机器学习(一):记一次k一近邻算法的学习与Kaggle实战
本篇博客是基于以Kaggle中手写数字识别实战为目标,以KNN算法学习为驱动导向来进行讲解。
写这篇博客的原因
写下这篇博客,很大程度上是希望能记录和督促自己学习机器学习的过程,同时也在以后的学习生活中,可以将以前的博客翻来看看,重新回顾知识。
什么是KNN?
在模式识别和机器学习中,k-近邻算法(以下简称:KNN)是一种常用的监督学习中分类方法。KNN可以说是机器学习算法中最简单的一个算法,我希望它能带领大家走进机器学习,了解其中最基本的原理,并应用于实际生活中。KNN的工作机制非常简单,它是一种处理分类和回归问题的无参算法,简而言之就是通过某种距离度量,计算出测试集与训练集之间的距离,选取前k个最近距离的训练样本,从这k个中选出训练样本中出现最多的类型来作为测试样本的类型。
k-近邻算法的一般流程 :
(1)收集数据:可以使用任何方法。
(2)准备数据:格式化数据格式。
(3)分析数据:可以使用任何方法。
(4)训练算法:K-近邻算法不涉及训练。
(3)测试算法:计算错误率。
(3)使用算法:输入样本数据,进行分类。
名词解释与案例分析:
以手写数字识别为例进行说明:
训练集:一组有标签的数字图像,即每张图片,我们都对它进行了标注,表明这张图片所显示的数字是多少。在本案例中,所有的图片都是以矩阵的形式保存在数据集中。
测试集:一组没有标签的数字图像,即给出了一组图片,但是并没有对它进行标注,即它的类型是什么,我们也不清楚。
分类:比如手写数字识别中,给出一张图片,我们可以清楚的分辨,上面所写的数字,但是计算机,并不能有效的识别出来,因此机器学习的一个应用便是让计算机从已知分类情况,推断未知情况的类别。
回归:拿函数来说,一个函数在图像上是连续,且有一定规律的时候,我们可以通过函数去算出未知的情况。计算机就是通过已知情况,然后模拟生成一个函数,去拟合这样一个模型,从而推断出未知的情况。
距离度量:欧式距离、曼哈顿距离、切比雪夫距离。
样本:在本篇博客中,每个样本就是一张数字图片,测试集中的样本集,即每一张测试样本都是没有分类的。而训练集中的样本集,都是有明确的分类。
这里,博主只是使用了最基本的KNN算法进行手写数字识别,通过计算欧式距离,达到计算机对手写数字识别和分类。
kaggle实战
在Kaggle中,有一场比赛是knowledge类型的。嗯,就决定是你了!
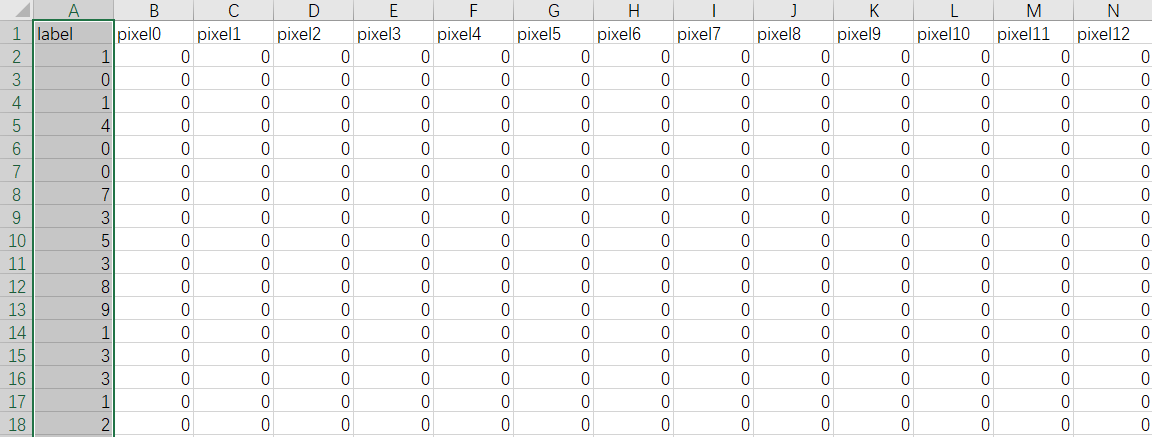
首先从Kaggle中下载训练集及测试集。点开训练集,可以看见训练集是由42000张数字图片组成,我们可以将它转换为一个420001的标签矩阵和一个42000784的像素矩阵。(注:normaling函数和toInt函数是对返回的数据进行格式化。后面会对函数进行说明。)

# 读取Train数据
def loadTrainData():
filename = 'train.csv'
with open(filename, 'r') as f_obj:
f = [x for x in csv.reader(f_obj)]
f.remove(f[0])
f = array(f)
labels = f[:,0]
datas = f[:,1:]
# print(shape(labels))
return normaling(toInt(datas)), toInt(labels)
打开测试集。因为测试集并没有分类,因此并没有标签。所以可以将这个测试集转换为28000*784的像素矩阵。


#读取Test数据
def loadTestData():
filename = 'test.csv'
with open(filename, 'r') as f_obj:
f = [x for x in csv.reader(f_obj)]
f.remove(f[0])
f = array(f)
return normaling(toInt(f))
前面提到的normaling函数是为了将数据集进行归一化,归一化的目的是为了解决数据指标之间的可比性,防止某些数据过大,导致分类结果的偏差较大。
#归一化数据
def normaling(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
m = dataSet.shape[0]
denominator = tile(ranges, (m, 1))
molecular = dataSet - tile(minVals, (m, 1))
normData = molecular / denominator
return normData
而toInt函数是因为从csv文件中得到的数据都是字符串类型,但是测算距离度量是对于数值类型的,因此需要将字符串类型转换为数值类型。
#字符串数组转换整数
