10-hdfs-hdfs搭建
hdfs的优缺点比较:


架构图解分析:
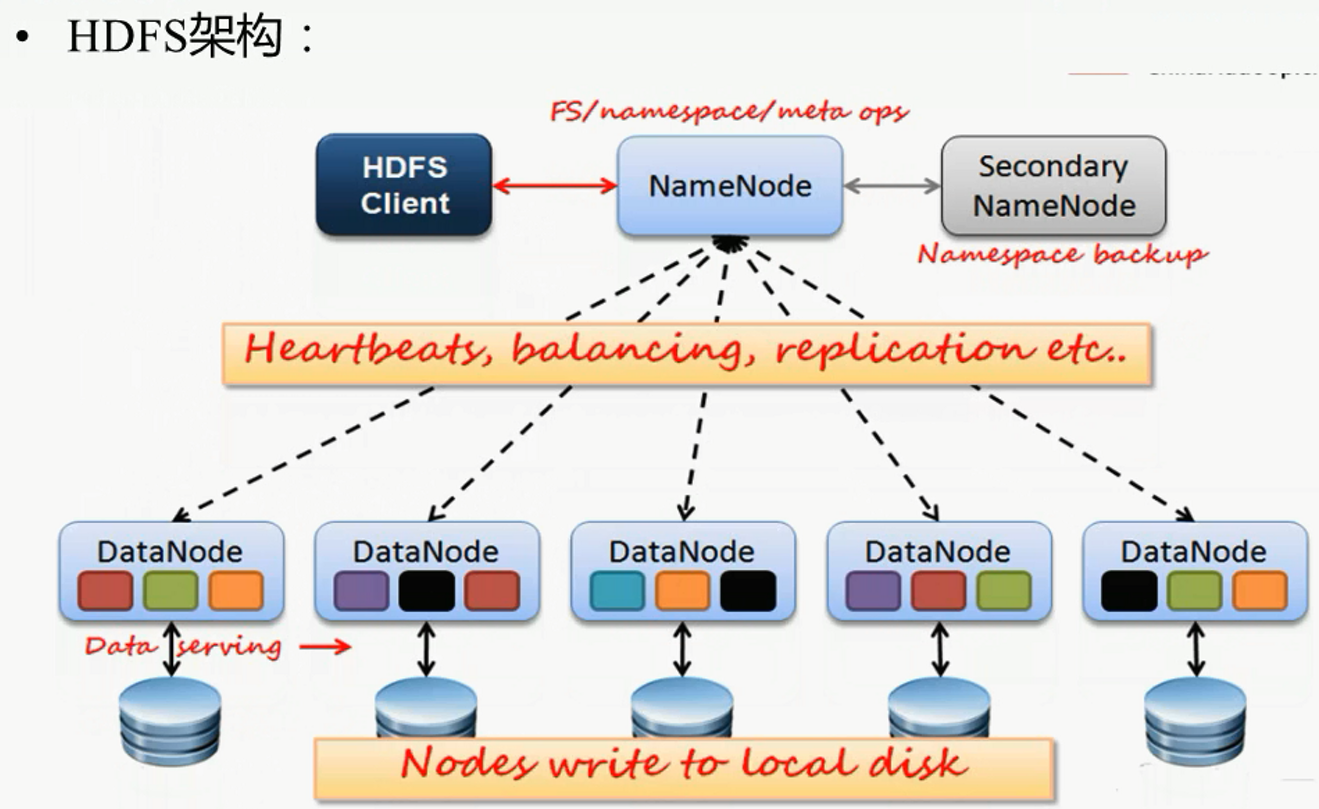
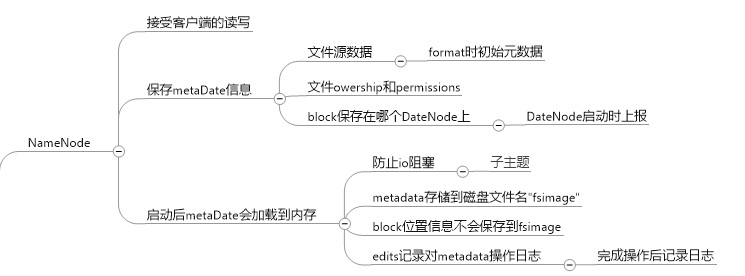
nameNode的主要任务:
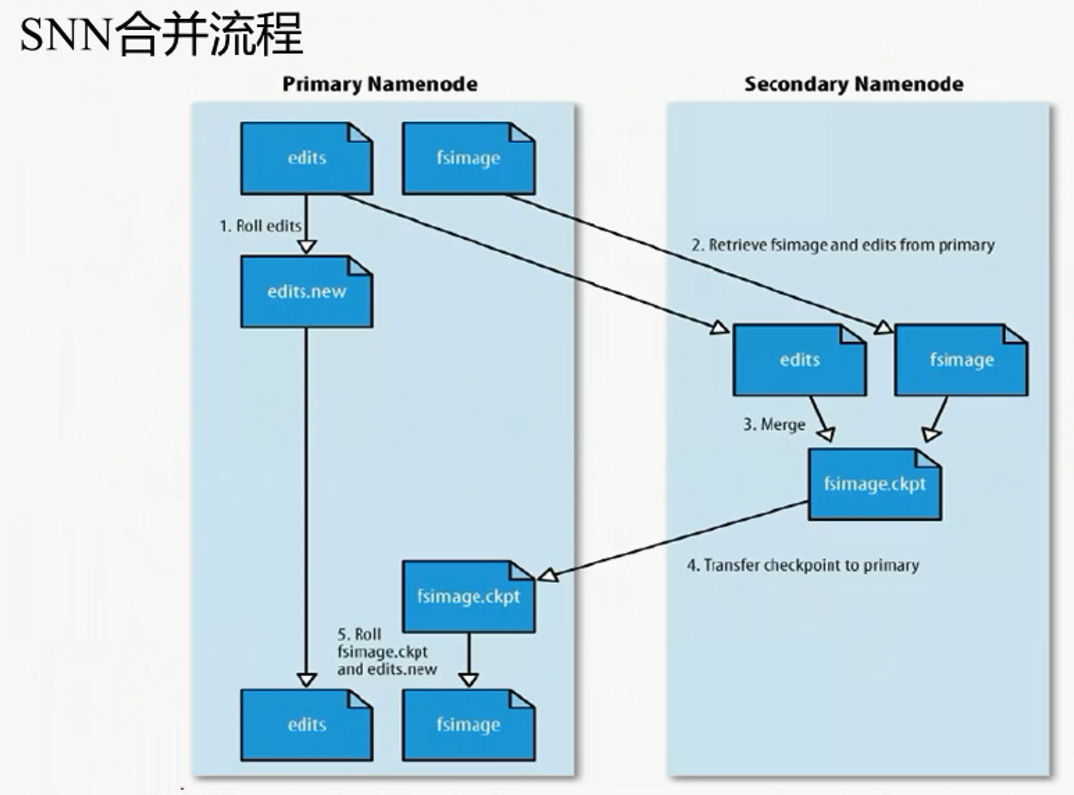
SNameNode的功能: (不是NN的备份, 主要用来合并fsimage)

合并流程:
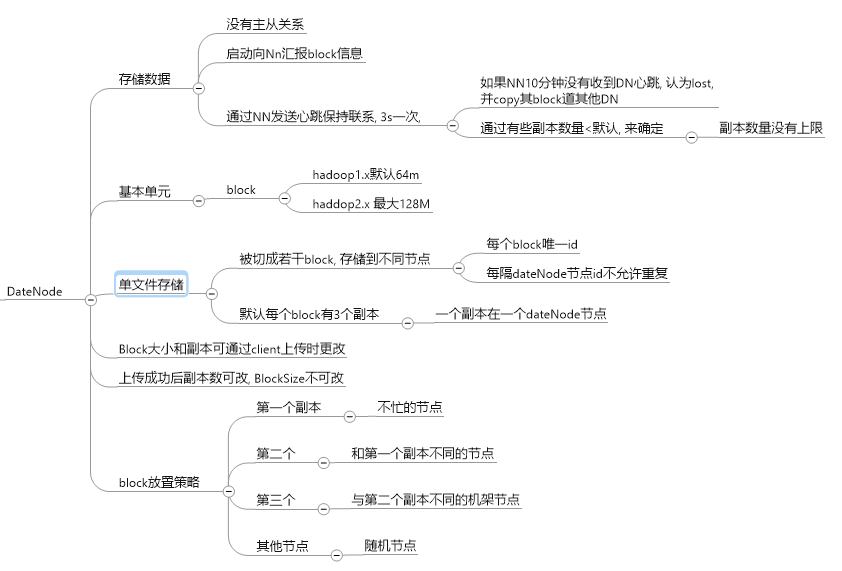
dataNode的主要功能:
HDFS上传文件思想:
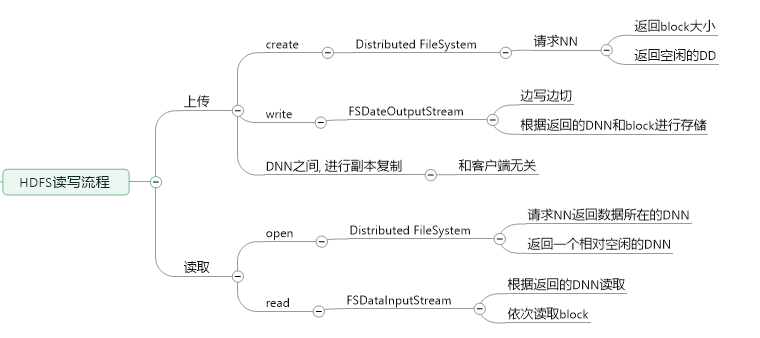
hdfs用于一般用于处理离线数据文件, 存储方式为block副本, 集群规划使用完全式分部安装
一台作为NameNode, 3台为DataNode, 其中hdfs-dnn1 为SecondNameNode:
NameNode: 192.168.208.106 wenbronk.hdfs.com
DataNode: 192.168.208.107 hdfs-dnn1
DataNode: 192.168.208.108 hdfs-dnn2
DataNode: 192.168.208.109 hdfs-dnn3
1, 为了方便NameNode直接启动DataNode, 不输入密码, 使用ssh的免密登录
注意: 1. .ssh目录权限必须是700
2 . .ssh/authorized_keys 文件权限必须是600
(nameNode需要远程登陆Dnn中进行开启DNN), 不设置的话每次输入密码
