Simulat ...
- SQLMAP注入常见用法
1.检查注入点 sqlmap -u http://www.com.tw/star_photo.php?artist_id=11 2.列数据库信息当前用户和数据库 sqlmap -u http://ww ...
- Springmvc+Spring+Mybatis整合开发(架构搭建)
Springmvc+Spring+Mybatis整合开发(架构搭建) 0.项目结构 Springmvc:web层 Spring:对象的容器 Mybatis:数据库持久化操作 1.导入所有需要的jar包 ...
- json提取嵌套数据
//数据 string html = "{\"code\":\"0000\",\"desc\":\"\",\& ...
- NOI2002银河英雄传说-带权并查集
[NOI2002]银河英雄传说-带权并查集 luogu P1196 题目描述 Description: 公元五八○一年,地球居民迁至金牛座α第二行星,在那里发表银河联邦创立宣言,同年改元为宇宙历元年, ...
- Nginx初体验(一):nginx介绍
今天我们来介绍一下Nginx. Nginx是一款轻量级的Web服务器/反向代理服务器以及电子邮件(IMAP/POP3)代理服务器 特点: 反向代理,负载均衡,动静分离 首先我们来介绍一下正向代理服务器 ...
- tcp滑动窗口与拥塞控制
TCP协议作为一个可靠的面向流的传输协议,其可靠性和流量控制由滑动窗口协议保证,而拥塞控制则由控制窗口结合一系列的控制算法实现.一.滑动窗口协议 所谓滑动窗口协议,自己理解有两点:1. “窗口 ...
- HDU 2242 考研路茫茫——空调教室
考研路茫茫——空调教室 http://acm.hdu.edu.cn/showproblem.php?pid=2242 分析: 树形dp,删边. 代码: #include<cstdio> # ...
- Spark性能优化--开发调优与资源调优
参考: https://tech.meituan.com/spark-tuning-basic.html https://zhuanlan.zhihu.com/p/22024169 一.开发调优 1. ...
- 2019年猪年海报PSD模板-第七部分
14套精美猪年海报,免费猪年海报,下载地址:百度网盘,https://pan.baidu.com/s/1pE3X9AYirog1W8FSxbMiAQ