Leveldb源码解析之Bloom Filter
Bloom Filter,即布隆过滤器,是一种空间效率很高的随机数据结构。
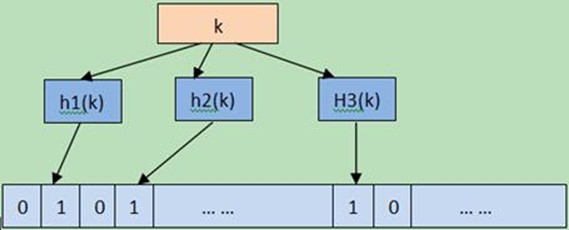
原理:开辟m个bit位数组的空间,并全部置零,使用k个哈希函数将元素映射到数组中,相应位置1.如下图,元素K通过哈希函数h1,h2,h3在数组上置1。
LevelDB中加入bloom filter的支持。目前针对一次查询,LevelDB可能需要在每个level上进行一次磁盘随机访问。通过使用bloom filter可以大大减少所需要的磁盘I/O操作。比如,假设调用者正在查找一个值为"Foo"的key,LevelDB会从每个level下选择相应的SSTable文件(那些range包含了该key的文件),之后会在这些SSTable文件上进行随机读。如果每个SSTable都有一个对应的bloom filter,那么查找时就可以很容易地通过检查bloom filter跳过那些不包含该key的SSTable文件。
在leveldb的实现中,Name()返回"leveldb.BuiltinBloomFilter",因此metaindex block 中的key就是"filter.leveldb.BuiltinBloomFilter"。Leveldb使用了double hashing来模拟多个hash函数,当然这里不是用来解决冲突的。
和线性再探测(linearprobing)一样,Double hashing从一个hash值开始,重复向前迭代,直到解决冲突或者搜索完hash表。不同的是,double hashing使用的是另外一个hash函数,而不是固定的步长。
给定两个独立的hash函数h1和h2,对于hash表T和值k,第i次迭代计算出的位置就是:h(i, k) = (h1(k) + i*h2(k)) mod |T|。
对此,Leveldb选择的hash函数是:
Gi(x)=H1(x)+iH2(x)
H2(x)=(H1(x)>>17) | (H1(x)<<15)
H1是一个基本的hash函数,H2是由H1循环右移得到的,Gi(x)就是第i次循环得到的hash值。【理论分析可参考论文Kirsch,Mitzenmacher2006】
说明bloomfliter 的原理之后来看下Leveldb是怎么来实现它的, 使用CreateFilter创建一个bloomfliter
virtual void CreateFilter(const Slice* keys, int n, std::string* dst) const {
// Compute bloom filter size (in both bits and bytes)
size_t bits = n * bits_per_key_;
// For small n, we can see a very high false positive rate. Fix it
// by enforcing a minimum bloom filter length.
if (bits < ) bits = ;
size_t bytes = (bits + ) / ;
bits = bytes * ;
const size_t init_size = dst->size();
dst->resize(init_size + bytes, );
dst->push_back(static_cast<char>(k_)); // Remember # of probes in filter
char* array = &(*dst)[init_size];
for (size_t i = ; i < n; i++) {
// Use double-hashing to generate a sequence of hash values.
// See analysis in [Kirsch,Mitzenmacher 2006].
uint32_t h = BloomHash(keys[i]);
const uint32_t delta = (h >> ) | (h << ); // Rotate right 17 bits
for (size_t j = ; j < k_; j++) {
const uint32_t bitpos = h % bits;
array[bitpos/] |= ( << (bitpos % ));
h += delta;
}
}
}
函数KeyMayMatch ()在读取数据的时候调用
virtual bool KeyMayMatch(const Slice& key, const Slice& bloom_filter) const {
const size_t len = bloom_filter.size();
if (len < ) return false;
const char* array = bloom_filter.data();
const size_t bits = (len - ) * ;
// Use the encoded k so that we can read filters generated by
// bloom filters created using different parameters.
const size_t k = array[len-];
if (k > ) {
// Reserved for potentially new encodings for short bloom filters.
// Consider it a match.
return true;
}
uint32_t h = BloomHash(key);
const uint32_t delta = (h >> ) | (h << ); // Rotate right 17 bits
for (size_t j = ; j < k; j++) {
const uint32_t bitpos = h % bits;
if ((array[bitpos/] & ( << (bitpos % ))) == ) return false;
h += delta;
}
return true;
}
计算key的hash值,重复计算阶段的步骤,循环计算k个hash值,只要有一个结果对应的bit位为0,就认为不匹配,否则认为匹配。
错误率估计
但Bloom Filter的这种高效是有一定代价的:在判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误认为属于这个集合(false positive)。因此,Bloom Filter不适合那些"零错误"的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter通过极少的错误换取了存储空间的极大节省。
吴军的数学之美中对Bloom Filter的错误率有详细解释。
假设 Hash 函数以等概率条件选择并设置 Bit Array 中的某一位,m 是该位数组的大小,k 是 Hash 函数的个数,那么位数组中某一特定的位在进行元素插入时的 Hash 操作中没有被置位的概率是:
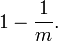
那么在所有 k 次 Hash 操作后该位都没有被置 "1" 的概率是:
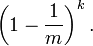
如果我们插入了 n 个元素,那么某一位仍然为 "0" 的概率是:
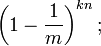
因而该位为 "1"的概率是:
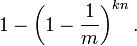
现在检测某一元素是否在该集合中。标明某个元素是否在集合中所需的 k 个位置都按照如上的方法设置为 "1",但是该方法可能会使算法错误的认为某一原本不在集合中的元素却被检测为在该集合中(False Positives),该概率由以下公式确定:
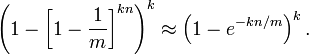
Leveldb源码解析之Bloom Filter的更多相关文章
- LevelDB 源码解析之 Random 随机数
GitHub: https://github.com/storagezhang Emai: debugzhang@163.com 华为云社区: https://bbs.huaweicloud.com/ ...