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
生成的公钥和私钥文件在 /root/.ssh 下
将 自己 设置为免密码登录, 将生成的pub文件追加到认证文件下
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys将 NN的公钥放置到DNN中去, (详细可见 ssh 免密码登录 原理)
scp ~/.ssh/id_rsa.pub root@hdfs-dnn1:/opt/ssh
cat /opt/ssh/id_rsa.pub >> ~/.ssh/authorized_keys
scp ~/.ssh/id_rsa.pub root@hdfs-dnn2:/opt/ssh
cat /opt/ssh/id_rsa.pub >> ~/.ssh/authorized_keys
scp ~/.ssh/id_dsa.pub root@hdfs-dnn3:/opt/ssh
cat /opt/ssh/id_dsa.pub >> ~/.ssh/authorized_keys
2, 配置4台机器的jdk为1.7版本的, (使用hadoop2.x)
配置好一台机器后, 使用scp拷贝
scp -r jdk1..0_79/ root@hdfs-dnn1:/usr/opt/
scp -r jdk1.7.0_79/ root@hdfs-dnn3:/usr/opt/
之后, source /etc/profile
3, 上传解压hadoop.2.5.1_x64.tar.gz
使用rz上传
使用tar -zxvf had.. 解压
4, 修改配置文件
cd hadoop.2.5./etc/hadoop
hadoop-env.sh
export JAVA_HOME=/usr/opt/jdk1..0_79/
core-site.xml, 配置NN所在的主机和数据传输端口(rpc协议)
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.208.126:9000</value>
</property>
<!--配置缓存目录, 因为fsimage默认在此目录下, 所以更改-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop</value>
</property>
hdfs-site.xml, 配置的为secondNameNode
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hdfs-dnn:</value>
</property>
<property>
<name>dfs.namenode.secondary.https-address</name>
<value>hdfs-dnn:</value>
</property>
slaves
hdfs-dnn1
hdfs-dnn2
hdfs-dnn3
masters 自己创建, 配置SNN的主机名
hdfs-dnn1
之后, 将整个hadoop文件scp到DNN主机上
5, 配置hadoop的环境变量 /etc/profile
export JAVA_HOME=/usr/opt/jdk1..0_79
export PATH=$PATH:$JAVA_HOME/bin export HADOOP_HOME=/usr/opt/hadoop-2.5.