def toInt(array):
array = mat(array)
m, n =shape(array)
newArray = zeros((m, n))
for i in range(m):
for j in range(n):
newArray[i,j] = int(array[i,j])
return newArray
那么KNN算法的核心就是通过计算测试集中每一个测试样本与训练集的距离,选取与测试集最近的k个训练样本,再从这k个样本中,选取出现最多的类型作为训练样本的类别。因此计算测试样本和训练集之间的距离如下面代码所示:
# 核心代码
def k_NN(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize, 1)) - dataSet
sqDiffMat = diffMat**2
sqDistance = sqDiffMat.sum(axis=1)
distances = sqDistance**0.5
sortDisn = argsort(distances)
# print("sortDisn shape: ",sortDisn.shape)
# print("labels shape:",labels.shape)
classCount = {}
for i in range(k):
# print(sortDisn[i])
# print(type(sortDisn[i]))
vote = labels[sortDisn[i]]
# print("before :",type(vote))
vote = ''.join(map(str, vote))
# print("after :", type(vote))
classCount[vote] = classCount.get(vote, 0) + 1
sortedD = sorted(classCount.items(), key=operator.itemgetter(1),
reverse=True)
return sortedD[0][0]
将以上的代码进行整合,即可把测试集的数据进行分类。
#!/user/bin/python3
# -*- coding:utf-8 -*-
#@Date :2018/6/30 19:35
#@Author :Syler
import csv
from numpy import *
import operator
# 核心代码
def k_NN(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize, 1)) - dataSet
sqDiffMat = diffMat**2
sqDistance = sqDiffMat.sum(axis=1)
distances = sqDistance**0.5
sortDisn = argsort(distances)
# print("sortDisn shape: ",sortDisn.shape)
# print("labels shape:",labels.shape)
classCount = {}
for i in range(k):
# print(sortDisn[i])
# print(type(sortDisn[i]))
vote = labels[sortDisn[i]]
# print("before :",type(vote))
vote = ''.join(map(str, vote))
# print("after :", type(vote))
classCount[vote] = classCount.get(vote, 0) + 1
sortedD = sorted(classCount.items(), key=operator.itemgetter(1),
reverse=True)
return sortedD[0][0]
#读取Train数据
def loadTrainData():
filename = 'train.csv'
with open(filename, 'r') as f_obj:
f = [x for x in csv.reader(f_obj)]
f.remove(f[0])
f = array(f)
labels = f[:,0]
datas = f[:,1:]
# print(shape(labels))
return normaling(toInt(datas)), toInt(labels)
#读取Test数据
def loadTestData():
filename = 'test.csv'
with open(filename, 'r') as f_obj:
f = [x for x in csv.reader(f_obj)]
f.remove(f[0])
