scrapy简单入门及选择器(xpath\css)
简介
scrapy被认为是比较简单的爬虫框架,资料比较齐全,网上也有很多教程。官网上介绍了它的四种安装方法,PyPI、Conda、APT、Source,我们只介绍最简单的安装方法。
安装
Windows下的安装
pip install scrapy
Linux下的安装
apt-get install python-scrapy
APT
vim编辑器
因为Linux的强大及辅助工具比较多,大家比较喜欢在Linux下使用scrapy爬虫框架,Linux下编写python代码最强大的工具可属eclipse,但最方便的要属vi的强化版本vim了,对不同的编程语言配合不同的插件,可将vim配置成为一个专属的IDE。
VIM模块
选择器XPath和CSS
XPath是一门在XML文档中查找信息的语言,可用来在XML文档中对元素和属性进行遍历。它有七点类型的节点:元素、属性、文本、命名空间、处理指令、注释及文档节点(根节点),XML文档是被作为节点树来对待的,树的根被称为根节点。
XPath使用路径表达式在XML文档中选取节点。
XPath最常用的路径表达式:
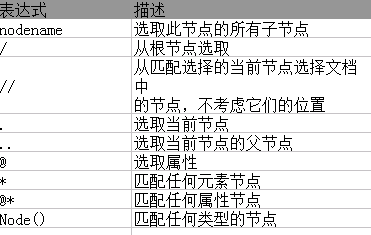
xpath示例代码
<?xml version="1.0" encoding="ISO-8859-1"?> <bookstore> <book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book> <book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book> </bookstore>
举例说明:
bookstore 选取bookstore元素的所有子节点
/bookstore 选择根元素下的bookstore元素,假如路径起始于/
bookstore/book 选取bookstoe的所有子元素中为book的元素
//book 选取文档中的所有book元素,不管它在什么位置
//bookstore//book 选择属于bookstore元素后代的所有book元素,不管它在什么位置
//@lang 选择所有属性为lang的元素
/bookstore/book[] 选取bookstore子元素中的第一个book元素
/bookstore/book[last()] 选取bookstore子元素中的最后一个book元素
/bookstore/book[last()-] 选取bookstore子元素中倒数第二个book元素
/bookstore/book[postion()<] 选取bookstore子元素中前两个book元素
//title[@lang] 选取所有title元素且其属性拥有lang名
//title[@lang='en'] 选取所有title元素且其属性拥有lang='en'
/bookstore/book[price>] 选取bookstore元素下所有子元素中元素price>30book的元素
/title/text() 提取title标签上的文字
/a/@href 提取a标签的href属性值
response.xpath("//a[contains(.,'下一页')]/text()")[1].extract() # 根据文本内容查找
未知节点
* 任何元素节点
@* 任何属性节点 /bookstore/* bookstore元素下的所有子元素
//* 当前文档的所有元素
//title[@*] 所有带有属性的title元素
选取若干路径
//book/title|//book/price 选取book元素下的所有title和price元素
//title|//price 选取文档中的所有title和price元素
示例代码2:
<superhero>
<class>
<name lang="en">Tony Stark</name>
<alias>Iron Man</alias>
<sex>male</sex>
<birthday></birthday>
<age></age>
</class>
<class>
<name lang="en">Perter Benjamin</name>
<alias>Spider Man</alias>
<sex>male</sex>
<birthday>unknow</birthday>
<age>unknow</age>
</class>
<class>
<name lang="en">Steven Rogers</name>
<alias>Captain America</alias>
<sex>male</sex>
<birthday></birthday>
<age></age>
</class>
</superhero>
分析以上代码:superhero是根节点,alias是元素节点,lang="en"是属性节点。
小试牛刀
#!/usr/bin/env python
# _*_ coding:utf-8 _*_ from scrapy.selector import Selector with open("superHero.xml",'r') as fp:
body = fp.read() htmlContent = Selector(text=body).xpath("/*").extract()
print htmlContent
结果:XML文件转成了标准的HTML文件,根节点不再是superhero而是html
数据收集的比较
#!/usr/bin/env python
# _*_ coding:utf- _*_ from scrapy.selector import Selector with open("superHero.xml",'r') as fp:
body = fp.read() # 采集第一个class节点中的内容,text表示传入的内容是字符串
Selector(text=body).xpath("//superhero/class[0]").extract()
Selector(text=body).css("superhero class:first-child").extract() # 采集最后一个class节点中的内容
Selector(text=body).xpath("//superhero/class[last()]").extract()
Selector(text=body).css("superhero class:last-child").extract() # 采集倒数第二个class节点中name节点的文本,text()表示获取文本
Selector(text=body).xpath("//superhero/class[last()-1]/name/text()").extract()
Selector(text=body).css("superhero class:nth-last-child(2) name").extract()[] # 采集节点name,其属性节点lang='en'的元素,@前缀代表属性名称(@lang代表lang属性,用中括号圈起来)
Selector(text=body).xpath("//name[@lang='en']").extract()
Selector(text=body).css("name[lang='en']").extract() # 嵌套选择器,选择最后一个class节点中sex节点的内容
subBody = Selector(text=body).xpath("//superhero/class[last()]").extract()