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
6, 启动
6.1) 格式化NN, 在 HADOOP_HOME/dfs/name/current/ 下生成fsimage文件
hdfs namenode -format
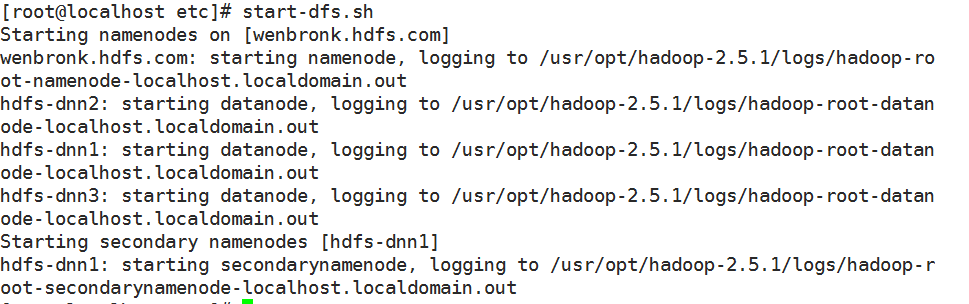
6.2) 启动
start-dfs.sh
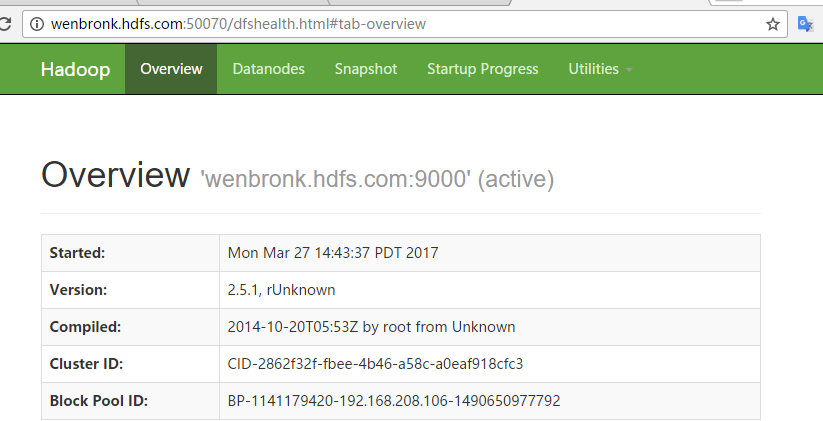
然后通过浏览器可以访问监控页面,
命令行示例:
1) 从本地磁盘拷贝文件
hdfs dfs -put foo.txt foo.txt
hdfs 没有当前目录的概念, 必须从用户的home路径下, /usr/username/foot.txt # 从hdfs拷贝
hdfs dfs -get /user/fred/bar.txt baz.txt
2) 获取用户home目录列表
hdfs dfs -ls
访问根目录, 直接 /
3) 显示hdfs文件 /user/fred/bar.txt
hdfs dfs -cat /user/fred/bar.txt
4), 在用户目录下创建input目录
hdfs dfs -mkdir input
5) , 删除目录
hdfs dfs -rm -r input-old
系列来自尚学堂
10-hdfs-hdfs搭建的更多相关文章
- 10分钟学会搭建Android开发环境 Eclipse: The import android.support cannot be resolved
10分钟学会搭建Android开发环境_隋雨辰 http://v.youku.com/v_show/id_XNTE2OTI5Njg0.html?from=s1.8-1-1.2 The import a ...
- DELPHI 10.2 TOKYO搭建LINUX MYSQL开发环境
DELPHI 10.2 TOKYO搭建LINUX MYSQL开发环境 笔者使用ubuntu64位LINUX 首先必须保证LINUX可以连互联网. 安装MYSQLsudo apt-get update ...