f = array(f)
return normaling(toInt(f))
#归一化数据
def normaling(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
m = dataSet.shape[0]
denominator = tile(ranges, (m, 1))
molecular = dataSet - tile(minVals, (m, 1))
normData = molecular / denominator
return normData
#字符串数组转换整数
def toInt(array):
array = mat(array)
m, n =shape(array)
newArray = zeros((m, n))
for i in range(m):
for j in range(n):
newArray[i,j] = int(array[i,j])
return newArray
#保存结果
def saveResult(res):
with open('res.csv', 'w', newline='') as fw:
writer = csv.writer(fw)
writer.writerows(res)
if __name__ == '__main__':
dataSet, labels = loadTrainData()
testSet = loadTestData()
row = testSet.shape[0]
# print("dataSet Shape:",dataSet.shape)
# print("labels Shape before",shape(labels))
labels = labels.reshape(labels.shape[1],1)
# print("labels Shape after reshape ", shape(labels))
# print("testSet Shape",testSet.shape)
resList = []
for i in range(row):
res = k_NN(testSet[i], dataSet, labels, 4)
resList.append(res)
print(i)
saveResult(resList)
那么把这个数据结果提交到Kaggle上,结果如何呢?


总的来说,这次结果还是很满意的。毕竟KNN算法算是机器学习算法中比较基础的一个算法,能够达到97.185%的准确率,且有66%的排名已经算是很不错的啦~
优点:
简单、易于理解,易于实现,无需训练。
适合对稀有事件进行分类。
特别使用于多分类问题,KNN比SVM的表现更好。
缺点:
KNN算法是基于实例的学习或者说是一种“懒惰学习”。使用算法的时候,我们必须有尽量接近实际数据的训练样本数据,这很大程度是因为它并没有训练模型这样一个步骤,导致它必须保存所有数据集。一旦数据集很大,将导致大量的存储空间。而且加上每次对样本的分类或回归,都要对数据集中每个数据计算距离值,实际使用会非常耗时。其次,它受“噪声”影响很大,尤其是样本不平衡的时候,会导致分类的结果偏差很大。加上它的另一个缺陷是无法给出任何数据的基础结构信息,并不能知道测试集与训练集之间具有什么特征。
优化方法
现在KNN算法的改进主要分成分类效率和分类效果两方面。
一种流行的增加精准率的方法是使用进化算法去优化特征范围。
另一种则是通过各种启发式算法,去选取一个适合的K值。
不管是分类还是回归,都是根据距离度量来进行加权,使得邻近值更加平均。
总结
KNN算法对于分类数据是最简单最有效的算法,它能帮助我们迅速了解监督学习中的分类算法的基本模型。
参考
Github地址:https://github.com/578534869/machine-learning
(欢迎follow,互相学习,共同进步!
机器学习(一):记一次k一近邻算法的学习与Kaggle实战的更多相关文章
- 机器学习之K近邻算法(KNN)
机器学习之K近邻算法(KNN) 标签: python 算法 KNN 机械学习 苛求真理的欲望让我想要了解算法的本质,于是我开始了机械学习的算法之旅 from numpy import * import ...
- 机器学习03:K近邻算法
本文来自同步博客. P.S. 不知道怎么显示数学公式以及排版文章.所以如果觉得文章下面格式乱的话请自行跳转到上述链接.后续我将不再对数学公式进行截图,毕竟行内公式截图的话排版会很乱.看原博客地址会有更 ...
- [机器学习] k近邻算法
算是机器学习中最简单的算法了,顾名思义是看k个近邻的类别,测试点的类别判断为k近邻里某一类点最多的,少数服从多数,要点摘录: 1. 关键参数:k值 && 距离计算方式 &&am ...