Selector(text=subBody[]).xpath("/html/body/class/sex/text()").extract()
Selector(text=subBody[]).xpath("//class/sex/text()").extract()
CSS:层叠样式表
CSS经常使用的几个选择器:

css也可以嵌套使用,所以它和xpath可以互相嵌套,使用数据收集功能更加强大。
CSS示例代码(同示例代码2):
s.css("title::text").extract_first() # 提取title标签的文本
s.css("base::attr(href)").extract_first() # 提取base标签的herf属性值
s.css("a[href^=image]::attr(href)").extract() # 提取以image开头的属性列表
s.xpath('//a[contains(@href, "image")]/@href').extract() # href属性中包含image字符串列表
s.css('a[href^=image]::text').re(r'Name:\s(.*)') # 正则也可以序列化数据,返回括号中的文本串
好,scrapy的基本情况已经介绍完了,下面来尝试通过使用模板的方式来创建一个爬虫吧。
1、创建一个目录用来存放所有的爬虫工程
$mkdir -p code/crawler/scrapyProject
2、在工程目录下创建首个爬虫工程
cd code/crawler/scrapyProject/
scrapy startproject todayMovie

3、为此工程创建爬虫程序
$ scrapy genspider wuHanMoiveSpider jycimima.com --force
4、使用tree命令查看此工程目录
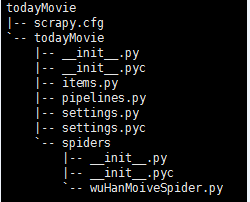
第一级todayMovie:此工程名称
第二级todayMovie: 此工程模块,存放此工程所有的爬虫代码
scrapy.cfg: 此工程的全局配置文件
items.py: 定义了一个类,存放爬虫最终爬取的项目,数据最终以字典的形式表现,键值为列表。
wuHanMoiveSpider.py: 真正的爬虫程序,用来爬取网页内容,并生成item数据。
settings.py:配置由谁去处理爬取的item数据。
piplines.py: 逐条处理爬取的item数据。
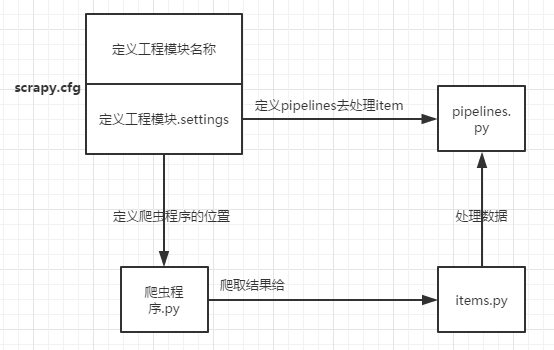
5、scrapy框架流程图:
scrapy简单入门及选择器(xpath\css)的更多相关文章
- [转]Scrapy简单入门及实例讲解
Scrapy简单入门及实例讲解 中文文档: http://scrapy-chs.readthedocs.io/zh_CN/0.24/ Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用 ...
- Scrapy简单入门及实例讲解
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以 ...
- Scrapy简单入门及实例讲解-转载
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以 ...
- 10,Scrapy简单入门及实例讲解
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以 ...
- scrapy 框架入门
运行流程 官网:https://docs.scrapy.org/en/latest/intro/overview.html 流程图如下: 组件 1.引擎(EGINE):负责控制系统所有组件之间的数据流 ...
- Python中Scrapy框架元素选择器XPath的简单实例
原文标题:<Python网络爬虫-Scrapy的选择器Xpath> 对原文有所修改和演绎 优势 XPath相较于CSS选择器,可以更方便的选取 没有id class name属性的标签 属 ...
- CSS选择器 + Xpath + 正则表达式整理(有空再整理)
选择器 例子 例子描述 CSS .class .intro 选择 class="intro" 的所有元素. 1 #id #firstname 选择 id="firstna ...
- scrapy爬虫学习系列二:scrapy简单爬虫样例学习
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- Scrapy爬虫入门系列2 示例教程
本来想爬下http://www.alexa.com/topsites/countries/CN 总排名的,但是收费了 只爬了50条数据: response.xpath('//div[@class=&q ...
随机推荐
- Android 开发工具类 06_NetUtils
跟网络相关的工具类: 1.判断网络是否连接: 2.判断是否是 wifi 连接: 3.打开网络设置界面: import android.app.Activity; import android.cont ...
- 关于作用域范围Scope
举个例子,如下: public class C { public int a = 2; public void test(int b) { int c = 3; for (int d = 3; a & ...
- Go语言学习笔记十一: 切片(slice)
Go语言学习笔记十一: 切片(slice) 切片这个概念我是从python语言中学到的,当时感觉这个东西真的比较好用.不像java语言写起来就比较繁琐.不过我觉得未来java语法也会支持的. 定义切片 ...
- activiti 临时笔记mark
public class TenMinuteTutorial { public static void main(String[] args) { // Create Activiti process ...
- Node.js数据流Stream之Readable流和Writable流
一.前传 Stream在很多语言都会有,当然Node.js也不例外.数据流是可读.可写.或即可读又可写的内存结构.Node.js中主要包括Readable.Writable.Duplex(双工)和Tr ...
- 下拉框多选实现回显及sql
<td class="tabTd"><label>客户来源:</label></td> <td><select c ...
- C#中深拷贝和浅拷贝
一:概念 内存:用来存储程序信息的介质. 指针:指向一块内存区域,通过它可以访问该内存区域中储存的程序信息.(C#也是有指针的) 值类型:struct(整形.浮点型.decimal的内部实现都是str ...
- SpringMVC中properties文件读取
SpringMVC给我们提供了用于properties文件读取的类: org.springframework.context.support.ResourceBundleMessageSource 1 ...
- 关于JavaScript线程的讲解
讲述js执行的相关线程.DOM操作等问题.参考博客:http://www.codeceo.com/article/javascript-threaded.html
- 微信小程序,关于设置data里面的数据。
关于设置 data里面的数据 wxml: <view>{{userName}}</view> data: { userName:'张三', } 有两种方法 方法一:直接使用点关 ...