- 【Hadoop学习之四】HDFS HA搭建(QJM)
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 由于NameNode对于整个HDF ...
- flume-ng+Kafka+Storm+HDFS 实时系统搭建
转自:http://www.tuicool.com/articles/mMrQnu7 一 直以来都想接触Storm实时计算这块的东西,最近在群里看到上海一哥们罗宝写的Flume+Kafka+Storm ...
- [转]flume-ng+Kafka+Storm+HDFS 实时系统搭建
http://blog.csdn.net/weijonathan/article/details/18301321 一直以来都想接触Storm实时计算这块的东西,最近在群里看到上海一哥们罗宝写的Flu ...
- Hadoop 笔记1 (原理和HDFS分布式搭建)
1. hadoop 是什么 以及解决的问题 (自行百度) 2.基本概念的讲解 1. NodeName master 节点(NN) 主节点 保存了metaData(元数据信息) 包括文件的owener ...
- HDFS环境搭建(单节点配置)
[参考文章]:hadoop集群搭建(hdfs) 1. Hadoop下载 官网下载地址: https://hadoop.apache.org/releases.html,进入官网根据自己需要下载具体的安 ...
- hadoop3自学入门笔记(2)—— HDFS分布式搭建
一些介绍 Hadoop 2和Hadoop 3的端口区别 Hadoop 3 HDFS集群架构 我的集群规划 name ip role 61 192.168.3.61 namenode,datanode ...
- hadoop3.1.0 HDFS快速搭建伪分布式环境
1.环境准备 CenntOS7环境 JDK1.8-并配置好环境变量 下载Hadoop3.1.0二进制包到用户目录下 2.安装Hadoop 1.解压移动 #1.解压tar.gz tar -zxvf ha ...
- Hadoop HDFS环境搭建
1,首先安装JDK,下面如果JDK出现安装错误,可以卸载 卸载 1.卸载用 bin文件安装的JDK方法: 删除/usr/java目录下的所有东西 2.卸载系统自带的jdk版本方法: 查看自带的jdk: ...
随机推荐
- PAT甲 1032. Sharing (25) 2016-09-09 23:13 27人阅读 评论(0) 收藏
1032. Sharing (25) 时间限制 100 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 CHEN, Yue To store Engl ...
- HDU1241 Oil Deposits 2016-07-24 13:38 66人阅读 评论(0) 收藏
Oil Deposits Problem Description The GeoSurvComp geologic survey company is responsible for detectin ...
- 深浅 buffer
var str = "深入浅出"; var buf = new Buffer(str, 'utf-8'); console.log(buf); 这种情况下是数字 var str = ...
- KbmMW安装
系统环境及相关软件版本: Windows 7 64位, Delphi XE Version 15.0.3953.35171 , Indy 10.5.7 kbmMW4.90.04 , kbmMemTab ...
- Android-Java-进程与线程
1.进程:什么是进程: Mac操作系统,Windows操作系统 ...... 等等,都是由多个进程来运行(系统进程,普通进程,等) 操作系统最小的控制单元是进程,一个应用就是一个进程 进程 全称为:操 ...
- Java动态绑定与静态绑定
Java动态绑定来自于继承体现,子类继承父类,子类重新覆盖了父类的方法,就是动态绑定,以下举例: (动态绑定是在运行期间) 动物类: /** * 创建一个动物类 * @author Liudeli * ...
- 关于ListBox的几个问题
Winfrom ListBox绑定数据源list界面不更新问题与绑定数据源不可CRUD问题 场景:获取一个listbox的选中项添加到另一个listbox中 解决方案-1:不要直接绑定DataSour ...
- 如何将Jenkins multiline string parameter的多行文本优雅的保存为文件
[现象]: 使用multi-line string parameter获取的文本变量,在jenkins shell里面显示为单行文本(空格分割). [问题]:能否转换为多行文本,并存入文件. [解决方 ...
- Python 数据结构与算法——链表
#构造节点类 class Node(object): def __init__(self,data=None,_next=None): ''' self.data:为自定义的数据 self.next: ...
- 安装webpack常见错误之一
我安装webpack时,出现如下错误: C:\Users\admin> npm install webpack -gnpm WARN checkPermissions Missing write ...