- 机器学习之路:python k近邻回归 预测波士顿房价
python3 学习机器学习api 使用两种k近邻回归模型 分别是 平均k近邻回归 和 距离加权k近邻回归 进行预测 git: https://github.com/linyi0604/Machine ...
- 机器学习:k-NN算法(也叫k近邻算法)
一.kNN算法基础 # kNN:k-Nearest Neighboors # 多用于解决分裂问题 1)特点: 是机器学习中唯一一个不需要训练过程的算法,可以别认为是没有模型的算法,也可以认为训练数据集 ...
- 【机器学习】k近邻算法(kNN)
一.写在前面 本系列是对之前机器学习笔记的一个总结,这里只针对最基础的经典机器学习算法,对其本身的要点进行笔记总结,具体到算法的详细过程可以参见其他参考资料和书籍,这里顺便推荐一下Machine Le ...
- 机器学习(四) 分类算法--K近邻算法 KNN (上)
一.K近邻算法基础 KNN------- K近邻算法--------K-Nearest Neighbors 思想极度简单 应用数学知识少 (近乎为零) 效果好(缺点?) 可以解释机器学习算法使用过程中 ...
- 机器学习(1)——K近邻算法
KNN的函数写法 import numpy as np from math import sqrt from collections import Counter def KNN_classify(k ...
- 机器学习之K近邻算法
K 近邻 (K-nearest neighbor, KNN) 算法直接作用于带标记的样本,属于有监督的算法.它的核心思想基本上就是 近朱者赤,近墨者黑. 它与其他分类算法最大的不同是,它是一种&quo ...
随机推荐
- mysql测试数据创建
用存储过程方式创建几十几百万条测试数据,2核4G里插入1万条,约8.5秒,也就是24小时可以加大约1亿条记录. //创建库,用户create database dbTest;create user ' ...
- c++——this指针
实验1:若类成员函数的形参 和 类的属性,名字相同,通过this指针来解决. 实验2:类的成员函数可通过const修饰,请问const修饰的是谁 #include <iostream> u ...
- git 代码分支合并merge提交新修改远程以及本地分支
第一步:创建本地分支 点击右键选择TortoiseGit,选择Create Branch…,在Branch框中填写新分支的名称(若选中”switch to new branch”则直接转到新分支上,省 ...
- 使用java发送QQ邮件的总结
最近帮朋友做个网站,实现用邮箱订阅功能,所以现在把这个发送邮件的功能放在这里,算是这两天工作的总结吧! 首先,想要实现订阅功能,要把邮箱保存,但是这个做的是个小网站,前后台交互的太少了,所以我就直接保 ...
- 记录一下安装 mysql 的踩坑之路
坑点: 1.旧的mysql没有删除干净.在安装mysql的时候,没有注意到,在输入 “mysqld install” 指令时跳出来 exits,存在于另一个文件夹之中,这影响了后来的很多操作,包括ro ...
- day 86 Vue学习之五DIY脚手架、webpack使用、vue-cli的使用、element-ui
本节目录 一 vue获取原生DOM的方式 二 DIY脚手架 三 vue-cli脚手架的使用 四 webpack创建项目的玩法 五 element-ui的使用 六 xxx 七 xxx 八 xxx 一 ...
- docker 下 mysql 集群的搭建
下载程序&&创建docker容器 从mysql官网https://dev.mysql.com/downloads/cluster/上下载mysql集群库mysql-cluster-gp ...
- HTTP性能测试工具wrk安装及使用
wrk 是一个很简单的 http 性能测试工具,没有Load Runner那么复杂,他和 apache benchmark(ab)同属于HTTP性能测试工具,但是比 ab 功能更加强大,并且可以支持l ...
- 批量生成文件夹内所有文件md5
说明:md5批量生成批处理脚本,无需安装任何软件,直接调用系统文件进行生成,简单基于windows命令编写了一个批量生成md5值的脚本. 使用说明:新建文本文档,命名为get_md5.bat,直接将代 ...
- UWP 播放直播流 3MU8
UWP 播放直播流 3MU8 参考:http://www.c-sharpcorner.com/UploadFile/2b876a/http-live-streaming-in-windows-10-u ...