- LevelDB 源码解析之 Arena
GitHub: https://github.com/storagezhang Emai: debugzhang@163.com 华为云社区: https://bbs.huaweicloud.com/ ...
- LevelDB 源码解析之 Varint 编码
GitHub: https://github.com/storagezhang Emai: debugzhang@163.com 华为云社区: https://bbs.huaweicloud.com/ ...
- ReactiveCocoa源码解析(五) SignalProtocol的observe()、Map、Filter延展实现
上篇博客我们对Signal的基本实现以及Signal的面向协议扩展进行了介绍, 详细内容请移步于<Signal中的静态属性静态方法以及面向协议扩展>.并且聊了Signal的所有的g功能扩展 ...
- ReactiveSwift源码解析(五) SignalProtocol的observe()、Map、Filter延展实现
上篇博客我们对Signal的基本实现以及Signal的面向协议扩展进行了介绍, 详细内容请移步于<Signal中的静态属性静态方法以及面向协议扩展>.并且聊了Signal的所有的g功能扩展 ...
- leveldb源码分析--SSTable之TableBuilder
上一篇文章讲述了SSTable的格式以后,本文结合源码解析SSTable是如何生成的. void TableBuilder::Add(const Slice& key, const Slice ...
- 时序数据库 Apache-IoTDB 源码解析之文件索引块(五)
上一章聊到 TsFile 的文件组成,以及数据块的详细介绍.详情请见: 时序数据库 Apache-IoTDB 源码解析之文件数据块(四) 打一波广告,欢迎大家访问IoTDB 仓库,求一波 Star. ...
- Parquet 源码解析
date: 2020-07-20 16:15:00 updated: 2020-07-27 13:40:00 Parquet 源码解析 Parquet文件是以二进制方式存储的,所以是不可以直接读取的, ...
- 时序数据库 Apache-IoTDB 源码解析之元数据索引块(六)
上一章聊到 TsFile 索引块的详细介绍,以及一个查询所经过的步骤.详情请见: 时序数据库 Apache-IoTDB 源码解析之文件索引块(五) 打一波广告,欢迎大家访问 IoTDB 仓库,求一波 ...
随机推荐
- setTimeOut、setInterval与clearInterval函数
1.setTimeOut 在指定毫秒数后调用函数或计算表达式,函数或计算表达式只执行一次 setTimeout("alert('5 seconds!')",5000) 2.setI ...
- python中requests库中文乱码问题
当使用这个库的时候经常会出现各种乱码的情况. 首先要知道: text返回的是处理过的unicode的数据. content返回的是bytes的原始数据 也就是说r.content比r.text更加节省 ...
- static class 和 non static class 的区别
static class non static class 1.用static修饰的是内部类,此时这个 内部类变为静态内部类:对测试有用: 2.内部静态类不需要有指向外部类的引用: 3.静态类只能访问 ...
- 【HDU3037】Saving Beans
Lucas的裸题,学习一个. #include<bits/stdc++.h> #define N 100010 using namespace std; typedef long long ...
- JAVA常见的集合类
关系的介绍: Set(集):集合中的元素不按特定方式排序,并且没有重复对象.他的有些实现类能对集合中的对象按特定方式排序. List(列表):集合中的元素按索引位置排序,可以有重复对象,允许按照对象在 ...
- ACdream 1157 Segments CDQ分治
题目链接:https://vjudge.net/problem/ACdream-1157 题意: Problem Description 由3钟类型操作: 1)D L R(1 <= L < ...
- C核心 那些个关键字
概述 - C语言老了 目前而言(2017年5月12日) C语言中有 32 + 5 + 7 = 44 个关键字. 具体如下 O(∩_∩)O哈哈~ -> C89关键字 char short int ...
- springboot在不同环境下进行不同的配置
原文链接:http://www.cnblogs.com/java-zhao/p/5469183.html 不同的环境设置一个配置文件,例如:dev(开发)环境下的配置设置在application-de ...
- Winform利用委托进行窗体间的传值
在form1.cs中 1.委托的定义 //定义一个委托 public delegate void AddUsrEventHandler(object sender, AddUsrEventHandle ...
- js刷新页面代码
第一种: location.reload() 第二种: location.replace(location.href) 第三种: history.go() 第四种: location=location ...